Python文本分析:2016年政府工作报告有哪些高频词?
本文首发于 微信公众号号“编程派” 。微信搜索“编程派”,获取更多Python编程一手教程及优质资源吧。
上周六,总理在大会堂作政府工作报告,全球媒体瞩目。每年都会有媒体对报告中的高频词汇进行梳理,我们也可以尝试利用Python和分词工具jieba来自己分析一下。
我们首先来看国内部分媒体的梳理结果。据小编简单了解,已知对工作报告高频词汇进行梳理的媒体包括法制日报和新华网。
国内媒体梳理的高频词
下面是 法制日报公布的十大高频词 。
| 高频词 | 词频 | 1978年以来政府工作报告中的提及总数 |
|---|---|---|
| 发展 | 151 | 4828 |
| 经济 | 90 | 4449 |
| 改革 | 74 | 2758 |
| 建设 | 71 | 3274 |
| 社会 | 66 | 3402 |
| 推进 | 61 | 1096 |
| 创新 | 61 | 414 |
| 政策 | 52 | 1231 |
| 企业 | 48 | 2304 |
| 加强 | 41 | 2238 |
下面是 新华网数据新闻部统计的高频词汇 。

新华网的信息图其实有些含糊不清,有些词频不知道到底是2016年还是2015年的,但这里并不是我们关注的重点。
另外,新华网和法制日报得出的数据似乎有些出入,虽然并不大。那么,到底那家的数据是准确的呢?
接下来,我们就自己来计算一下报告中的高频词汇吧。
准备工作
我们需要从网上爬取政府报告的全文,这里小编选择 中国政府网发布的报告页面 。为此,我们需要安装requests和BeautifulSoup4这两个常用第三方库。
pip install requests beautifulsoup
获取了报告文本之后,接下来需要对文本进行分词。我们选择号称“做最好的中文分词组件”的 jieba中文分词库 。
pip install jieba
这里提示一下,这三个库都支持Python 2和Python 3。但是在Python 2下,很容易就碰到编码问题,最后打印出的中文无法正常显示。因此,建议使用Python 3执行该脚本。
安装好依赖包之后,我们在脚本 analyze_report.py 的顶部导入它们。
import jieba import requests from bs4 import BeautifulSoup
文本提取
首先,我们从网上抓取政府工作报告的全文。我将这个步骤封装在一个名叫 extract_text 的简单函数中,接受url作为参数。因为目标页面中报告的文本在所有的p元素中,所以我们只需要通过BeautifulSoup选中全部的p元素即可,最后返回一个包含了报告正文的字符串,简单粗暴!
def extract_text(url): """Extract html content.""" page_source = requests.get(url).content bs_source = BeautifulSoup(page_source) report_text = bs_source.find_all('p') text = '' for p in report_text: text += p.get_text() text += '/n' return text 利用jieba分词,并计算词频
然后,我们就可以利用jieba进行分词了。这里,我们要选择全模式分词。jieba的全模式分词,即把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义。之所以这么做,是因为默认的精确模式下,返回的词频数据不准确。
分词时,还要注意去除标点符号,由于标点符号的长度都是1,所以我们添加一个len(word) >= 2的条件即可。
最后,我们就可以利用Counter类,将分词后的列表快速地转化为字典,其中的键值就是键的出现次数,也就是这个词在全文中出现的次数啦。
def word_frequency(text): from collections import Counter words = [word for word in jieba.cut(text, cut_all=True) if len(word) >= 2] c = Counter(words) for word_freq in c.most_common(10): word, freq = word_freq print(word, freq)
执行脚本
两个函数都写好之后,我们就可以愉快地执行啦。
url_2016 = 'http://www.gov.cn/guowuyuan/2016-03/05/content_5049372.htm' text_2016 = extract_text(url_2016) word_frequency(text_2016)
最后的结果如下:
| 高频词 | 次数 |
|---|---|
| 发展 | 152 |
| 经济 | 90 |
| 改革 | 76 |
| 建设 | 71 |
| 社会 | 67 |
| 推进 | 62 |
| 创新 | 61 |
| 政策 | 54 |
| 企业 | 48 |
| 服务 | 44 |
小结
从上面的结果可以看出,新华网发布的高频词统计数据与我们自己的分析最为接近。当然,新华网的里面少了一个高频词:推进。
如果有朋友想要验证结果的话,可以自己把报告全文复制到word里,然后查询下相关的高频词即可,比如下面这样:
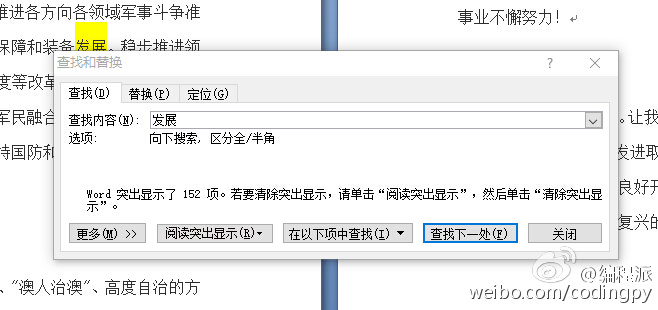
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

