开源MySQL多线程逻辑导出工具mydumper原理与改进: 前言之前介绍了Oracle官方的多线程逻辑导入导出
前言
之前介绍了Oracle官方的多线程逻辑导入导出工具mysqlpump,但已经操作过的同学会发现其多线程的单位还是表,换句话说, 单表依然是 单线程导出 。网易早已使用mydumper/myloader这样优秀的社区工具来进行逻辑的导入和导出,本文正是网易小伙伴对于此工具的心得。同时,IMG社区欢迎小伙伴前来投稿,打造最有态度的MySQL社区。
mydumper/myloader简介
mydumper(&myloader)是用于对MySQL数据库进行多线程备份和恢复的开源 (GNU GPLv3)工具。开发人员主要来自MySQL、Facebook和SkySQL公司,目前由Percona公司开发和维护,是 Percona Remote DBA 项目的重要组成部分,包含在Percona XtraDB Cluster中。mydumper的第一版0.1发布于2010.3.26,最新版本0.9.1发布于2015.11.06。
导入导出测试
下图是在SSD和HDD存储介质上将mydumper和同为逻辑备份的MySQL官方mysqldump所做的性能对比测试,测试对象为网易博客库:

可以发现,在备份时间上,mydumper性能比mysqldump好将近1倍,通过分析不难发现,两者性能的差距主要跟备份实例的IO性能以及mydumper开启的线程数有关系,如果外部实例的IO性能很差,那么可能mysqldump单线程就能够将IO吃满,那改为使用mydumper也无法带来性能提升,但 如果实例的IO性能较好,通过增加备份线程数(测试所用为2线程),就可能带来成倍的性能提升 。导入时间分别使用与mydumper配合使用的myloader多线程sql导入工具以及mysqldump对应的source命令得到。相应的,在IO性能较好的SSD上,myloader的多线程优势体现明显,比source的单线程执行时间上节省将近2倍(测试所用为4线程)。不过在HDD上,由于其本身性能原因,myloader带来的效益变小。
多线程导出原理
mydumper是一种比MySQL官方mysqldump更优秀的备份工具,主要体现在多线程和备份文件保存方式上。在MySQL 5.7版本中,官方发布了一种新的备份工具mysqlpump,也是多线程的,其实现方式给人耳目一新的感觉,但遗憾的是其仍为表级别的并行。而mydumper能够实现记录级别的并行备份,其备份框架由主线程和多个工作线程组成,备份流程可见下图:
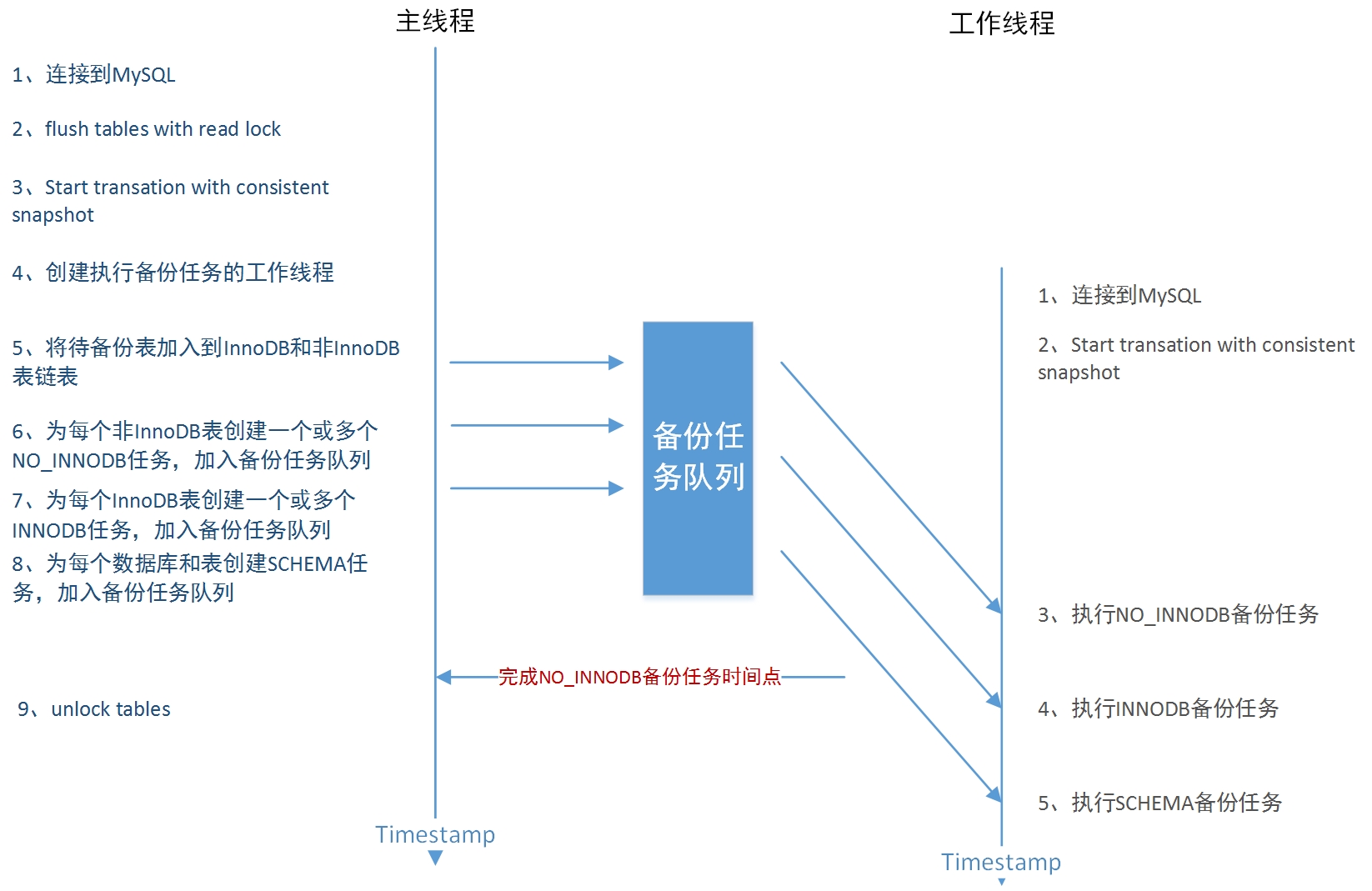
主线程负责建立数据一致性备份点、初始化工作线程和为工作线程推送备份任务:
- 对备份实例加读锁,阻塞写操作以建立一致性数据备份快照点,记录备份点BinLog信息;
- 创建工作线程,初始化备份任务队列,并向队列中推送数据库元数据(schema)、非InnoDB表和InnoDB表的备份任务;
工作线程负责将备份任务队列中的任务按顺序取出并完成备份:
- 分别建立与备份实例连接,将session的事务级别设置为repeatable-read,用于实现可重复读;
- 在主线程仍持有全局读锁时开启事务进行快照读,这样保证了读到的一致性数据与主线程相同,实现了备份数据的一致性;
- 按序从备份任务队列中取出备份任务,工作线程先进行MyISAM等非InnoDB表备份,再完成InnoDB表备份;这样可以在完成非InnoDB表备份通知后主线程释放读锁,尽可能减小对备份实例业务的影响;
mydumper的记录级备份由主线程负责任务拆分,由多个工作线程完成。主线程通过将表数据拆分为多个chunk,每个chunk作为一个备份任务。表数据拆分方式如下所述:mydumper优先选择主键索引的第一列作为chunk划分字段,若不存在主键索引,则选择第一个唯一索引作为划分依据,若还不存在,则选择区分度(Cardinality)最高的任意索引。如果还是无法满足,则只能进行表级的并行备份。在确定了chunk划分字段后,先获取该字段的最大和最小值,再通过执行“explain select field from db.table”来估计该表的记录数,最后根据所设的每个任务(文件)记录数来将该表划分为多个chunk。如下图所示:
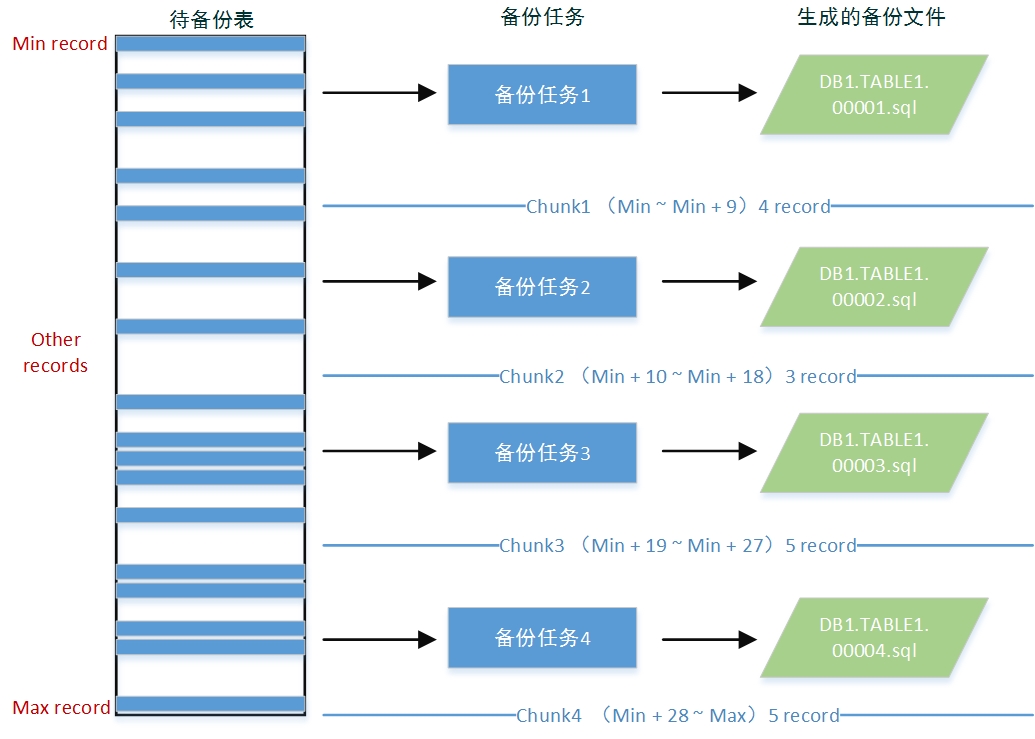
以上描述可知,mydumper并不能保证记录级备份时,每个备份任务中的记录数是相同的。另外,目前记录级备份存在一个bug:所用索引字段为负数时主线程会进入死循环无法退出,导致备份失败。 https://bugs.launchpad.net/mydumper/+bug/1418355
与mysqldump另一个不同是, mydumper为每个备份任务建立至少一个备份文件。在0.9.1版本中,文件类型包括schema-create、schema、schema-post文件等表元数据文件分别用保存建数据库语句、建表语句(包括触发器)、函数/存储过程/事件定义语句等;数据文件可以根据用户设置为固定大小或固定记录数的文件。这样便以进行更细粒度的数据恢复和数据删除,比如可以在myloader的时候仅选择某几个数据库/表进行恢复。
网易对mydumper的改进
mydumper是一款优秀的备份工具,但也存在不足,包括多线程导出数据对实例业务的影响、逻辑备份方式对热点数据污染和持锁时对业务的阻塞等。网易RDS在mydumper实践中对其进行了多方面的优化。
多线程备份固然好,但在进行备份时往往数据库还在正常提供对外服务,多线程全表select数据会占用很大部分的系统IO能力,导致正常的业务IO性能下降,严重时甚至会使数据库连接爆掉。通过为mydumper增加负载自适应能力来最大限度缓解对线上业务影响:工作线程在每次数据导出前,都会首先观察实例的当前负载情况,举MySQL状态Thread_connected为例,其反映的是目前已连接到该实例的请求数,如果该数值大于设定的阈值,则本次导出操作会暂停,直到数值小于阈值才会恢复,这样就起到了根据实例业务负载情况,灵活调整用于数据导出的线程数来适应线上业务负载的作用。
逻辑备份的全表select不可避免会污染InnoDB Buffer Pool的热点数据,缓存的热点数据被换出,降低了命中率的同时增大了业务的IO量,在使用mydumper时应尽量减小对Buffer Pool的影响;通过调整Buffer Pool的热点算法,使得热点数据尽可能不被换出。修改innodb_old_blocks_time和innodb_old_blocks_pct,用于将全表select进入Buffer Pool放在其old sublist中,同时减小old sublist块在Buffer Pool中的比例,起到最小化污染的作用。其原理详见 http://dev.mysql.com/doc/innodb-plugin/1.0/en/idm47548325357504.html
在进行数据备份时,由于MyISAM表是非事务的,为了得到一致性的数据,导出MyISAM表需要全程持有读锁。在通常的MySQL实例中,MyISAM表数据都是很少的,所以持锁时间很短,但若有实例存在大量的MyISAM表数据,那么就会因持锁时间过长对业务的数据更新和插入造成影响。通过为mydumper增加持锁超时时间来避免该问题,所在数据备份过程中,持锁时间超过所设置时间,则mydumper返回失败,通过将MyISAM表转化为InnoDB表后再开始导出。
此外,在对大数据量数据库进行备份时,往往需要耗费较长时间,如果能够实时了解备份进度,相信是一个很好的体验,为此,给mydumper增加了进度查询功能,能够查询mydumper所需执行的所有备份任务数、当前已经完成的备份任务数及每个备份任务所花费时间。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

