Python爬虫开发(五):反爬虫措施以及爬虫编写注意事项
*原创作者:VillanCh
0×00 前言
0×01 介绍
0×02 问题的分类
0×03 顺从的艺术
0×04 反爬虫
0×05 Anti-Anti-Spider
0×06 爬虫编写注意事项
0×07 反馈与问题
0×00 前言
在 关于爬虫技术点的一系列文章 完成之后,想到由一个读者在评论区留言希望了解一下爬虫和反爬虫的内容,在自己准备一番之后,准备就这个问题进行一些介绍,希望能帮到希望了解这一方面的读者。
0×01 介绍
爬虫对于网站拥有者来说并不是一个令人高兴的存在,因为爬虫的肆意横行意味着自己的网站资料泄露,甚至是自己刻意隐藏在网站的隐私的内容也会泄露。面对这样的状况,作为网站的维护者或者拥有者,要么抵御爬虫,通过各种反爬虫的手段阻挡爬虫,要么顺从爬虫,自动提供可供爬虫使用的接口。对于这两种决策的正确与否,实际上是有一些讲究的,作为一个电商平台来讲,某种程度上来说还是希望爬虫在自己网站上工作但是却不希望爬虫的工作影响了平台的运营,但是这就有一个问题了,也就是前几篇文章中有读者问道的,如何减轻爬虫造成的损失。作为搜索引擎来讲,实际上工作在搜索引擎上的爬虫可能是道德缺失的,实际上,搜索引擎作为非常专业的爬虫,尊崇爬虫道德准则,但是不希望自己同类获取自己辛苦收集的信息,同样这样也就是说,作为搜索引擎来讲,可以说是绝对反爬虫的
0×02 问题的分类
那么,由我们上面的叙述,对于爬虫的策略也就有:
1. 顺从但减轻损失
2. 爬虫反制
0×03 顺从的艺术
可能有人会觉得可笑,为什么要顺从?很简单,记得我们以前使用的sitemap么?可以说它就是为了爬虫服务,除此之外,我们还要知道推特的开放平台提供了收费的爬虫接口,google也提供了收费的爬虫接口。那么大家觉得这些墙外的事情离我们还是非常的远,那么我就来举一些例子好了,我们经常网购的朋友都使用京东对吧?也许大家还不知道京东有自己的开放平台,可以供爬虫或者是希望获取京东内商家或者商品信息的开发者:
然后我们打开API页面的商品API页面:
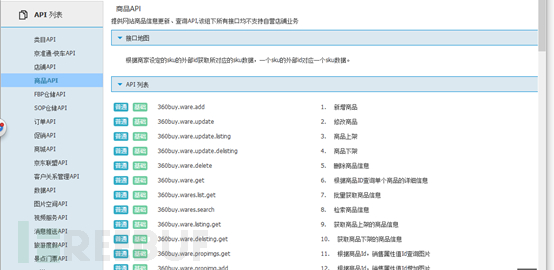
我们发现它提供了不少易用的接口,开发者注册以后可以使用,或者处理一下丢给爬虫去使用。同样的淘宝也有相应的平台,但是应该是收费的,就是淘宝开放平台,要在聚石塔调用API才会生效:

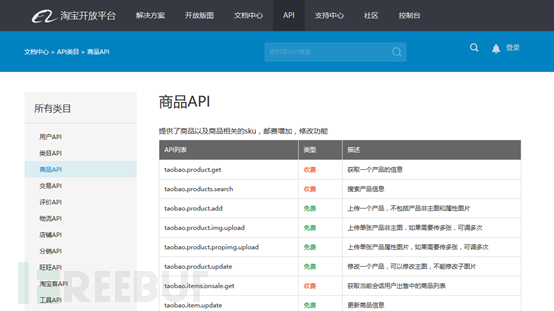
大家可以看到,如果你希望获取的是京东或者淘宝的信息,怎么办?自己费力去解析网页并不是一个好办法,再者说,在爬虫开发四中,我们举的例子就是淘宝的例子,一般的爬虫是没有办法爬到淘宝页面的,这也就从某种程度上解释了为什么百度很难收到淘宝的商品信息什么的,当然不是说百度没有动态爬虫这项技术。
读者会发现,如果我们要使用这些爬虫,就要遵守商家约定的规则,注册甚至是付费才能使用。
其实这就是一个本部分讲的一个平衡点,作为一只爬虫,如果想要在某个网站工作,就必须遵守网站的规则(robots.txt协议,开放平台API协议)。
当然如果爬虫制造者觉得不爽,当然可以有别的办法啊,但是代价就是你要针对这个网站写不少爬虫代码,增加自己的开发成本,也不能说得不偿失,只是你有了汽车为什么还偏爱自行车呢?当然自行车和汽车也是有优劣之分的:顶多也就是比赛竞速用的自行车和一辆小奥拓的差别吧。
0×04 反爬虫
但是你是真的真的很讨厌爬虫,你恨不得有一万种措施挡住爬虫,那么同样的,有些措施可以起到很好的效果,有些措施可能起不了多大的作用,那么我们现在就来讲一下反爬虫的几重措施。
1. IP限制
如果是个人编写的爬虫,IP可能是固定的,那么发现某个IP请求过于频繁并且短时间内访问大量的页面,有爬虫的嫌疑,作为网站的管理或者运维人员,你可能就得想办法禁止这个IP地址访问你的网页了。那么也就是说这个IP发出的请求在短时间内不能再访问你的网页了,也就暂时挡住了爬虫。
2. User-Agent
User-Agent是用户访问网站时候的浏览器的标识
下面我列出了常见的几种正常的系统的User-Agent大家可以参考一下,
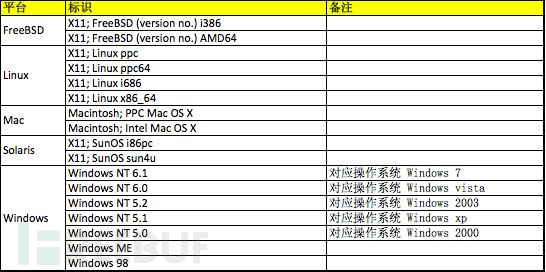
并且在实际发生的时候,根据浏览器的不同,还有各种其他的User-Agent,我举几个例子方便大家理解:
safari 5.1 – MAC
User-Agent:Mozilla/5.0 (Macintosh; U; IntelMac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1Safari/534.50Firefox 4.0.1 – MAC
User-Agent: Mozilla/5.0 (Macintosh; IntelMac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1Firefox 4.0.1 – Windows
User-Agent:Mozilla/5.0 (Windows NT 6.1;rv:2.0.1) Gecko/20100101 Firefox/4.0.1同样的也有很多的合法的User-Agent,只要用户访问不是正常的User-Agent极有可能是爬虫再访问,这样你就可以针对用户的User-Agent进行限制了。
3、 验证码反爬虫
这个办法也是相当古老并且相当的有效果,如果一个爬虫要解释一个验证码中的内容,这在以前通过简单的图像识别是可以完成的,但是就现在来讲,验证码的干扰线,噪点都很多,甚至还出现了人类都难以认识的验证码(某二三零六)。

嗯,如果一个爬虫要访问的页面提示要输入验证码,那么问题就来了,不是所有的爬虫都装备了图像识别技术啊。其实大家要问了,爬虫处理这些登录页面有什么意义呢?除非你是想爆破密码或者是刷xxx什么的。但是真的有人把验证码用在反爬虫上的么?事实上确实有,Google就在使用,如果有使用google经验的读者会发现自己在愉快查google,特别是使用vpn或者是各种科学上网工具的时候,经常会提示你google想知道你是不是一个人(不是人还能是什么?)

不是所有的爬虫都可以配备OCR技术,所以自然这样可以很好的抵挡爬虫。(当然如果你有兴趣编写一个具有机器学习的OCR技术的爬虫的话,这样可能会有一些正确率,笔者有一段时间还是很想通过OCR技术解决验证码问题,但是尝试一点获得失败之后并没有新的进展,于是就放弃了)
4. Ajax异步加载
网页的不希望被爬虫拿到的数据使用Ajax动态加载,这样就为爬虫造成了绝大的麻烦,如果一个爬虫不具备js引擎,或者具备js引擎,但是没有处理js返回的方案,或者是具备了js引擎,但是没办法让站点显示启用脚本设置。基于这些情况,ajax动态加载反制爬虫还是相当有效的。具体的例子有很多,比如淘宝(在上一篇文章中我们有解释)。.
5. Noscript标签的使用
<noscript>标签是在浏览器(或者用户浏览标识),没有启动脚本支持的情况下触发的标签,在低级爬虫中,基本都没有配置js引擎,通常这种方式和Ajax异步加载同时使用。用于保护自己不想让爬虫接触的信息。
6. Cookie限制
第一次打开网页会生成一个随机cookie,如果再次打开网页这个cookie不存在,那么再次设置,第三次打开仍然不存在,这就非常有可能是爬虫在工作了。很简单,在三番屡次没有带有该带的cookie,就禁止访问。
0×05 Anti-Anti-Spider
这一部分笔者并不计划深入讲解,因为如果读过笔者前一部分爬虫文章的读者,都会知道,笔者基本把同一级别的主流爬虫解决方案都说的很清楚了,如果要问scrapy什么的爬虫框架,大家自行归类,从最底层到最顶层大家都是有了这些概念,我们接下来的介绍尽量从简。
接下来我们就讨论一些关于反爬虫反制的措施。其实在这段时间内,我总结出一条用于爬虫编写的核心定律:
像一个人一样浏览网页,像一台机器一样分析数据
接下来我们就讨论一下在整个一系列文章出现的解决方案能突破几种限制(Python2):
1. Urllib是最弱的web网页浏览模式,User-Agent,cookie,ip都无法解决;
2. Requests模块与urllib2,urllib3,基本可以解决静态网页的所有问题,但是没办法解决IP限制,如果需要解决IP限制则需要使用代理,如果需要解决验证码问题,则需要自己配置OCR;
3. Selenium+浏览器:无法解决验证码的问题,效率低,速度慢;
4. Ghost.py无法解决验证码问题,效率低,速度慢。
从原理上来讲,selenium或者ghost.py模式已经是完全模仿人类浏览网页方式了,事实上,他们就是,因为对于大多数人来:讲只有人类才会打开一个浏览器浏览网页,查看网页各种信息,click甚至是send_key.
具体来讲,建议使用Requests,学习Requests模块的使用,必要时使用selenium或者ghost.py。这样,面对所有的爬虫,也许就只有验证码和IP会比较伤脑筋了,但是对于IP限制来讲,我们并不畏惧,有经验的朋友可以很快构造出代理模式浏览其他网页,多久换一次IP就需要具体调查目标网页的限制阈值了。
那么也就是说验证码是一个巨大的门槛。诚然,的确是的,很多人致力多年研究绕过验证码。可以说是卓有成效也可以说是一筹莫展。目前比较成熟的方法就是使用机器学习识别验证码内容。但是一旦验证码识别方式改动以后,比如现在12306的验证码,这个着实是难以处理。但是大家也不要灰心,绕过验证码就一定要认认真真填写么?笔者在这里可以负责任地讲,验证码的绕过在很多的时候是通过web应用逻辑错误绕过的。
0×06 爬虫编写注意事项
在这一部分,笔者希望就自己的经验给大家编写爬虫提供比较可行的建议,也为大家提一个醒:
1. 道德问题,是否遵守robots协议;
2. 小心不要出现卡死在死循环中,尽量使用urlparser去解析分离url决定如何处理,如果简单的想当然的分析url很容易出现死循环的问题;
3. 单页面响应超时设置,默认是200秒,建议调短,在网络允许的条件下,找到一个平衡点,避免所有的爬虫线程都在等待200,结果出现效率降低;
4. 高效准确的判重模式,如果判重出现问题,就会造成访问大量已经访问过的页面浪费时间;
5. 可以采用先下载,后分析的方法,加快爬虫速度;
6. 在异步编程的时候要注意资源死锁问题;
7. 定位元素要精准(xpath)尽量避免dirty data。
这些问题都是笔者在学习的过程中,遇到的问题,拿出来给大家分享,希望对大家进行数据挖掘学习有所帮助。
0×07 反馈与问题
希望大家提出自己的意见,本系列大多数时间都在从微观的角度讲爬虫各个部件的解决方案。如果大家想知道一个完整的爬虫开发流程,欢迎留言给我,如果读者有兴趣,我还是可以从架构设计讲起,到具体的实现,再到调试运行,改造成分布式爬虫解决方案。
同时笔者作为一个不规矩的Coder,业余时间在编写一个Web Fuzz的工具,如果读者希望围观这个项目的开发现场,我也是很乐意分享出Github地址分享出来。
*原创作者:VillanCh,本文属FreeBuf原创奖励计划文章,未经作者本人及FreeBuf许可,切勿私自转载
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

