Machine Learning With Spark Note 1:数据基本处理
本文为数盟特约作者投稿,欢迎转载,请注明出处“数盟社区”和作者
博主简介:段石石,1号店精准化推荐算法工程师,主要负责1号店用户画像构建,喜欢钻研点Machine Learning的黑科技,对Deep Learning感兴趣,喜欢玩kaggle、看9神,对数据和Machine Learning有兴趣咱们可以一起聊聊
接入公共数据库
很用于机器学习模型的数据库有很多,包括:
- UCI机器学习源:http://archive.ics.uci.edu/ml/
- Amazon AWS公共数据集:http://aws.amazon. com/publicdatasets/
- Kaggle:http://www.kaggle.com/competitions
- KDnuggets:http://www.kdnuggets.com/datasets/index.html
在本章中,我们使用一个经典的电影数据集MovieLens(http://files.grouplens.org/datasets/ movielens/ml-100k.zip)
了解数据
下载MovieLens数据集:

解压,检查下数据格式:
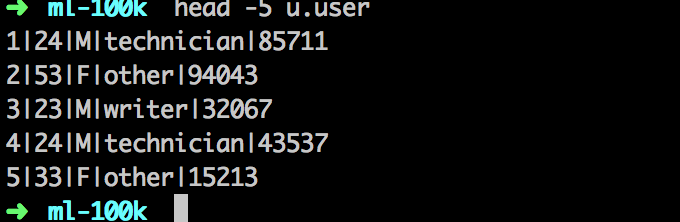

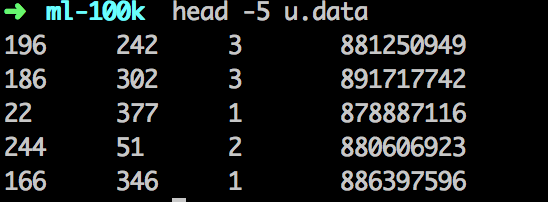
u.user存储用户基本信息,u.item存储电影基本信息,u.data存储user_id,movie_id,rating,timestamp信息。
使用Python notebook看看用户数据
将数据拷到对应路径
Python
user_data = sc.textFile('../data/ML_spark/MovieLens/u.user') user_data.first() user_data = sc.textFile('../data/ML_spark/MovieLens/u.user') user_data.first() 
计算数据当中的基本信息,比如用户总数、性别总数(应该是2吧)、职业数、zip数目:
Python
user_fields = user_data.map(lambda line: line.split('|')) num_users = user_fields.map(lambda fields: fields[0]).count() = user_fields.map(lambda fields : fields[2]).distinct().count() num_occupations = user_fields.map(lambda fields: fields[3]).distinct().count() num_zipcodes = user_fields.map(lambda fields: fields[4]).distinct().count() print "Users: %d, genders: %d, occupations: %d, ZIP codes: %d"%(num_users,num_genders,num_occupations,num_zipcodes) user_fields = user_data.map(lambda line: line.split('|')) num_users = user_fields.map(lambda fields: fields[0]).count() = user_fields.map(lambda fields : fields[2]).distinct().count() num_occupations = user_fields.map(lambda fields: fields[3]).distinct().count() num_zipcodes = user_fields.map(lambda fields: fields[4]).distinct().count() print "Users: %d, genders: %d, occupations: %d, ZIP codes: %d"%(num_users,num_genders,num_occupations,num_zipcodes) 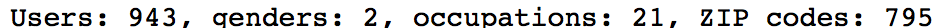
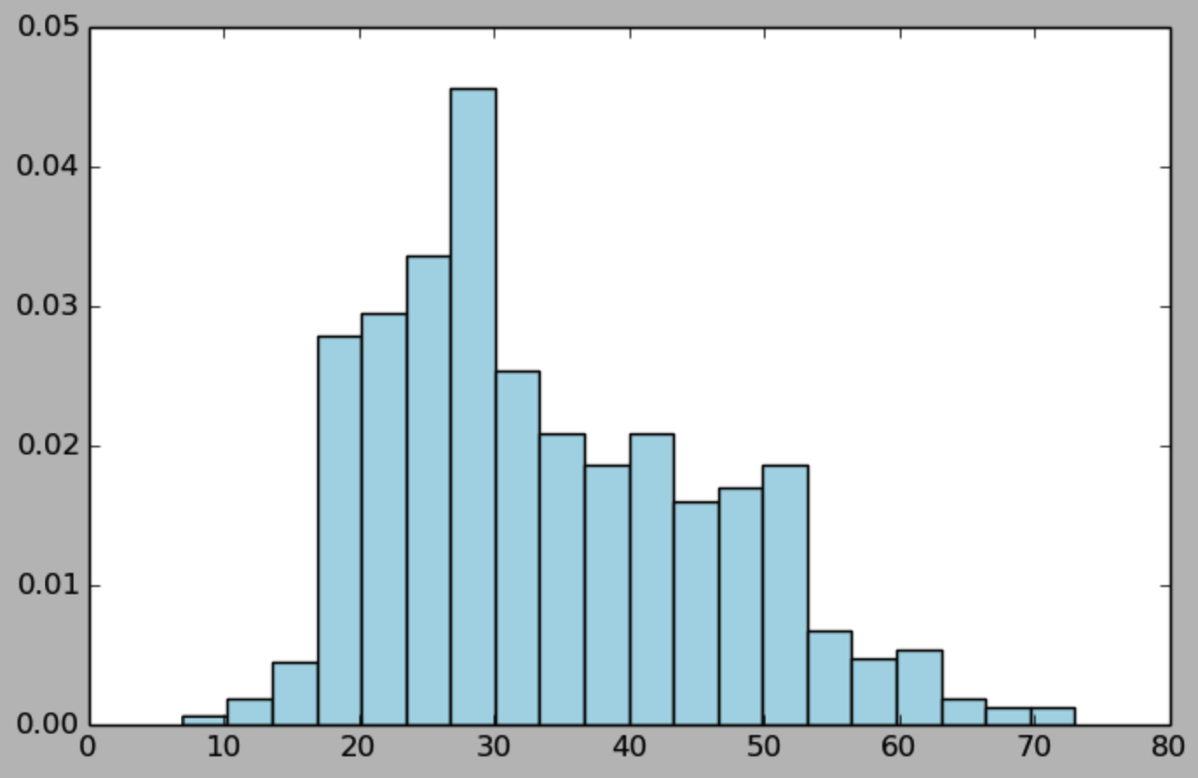
计算用户的年纪的基本分布:
Python
import matplotlib.pyplot as plt from matplotlib.pyplot import hist ages = user_fields.map(lambda x: int(x[1])).collect() hist(ages, bins=20, color='lightblue',normed=True) fig = plt.gcf() fig.set_size_inches(16,10)
import matplotlib.pyplotas plt from matplotlib.pyplotimport hist ages = user_fields.map(lambda x: int(x[1])).collect() hist(ages, bins=20, color='lightblue',normed=True) fig = plt.gcf() fig.set_size_inches(16,10)
计算用户的职业的分布:
Python
import numpy as np count_by_occupation = user_fields.map(lambda fields: (fields[3],1)).reduceByKey(lambda x,y:x+y).collect() print count_by_occupation x_axis1 = np.array([c[0] for c in count_by_occupation]) y_axis1 = np.array([c[1] for c in count_by_occupation]) x_axis = x_axis1[np.argsort(y_axis1)] y_axis = y_axis1[np.argsort(y_axis1)] pos = np.arange(len(x_axis)) width = 1.0 ax = plt.axes() ax.set_xticks(pos+(width)/2) ax.set_xticklabels(x_axis) plt.bar(pos, y_axis, width, color='lightblue') plt.xticks(rotation=30) fig = plt.gcf() fig.set_size_inches(10,6)
import numpyas np count_by_occupation = user_fields.map(lambda fields: (fields[3],1)).reduceByKey(lambda x,y:x+y).collect() print count_by_occupation x_axis1 = np.array([c[0] for c in count_by_occupation]) y_axis1 = np.array([c[1] for c in count_by_occupation]) x_axis = x_axis1[np.argsort(y_axis1)] y_axis = y_axis1[np.argsort(y_axis1)] pos = np.arange(len(x_axis)) width = 1.0 ax = plt.axes() ax.set_xticks(pos+(width)/2) ax.set_xticklabels(x_axis) plt.bar(pos, y_axis, width, color='lightblue') plt.xticks(rotation=30) fig = plt.gcf() fig.set_size_inches(10,6)


使用IPython notebook看看电影数据
读入电影数据,计算总数:
Python
movie_data = sc.textFile("../data/ML_spark/MovieLens/u.item") print movie_data.first() num_movies = movie_data.count() print 'Movies: %d' % num_movies movie_data = sc.textFile("../data/ML_spark/MovieLens/u.item") print movie_data.first() num_movies = movie_data.count() print 'Movies: %d' % num_movies 
计算电影的age分布:
Python
def convert_year(x): try: return int(x[-4:]) except: return 1900 movie_fields = movie_data.map(lambda lines:lines.split('|')) years = movie_fields.map(lambda fields: fields[2]).map(lambda x: convert_year(x)) years_filtered = years.filter(lambda x: x!=1900) print years_filtered.count() movie_ages = years_filtered.map(lambda yr:1998-yr).countByValue() values = movie_ages.values() bins = movie_ages.keys() hist(values, bins=bins, color='lightblue',normed=True) fig = plt.gcf() fig.set_size_inches(8,5) def convert_year(x): try: return int(x[-4:]) except: return 1900 movie_fields = movie_data.map(lambda lines:lines.split('|')) years = movie_fields.map(lambda fields: fields[2]).map(lambda x: convert_year(x)) years_filtered = years.filter(lambda x: x!=1900) print years_filtered.count() movie_ages = years_filtered.map(lambda yr:1998-yr).countByValue() values = movie_ages.values() bins = movie_ages.keys() hist(values, bins=bins, color='lightblue',normed=True) fig = plt.gcf() fig.set_size_inches(8,5) 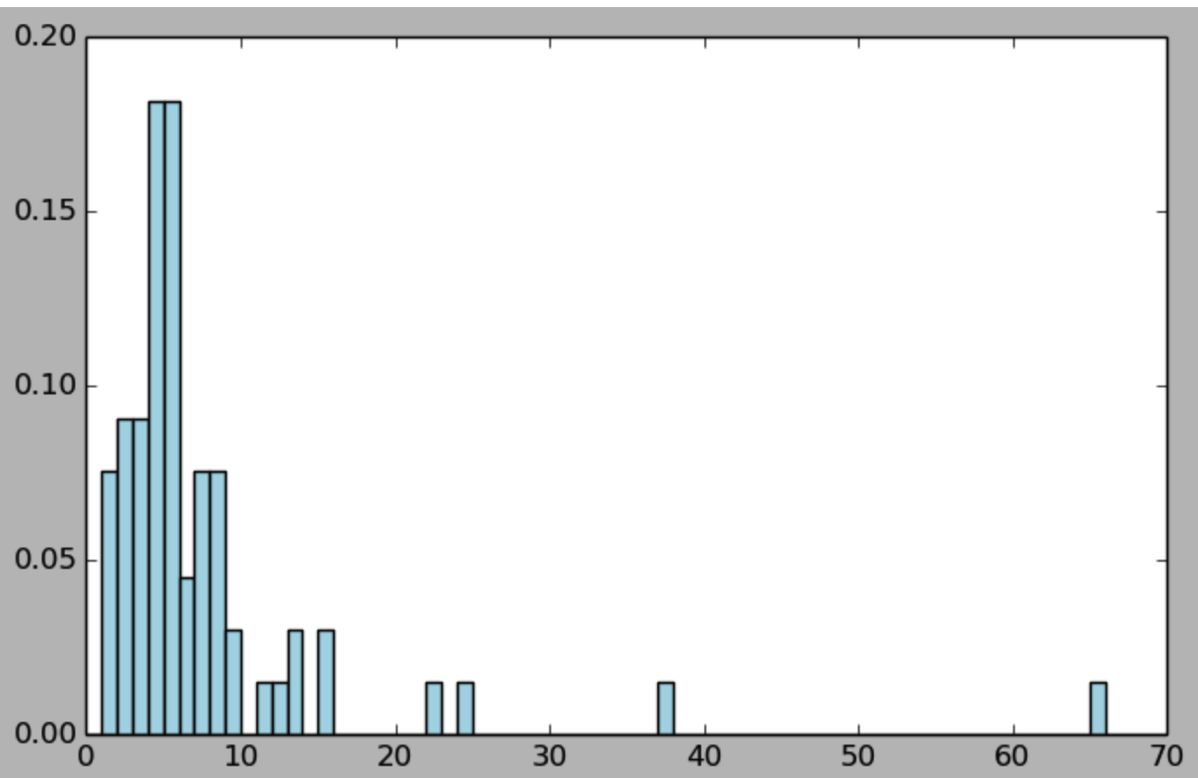
使用Ipython notebook看看用户对电影排序的数据集
查看数据记录数量:
Python
rating_data = sc.textFile('../data/ML_spark/MovieLens/u.data') print rating_data.first() num_ratings = rating_data.count() print 'Ratings: %d'% num_ratings rating_data = sc.textFile('../data/ML_spark/MovieLens/u.data') print rating_data.first() num_ratings = rating_data.count() print 'Ratings: %d'% num_ratings 对数据进行一些基本的统计:
Python
rating_data = rating_data.map(lambda line: line.split('/t')) ratings = rating_data.map(lambda fields: int(fields[2])) max_rating = ratings.reduce(lambda x,y:max(x,y)) min_rating = ratings.reduce(lambda x,y:min(x,y)) mean_rating = ratings.reduce(lambda x,y:x+y)/num_ratings median_rating = np.median(ratings.collect()) ratings_per_user = num_ratings/num_users; ratings_per_movie = num_ratings/ num_movies print 'Min rating: %d' %min_rating print 'max rating: %d' % max_rating print 'Average rating: %2.2f' %mean_rating print 'Median rating: %d '%median_rating print 'Average # of ratings per user: %2.2f'%ratings_per_user print 'Average # of ratings per movie: %2.2f' % ratings_per_movie rating_data = rating_data.map(lambda line: line.split('/t')) ratings = rating_data.map(lambda fields: int(fields[2])) max_rating = ratings.reduce(lambda x,y:max(x,y)) min_rating = ratings.reduce(lambda x,y:min(x,y)) mean_rating = ratings.reduce(lambda x,y:x+y)/num_ratings median_rating = np.median(ratings.collect()) ratings_per_user = num_ratings/num_users; ratings_per_movie = num_ratings/ num_movies print 'Min rating: %d' %min_rating print 'max rating: %d' % max_rating print 'Average rating: %2.2f' %mean_rating print 'Median rating: %d '%median_rating print 'Average # of ratings per user: %2.2f'%ratings_per_user print 'Average # of ratings per movie: %2.2f' % ratings_per_movie 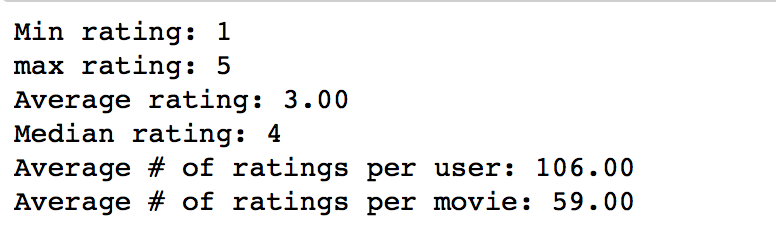
计算ratings value的分布:
Python
count_by_rating = ratings.countByValue() x_axis = np.array(count_by_rating.keys()) y_axis = np.array([float(c) for c in count_by_rating.values()]) y_axis_normed = y_axis/y_axis.sum() pos = np.arange(len(x_axis)) width = 1.0 ax = plt.axes() ax.set_xticks(pos+(width/2)) ax.set_xticklabels(x_axis) plt.bar(pos, y_axis_normed, width, color='lightblue') plt.xticks(rotation=30) fig = plt.gcf() fig.set_size_inches(8,5)
count_by_rating = ratings.countByValue() x_axis = np.array(count_by_rating.keys()) y_axis = np.array([float(c) for c in count_by_rating.values()]) y_axis_normed = y_axis/y_axis.sum() pos = np.arange(len(x_axis)) width = 1.0 ax = plt.axes() ax.set_xticks(pos+(width/2)) ax.set_xticklabels(x_axis) plt.bar(pos, y_axis_normed, width, color='lightblue') plt.xticks(rotation=30) fig = plt.gcf() fig.set_size_inches(8,5)
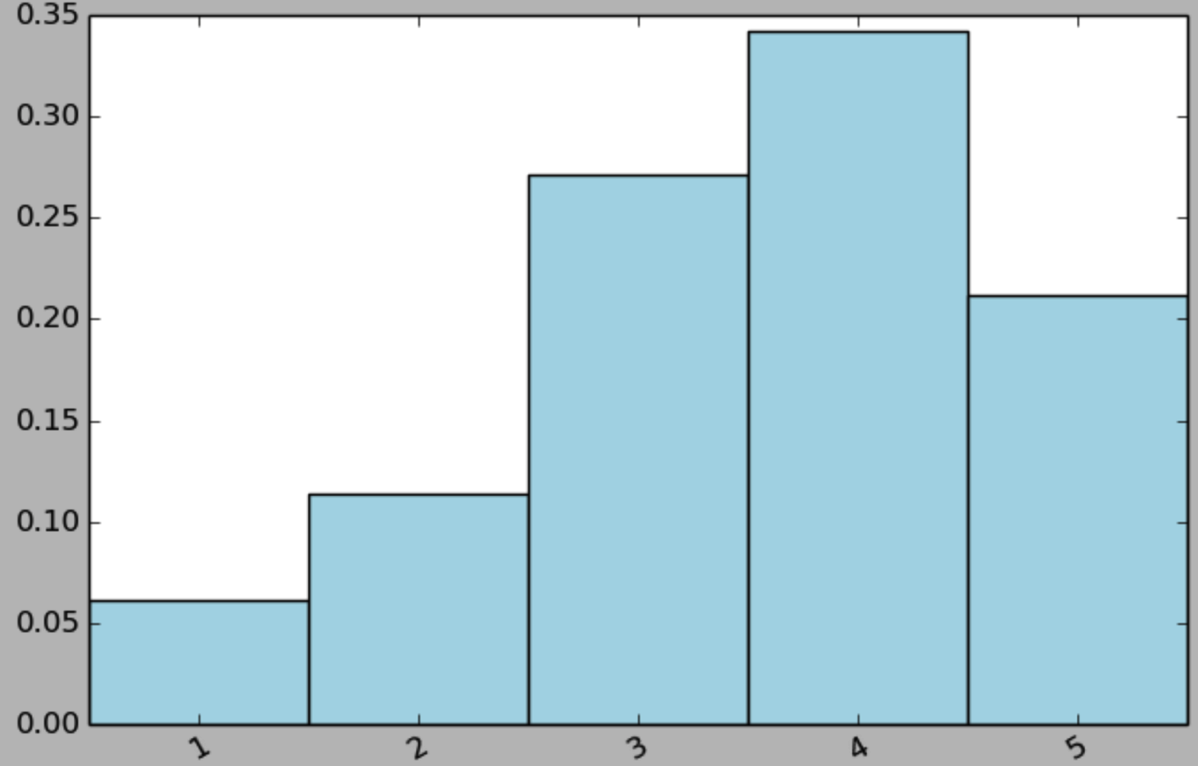
计算每个用户和其对应的评价次数:
Python
user_ratings_grouped = rating_data.map(lambda fields:(int(fields[0]),int(fields[2]))).groupByKey() user_rating_byuser = user_ratings_grouped.map(lambda (k,v):(k,len(v))) user_rating_byuser.take(5)
user_ratings_grouped = rating_data.map(lambda fields:(int(fields[0]),int(fields[2]))).groupByKey() user_rating_byuser = user_ratings_grouped.map(lambda (k,v):(k,len(v))) user_rating_byuser.take(5)
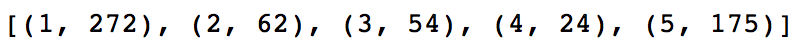
计算每个用户的总共评价次数的分布:
Python
user_ratings_byuser_local = user_rating_byuser.map(lambda (k,v):v).collect() hist(user_ratings_byuser_local, bins=200, color = 'lightblue',normed = True) fig = plt.gcf() fig.set_size_inches(8,5)
user_ratings_byuser_local = user_rating_byuser.map(lambda (k,v):v).collect() hist(user_ratings_byuser_local, bins=200, color = 'lightblue',normed = True) fig = plt.gcf() fig.set_size_inches(8,5)
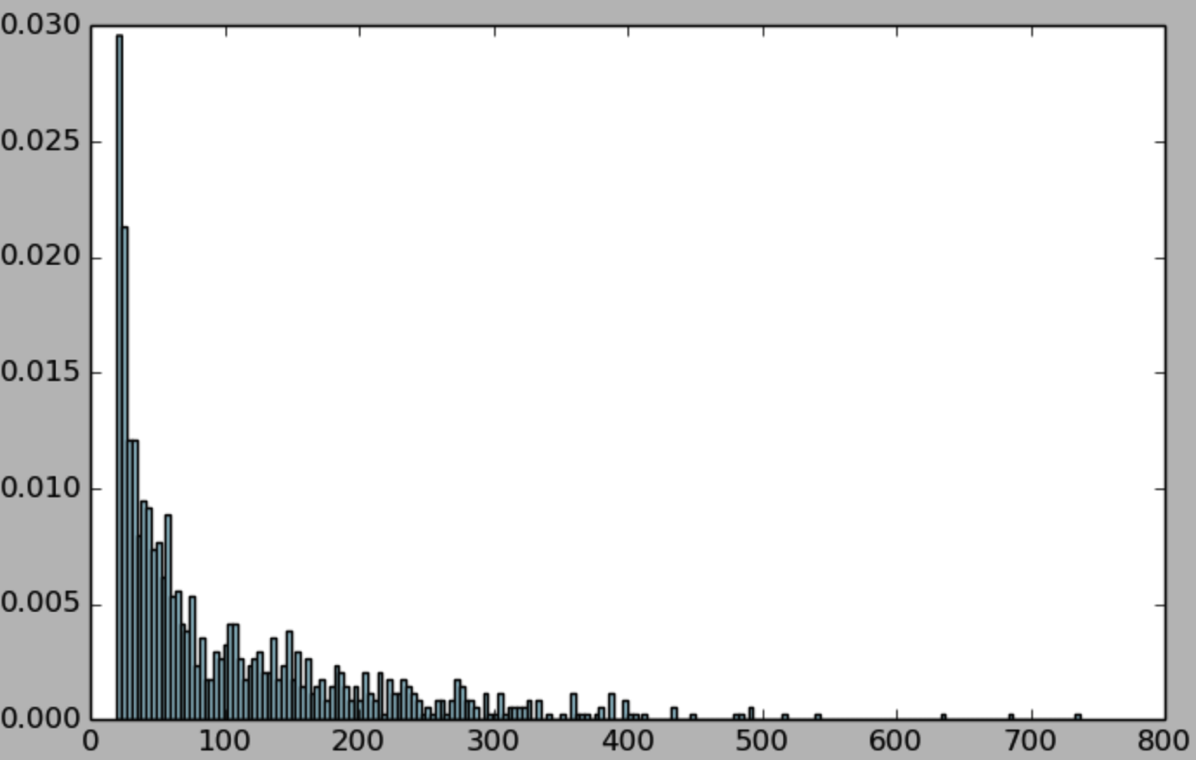
为每部电影计算其被评论数量分布:
Python
# 为每部电影计算他的被评论的次数的分布 movie_ratings_group = rating_data.map(lambda fields: (int(fields[1]),int(fields[2]))).groupByKey() movie_ratings_byuser = movie_ratings_group.map(lambda (k,v):(k,len(v))) movie_ratings_byuser.take(5)
# 为每部电影计算他的被评论的次数的分布 movie_ratings_group = rating_data.map(lambda fields: (int(fields[1]),int(fields[2]))).groupByKey() movie_ratings_byuser = movie_ratings_group.map(lambda (k,v):(k,len(v))) movie_ratings_byuser.take(5)
Python
movie_ratings_byuser_local = movie_ratings_byuser.map(lambda (k,v):v).collect() hist(movie_ratings_byuser_local,bins=200,color='lightblue',normed=True) fig = plt.gcf() fig.set_size_inches(8,5)
movie_ratings_byuser_local = movie_ratings_byuser.map(lambda (k,v):v).collect() hist(movie_ratings_byuser_local,bins=200,color='lightblue',normed=True) fig = plt.gcf() fig.set_size_inches(8,5)
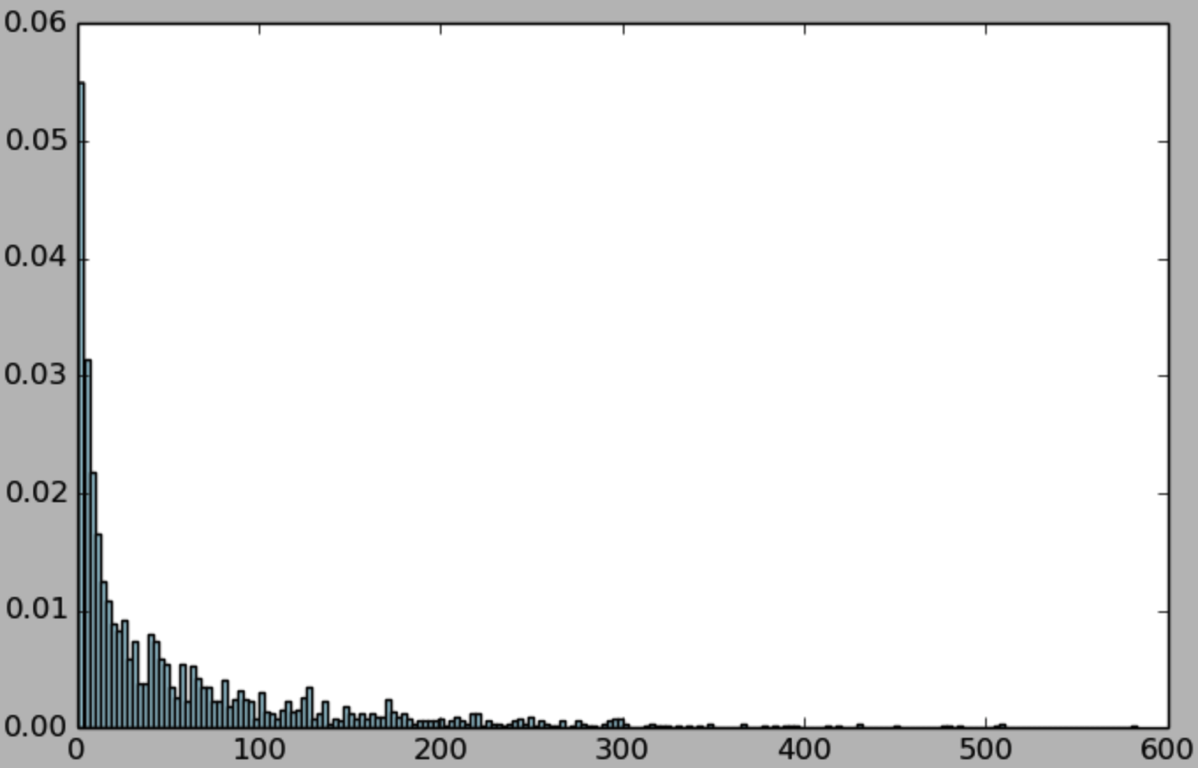
处理与变换数据
主要处理方法:
- 滤除或移除bad values和missing values
- 用给定值来替换bad values和missing values
- 针对异值点使用一些鲁棒性强的技术
- 对潜在异值点进行转换
用指定值替换bad values和missing values
Python
years_pre_processed = movie_fields.map(lambda fields: fields[2]).map(lambda x: convert_year(x)).collect() years_pre_processed_array = np.array(years_pre_processed) mean_year = np.mean(years_pre_processed_array[years_pre_processed_array!=1900]) median_year = np.median(years_pre_processed_array[years_pre_processed_array!=1900]) index_bad_data = np.where(years_pre_processed_array==1900) years_pre_processed_array[index_bad_data] = median_year print 'Mean year of release: %d' % mean_year print 'Median year of release: %d ' % median_year print "Index of '1900' after assigning median: %s"% np.where(years_pre_processed_array==1900)[0]
years_pre_processed = movie_fields.map(lambda fields: fields[2]).map(lambda x: convert_year(x)).collect() years_pre_processed_array = np.array(years_pre_processed) mean_year = np.mean(years_pre_processed_array[years_pre_processed_array!=1900]) median_year = np.median(years_pre_processed_array[years_pre_processed_array!=1900]) index_bad_data = np.where(years_pre_processed_array==1900) years_pre_processed_array[index_bad_data] = median_year print 'Mean year of release: %d' % mean_year print 'Median year of release: %d ' % median_year print "Index of '1900' after assigning median: %s"% np.where(years_pre_processed_array==1900)[0]
用中位数的值来替代哪些bad values
从数据中提取有用特征
特征可以分为多种特征,包括:
- Numerical features
- Categorical features,如性别
- Text features,如标题
- Other features,如经纬度信息
- Derived features,如前面的movie age
Python
all_occupations = user_fields.map(lambda fields:fields[3]).distinct().collect() all_occupations.sort() idx = 0 all_occupations_dict = {} for o in all_occupations: all_occupations_dict[o] = idx idx +=1 print "Encoding of 'doctor': %d" %all_occupations_dict['doctor'] print "Encoding of 'programmer': %d" % all_occupations_dict['programmer'] all_occupations = user_fields.map(lambda fields:fields[3]).distinct().collect() all_occupations.sort() idx = 0 all_occupations_dict = {} for o in all_occupations: all_occupations_dict[o] = idx idx +=1 print "Encoding of 'doctor': %d" %all_occupations_dict['doctor'] print "Encoding of 'programmer': %d" % all_occupations_dict['programmer'] 上面将categorical features转换到数值型的,但是经常我们在做数据处理的时候,这类彼此之间没有潜在排序信息的数据,应该进行dummies处理:
Python
K=len(all_occupations_dict) binary_x = np.zeros(K) k_programmer = all_occupations_dict['programmer'] binary_x[k_programmer] = 1 print 'Binary feature vector: %s'%binary_x print 'Length of binray vector: %d' %K
K=len(all_occupations_dict) binary_x = np.zeros(K) k_programmer = all_occupations_dict['programmer'] binary_x[k_programmer] = 1 print 'Binary feature vector: %s'%binary_x print 'Length of binray vector: %d' %K
特征值做dummies处理后,得到的二值化的特征:

时间戳转为categorical feature
Python
def extract_datetime(ts): import datetime return datetime.datetime.fromtimestamp(ts) timestamps = rating_data.map(lambda fields:int(fields[3])) hour_of_day = timestamps.map(lambda ts: extract_datetime(ts).hour) hour_of_day.take(5)
def extract_datetime(ts): import datetime return datetime.datetime.fromtimestamp(ts) timestamps = rating_data.map(lambda fields:int(fields[3])) hour_of_day = timestamps.map(lambda ts: extract_datetime(ts).hour) hour_of_day.take(5)
![]()
按时间段划分为morning,lunch, afternoon, evening, night(下面有原书代码是错误的 ’night’:[23,7]):
Python
def assign_tod(hr): times_of_day = { 'morning':range(7,12), 'lunch': range(12,14), 'afternoon':range(14,18), 'evening':range(18,23), 'night': [23,24,1,2,3,4,5,6] } for k,v in times_of_day.iteritems(): if hr in v: return k def assign_tod(hr): times_of_day = { 'morning':range(7,12), 'lunch': range(12,14), 'afternoon':range(14,18), 'evening':range(18,23), 'night': [23,24,1,2,3,4,5,6] } for k,v in times_of_day.iteritems(): if hrin v: return k 
然后对这些时间段做dummies处理,编码成[0,0,0,0,1],操作类似于原来的职业统计处理的时候:
Python
time_of_day_unique = time_of_day.map(lambda fields:fields).distinct().collect() time_of_day_unique.sort() idx = 0 time_of_day_unique_dict = {} for o in time_of_day_unique: time_of_day_unique_dict[o] = idx idx +=1 print "Encoding of 'afternoon': %d" %time_of_day_unique_dict['afternoon'] print "Encoding of 'morning': %d" % time_of_day_unique_dict['morning'] print "Encoding of 'lunch': %d" % time_of_day_unique_dict['lunch'] time_of_day_unique = time_of_day.map(lambda fields:fields).distinct().collect() time_of_day_unique.sort() idx = 0 time_of_day_unique_dict = {} for o in time_of_day_unique: time_of_day_unique_dict[o] = idx idx +=1 print "Encoding of 'afternoon': %d" %time_of_day_unique_dict['afternoon'] print "Encoding of 'morning': %d" % time_of_day_unique_dict['morning'] print "Encoding of 'lunch': %d" % time_of_day_unique_dict['lunch'] ![]()
文本特征处理基本步骤:
- Tokenization
- Stop word removal
- Stemming
- Vectorization
简单的文本特征提取:
1,提取出titles
Python
def extract_title(raw): import re grps = re.search("/((/w+)/)",raw) if grps: return raw[:grps.start()].strip() else: return raw raw_titles = movie_fields.map(lambda fields: fields[1]) for raw_title in raw_titles.take(5): print extract_title(raw_title) def extract_title(raw): import re grps = re.search("/((/w+)/)",raw) if grps: return raw[:grps.start()].strip() else: return raw raw_titles = movie_fields.map(lambda fields: fields[1]) for raw_titlein raw_titles.take(5): print extract_title(raw_title) 2,分词处理(汉语麻烦,还好这里是英语,用空格就可以了)
Python
movie_titles = raw_titles.map(lambda m: extract_title(m)) title_terms = movie_titles.map(lambda m:m.split(' ')) print title_terms.take(5) movie_titles = raw_titles.map(lambda m: extract_title(m)) title_terms = movie_titles.map(lambda m:m.split(' ')) print title_terms.take(5) 然后将所有titles出现的word去重,然后就可以看到所有的word的list:
Python
all_terms = title_terms.flatMap(lambda x: x).distinct().collect() idx = 0 all_terms_dict = {} for term in all_terms: all_terms_dict[term] = idx idx+=1 print "Total number of terms: %d" % len(all_terms_dict) print "Index of term 'Dead': %d" % all_terms_dict['Dead'] print "Index of term 'Rooms': %d" % all_terms_dict['Rooms'] all_terms = title_terms.flatMap(lambda x: x).distinct().collect() idx = 0 all_terms_dict = {} for termin all_terms: all_terms_dict[term] = idx idx+=1 print "Total number of terms: %d" % len(all_terms_dict) print "Index of term 'Dead': %d" % all_terms_dict['Dead'] print "Index of term 'Rooms': %d" % all_terms_dict['Rooms'] 
上面的可以用Spark内置的zipWithIndex来完成,zipWithIndex的使用:
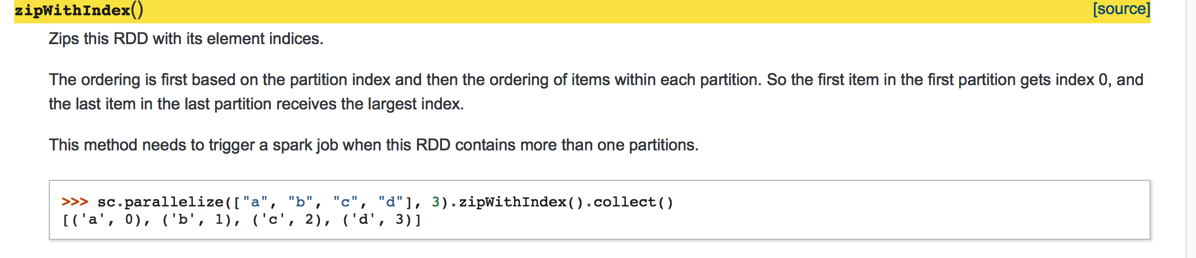
Python
all_terms_dict2 = title_terms.flatMap(lambda x:x).distinct().zipWithIndex().collectAsMap() print "Index of term 'Dead %d" % all_terms_dict['Dead'] print "Index of term 'Rooms': %d" % all_terms_dict['Rooms']
all_terms_dict2 = title_terms.flatMap(lambda x:x).distinct().zipWithIndex().collectAsMap() print "Index of term 'Dead %d" % all_terms_dict['Dead'] print "Index of term 'Rooms': %d" % all_terms_dict['Rooms']
结果与上个版本一致。
到了这里,我们就要想着如何把这些数据存储下来,如何使用,如果按前面对categorical var的处理方式,做dummies处理直接存储,显然会浪费太多的空间,我们在这里采用压缩稀疏(csc_matrix)的存储方式。
Python
def create_vector(terms, term_dict): from scipy import sparse as sp num_terms = len(term_dict) x = sp.csc_matrix((1,num_terms)) for t in terms: if t in term_dict: idx = term_dict[t] x[0,idx] = 1 return x all_terms_bcast = sc.broadcast(all_terms_dict) term_vectors = title_terms.map(lambda terms: create_vector(terms,all_terms_bcast.value)) term_vectors.take(5)
def create_vector(terms, term_dict): from scipyimport sparseas sp num_terms = len(term_dict) x = sp.csc_matrix((1,num_terms)) for t in terms: if t in term_dict: idx = term_dict[t] x[0,idx] = 1 return x all_terms_bcast = sc.broadcast(all_terms_dict) term_vectors = title_terms.map(lambda terms: create_vector(terms,all_terms_bcast.value)) term_vectors.take(5)

特征归一化
- 归一化单一特征
- 归一化特征向量
使用MLlib来做特征归一化
Python
from pyspark.mllib.feature import Normalizer normlizer = Normalizer() vector = sc.parallelize([X]) normalized_x_mllib = normlizer.transform(vector).first().toArray()
from pyspark.mllib.featureimport Normalizer normlizer = Normalizer() vector = sc.parallelize([X]) normalized_x_mllib = normlizer.transform(vector).first().toArray()
Python
print "x:/n%s" % X print "2-Norm of x: %2.4f" % norm_x_2 print "Normalized x:/n%s" % normalized_x print "Normalized x MLlib:/n%s" % normalized_x_mllib print "2-Norm of normalized_x_mllib: %2.4f" % np.linalg.norm(normalized_x_mllib)
print "x:/n%s" % X print "2-Norm of x: %2.4f" % norm_x_2 print "Normalized x:/n%s" % normalized_x print "Normalized x MLlib:/n%s" % normalized_x_mllib print "2-Norm of normalized_x_mllib: %2.4f" % np.linalg.norm(normalized_x_mllib)

总结:spark支持多种语言,如scala,java, python,可以使用相应的包来进行特征处理,例如python下scikit-learn,gensim,svikit-image,matplotlib,notebook文件在 github上
正文到此结束
热门推荐










相关文章

近期评论
-
主要用的是AI
-
博主的博客用的什么技术栈,内容都是干货,赞
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

