ticketea如何从一体化转向多体化架构
ticketea是一个为西班牙、德国、英国等地区的客户提供在线售票业务的平台。我们通常会将自己描述为活动组织者的技术伙伴,在整个活动期间为他们以及这些活动的参与者提供帮助。为了正确地理解ticketea的架构的设计原因,有必要指出,售票业务往往会面对爆炸式的访问量增长。一旦有某个热门活动开始出票,疯狂涌入的粉丝很可能会弄垮你的服务器。
ticketea的产品团队目前有16位成员负责产品的开发与维护,在这16人中有3位设计师、1位QA,其余的都是开发者。这些开发者通常都是全栈工程师或是多面手,不过在团队中也有一些专家。我们没有在团队中设立系统管理员的角色,主要原因有两点:一是我们依赖于某些AWS服务以托管项目,二是我们都遵从DevOps实践。无论是新机器的部署与设置,或是编排系统的操作以及内部开发工具的改进,这些工作都是由全体负责,而不是由具体哪一个人负责的。
围绕着一体化架构出现的第一颗卫星
ticketea目前已经经历了6年的发展,和许多创业公司一样,我们也是从一个简单的、更稳定的技术平台开始的。但随着时间的推移以及产品的持续发展,其中的某些部分必须要重做,才能够跟上不断增长的业务需求所提出的挑战。而其它的部分也得到了重构,以改善系统的健壮性与质量。这些改进让我们实现了高可用性,从而使那些依赖我们服务的组织者能够进行大型活动的票务销售。
在三年以前,ticketea的产品基本上还是一个一体化的解决方案,由于当时在技术上的一些限制与优势的原因而采取了这样的设计方案。基本的限制包括团队规模与资金,而优势则包括让新特性更快地推向市场、简化部署操作、保持运行整个产品所必需的基础设施的规模与投入、并且保证当时的每一位团队成员都能够完整地了解整个平台。
简单来说,我们有一套API和一个前端的web应用,这比起将全部功能塞到一个单一的web应用中的做法更好。一套独立的API已经是一个好的开端了。在2013年初,我们需要创建一套能够满足我们需求的商业智能解决方案,因此我们创建了Odin,它好像是在这个一体化架构中出现的一颗卫星,虽然它并没有完全地利用到这套API。之后,我们意识到一点,卫星的出现通常是一个信号,它表示我们应当转为面向服务的架构(SOA)了。
(点击放大图像)
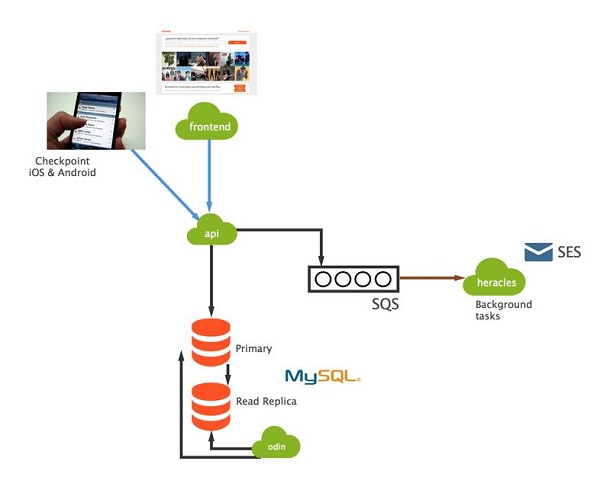
在Odin之后,我们又开发了一个后台任务执行系统Heracles,它依赖于一个RabbitMQ集群,在当时采用了Python Celery实现。我们废弃了之前自行开发的一个Ruby任务系统,它已经无法满足今后的工作需要处理的任务数量与粒度的需求了。
改变架构,选择分布式
但是,以上提到的这些项目只是首次使用了其它编程语言,并且开始对于某些部分实现了分布式,这始终只是隔靴搔痒而已。团队当时所面临的主要挑战之一是开始分解这个一体性的架构,而做到这一点并不容易。我们在内部将这一过程称为“从一体化到多体化(multilith)”。我们已经不记得“多体化”这个词是我们原创的还是从哪里听到的了,它表现的含义是你准备将一块巨石进行分解,但通常来说,在一开始时最大的那块石头一直分解到最后还是最大的一块。
(点击放大图像)
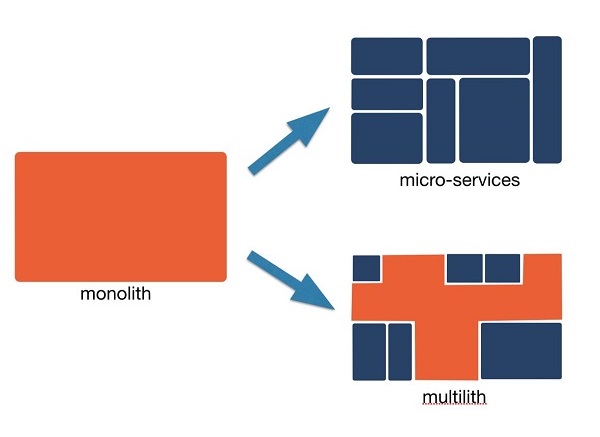
我们希望在此强调一点,即我们一开始的设计并不是一种糟糕的或者错误的设计。我们曾经看到一些开发者在技术会议上表示他们经历过的一些老系统有多么烂,而他们又是如何明智地从头开始进行重新设计的故事。就算这些故事是真的,他们在全新设计时也已经掌握了大量的有关问题领域的知识,而这些知识对于新的设计通常会带来正面的影响。很显然,创业公司的长期项目开发必然伴随着一些遗留代码、技术债和其它问题,但即使我们要分解这个一体性方案,整个系统的引擎也必须持续运转。因此,我们无法选择重写整个系统,而必须将这些问题逐个击破。
关于选择哪一部分作为突破口,以及如何启动新项目,这方面可以找到大量的相关讨论。最终我们决定为会场访问控制系统创建一个新的项目。ticketea所卖出的每张票上面都包含一个QR码,同时我们还将(为iOS和Android)提供一个名为Checkpoint的会场访问控制应用。购票者通过它能够下载验证会话信息、扫描QR码、并帮助你发送活动信息。Checkpoint将调用我们的API,当时的这套API没有经过分解,它包含了全部功能,而只对应一个单一的repository、和一个单一的PHP软件项目,整个项目很庞大、非常之庞大。
(点击放大图像)

但是,我们的存货系统(活动、会议、出票等等信息)与访问控制系统之间存在着一些通用的部分,它们之间需要进行同步,那怎样实现呢?我们在创建Thor系统时依赖于一个主要的组件,即队列系统。我们决定,通过RabbitMQ暴露库存API中的各种事件,让会场访问控制API从中获取各种通知信息。Thor再通过工作进程调用RabbitMQ中的信息交换并进行同步。我们创建了一个名为Thor(没错,我们借用了北欧神话中雷神索尔的名字)的repository项目。这是我们第一次在ticketea中创建Python API,它完全基于Django和Rest框架进行开发。你可能已经阅读过许多关于软件重写,以及这意味着什么的相关文章了。但对我们来说,这一组件的重写非常顺利,它获得了极大的成功。说实话,我们并没有彻底重写所有代码,数据模型并没有很大的改变,并且API终结点也保持不变,但内部实现得到了全面的调整,从而能够更好地响应并发与大型活动的需求,例如在西班牙的各种节日活动中,能支持几十万的参与者。这次的技术切分非常简单,因为验证与库存逻辑本身就是分离的,他们在语义上也适合分割成不同的API。
高可用性方面的关注
高可用性最近是一个很热门的概念,许多开发者对于它的描述给人的感觉仅仅是他们的团队如何处理产品的发展。但实际上,想要在分布式系统中实现高可用性需要观念上的改变,并且还伴随着额外的成本。举例来说,之前所讨论的架构实现面临着一些疑问:
- 如果负责对消息进行入队列操作的API线程在入队操作之后立即崩溃,却来不及提交事务,这时该怎么办? 实现分布式的 ACID 是一项困难的任务,因此你最终会进入一个名为 BASE (基本可用、软状态、最终一致性)的新世界,虽然它没有ACID那么完美,但却是必须的。为了实现最终一致性,你需要通过某种方式对系统进行重新同步,找到并清除不一致性。
- 如果RabbitMQ挂了怎么办? 好吧,关于分布式系统有一个经常被人提起的优势,即你可以避免发生单点失败的状况。但是,分布式系统是非常复杂的,而且当发生故障时往往会引起连锁反应,或者有时会发生多个部分同时故障的情况。因此,我们决定在Thor中还要建立一个同步的REST API。一旦存货API出现了不能入队列的情况,它就会转而调用HTTP请求,以作用后备方案。
- 如果所有组件都挂了呢? 在RabbitMQ和HTTP都不能工作的状态下该怎么办?那么你的这一天应当会过得相当充实。你需要为最坏的情况做好准备,因此我们创建了一个迁移工具,这个软件能够对库存数据库的一部分进行扫描,同时对Thor的数据库进行检查,以找到并修复其中不一致的地方。这也是为什么我们经常说,即使你有了一个A团队,也要准备一个B计划。
不仅开发者们需要了解如何在一个高可用性的系统中处理这些状况,并且你的DevOps工具链也将变得更为复杂,从而提高了你的运行成本。
选择分布式在技术上意味着什么
在选择分布式之前,首先准备好监控工具,这是一个好主意。事实上,我们认为这是一个必要的前提条件。如果你不对系统进行衡量,那么也很可能还没有为处理分布式系统做好准备。
你需要意识到你将面对更多的项目,这通常意味着比以往更多的机器、更多的技术栈、更复杂的内部依赖以及其他问题。如果没有监控机制,你将对系统的表现一无所知,因为现在的系统中比起以前存在着更多处于变化的部分。当你的系统各部分都揉合在一起的时候,主要的监控工作就是不断地ping你的机器,对系统进行心跳检测。然而,当你面对的是一个分布式系统时,仅仅了解你的系统是否在运行仍不足够,你还要注意网络方面的问题,以及你所依赖的服务状态等等。
即便如此,哪怕你已经对所有可变的部分有所了解,你也不能轻易地断定整个系统都处于正常工作状态了。或许你的队列还能够工作,但已经超负荷了,又或者你的工作进程已经无法处理所收到的任务了。为了保证一切尽在掌握,你必须做好以下几点:
- 集中式的日志记录 :在一个分布式系统中,请求很可能会发送至不同的服务中。为了在不同的系统中找到问题,或是出于衡量指标的原因要对某个用户的行为进行追踪,我们需要使用一个唯一的令牌,在所有的日志中都保存这一令牌信息。所有的日志将通过 rsyslog 进行收集,随后由 Logstash 进行处理,以允许我们对海量的日志记录进行搜索。
- 错误处理 :在ticketea内部,我们使用 Sentry 进行代码调用栈的日志记录,这让我们能够积极地找到bug并进行修复。
- 图形化 :我们还使用 Statsd 在 Graphite 中记录衡量指标,这些指标将在 Grafana 的仪表板中以友好的方式进行显示。举例来说,我们能够很方便地知道在这一段时期我们的支付系统的提供者的响应时间是多少,以此检测是否出现问题,有时还将促使我们更换提供者。
- 警告系统 :我们并不想整天盯着这些复杂的仪表板。由于我们已经收集了各种良好的指标(下单的次数、后台作业的队列大小、cronjobs的心跳检测数据等等),并且知道该用哪些阀值找到问题,因此我们就开始寻找某种警告系统,并最终找到了 Cabot 。现在,如果系统出了故障,就会有一条短信发给我们,把我们从睡梦中叫醒。
有了以上这些之后,你就能够知道系统什么时候会出错了,但并非总能知道错误的原因所在。调试与问题的修复比起在一体化系统中更困难了。某些问题并非来源于某个特定的项目,而是存在于某个“无人的荒漠中”,例如连接性故障,或者问题可能出现在你所连接的软件中。在这些情况下,开发者不得不离开他们所熟悉的环境,去其他项目中进行探索。
一个分布式系统同样难以在开发环境中复制。在ticketea内部,我们结合使用了 Vagrant 与 Ansible 以设置我们的开发环境,让他们尽可能地接近于生产系统。
举例来说,在ticketea系统中,一旦某个用户购买了一张票,我们就会将这一事件的详细信息记录在日志中。我们将通过一张图表显示用户在一天内购票所需时间的平均值,因此我们就能够判断系统的性能是否有下降,以及支付系统需要多少时间进行响应。我们将追踪这张票是免费的还是收费的,以及这张票所对应的活动是否有人数限制。只要系统可用,我们的购票系统就应当保持可用,但它如今需要处理一些不同的用例,因而变得更复杂了。
每次当我们进行部署时,都会在Sentry中跟踪未处理的代码异常。我们所拥有的警告系统对于它的阀值有一定的容忍度。这意味着如果购票系统由于逻辑出错而无法工作,同时又没有捕获到异常,那么警告系统将等待一段时间后再通知我们有状况发生。出于这一原因,每次在部署之后,我们都会仔细地对指标的仪表板进行监控。这样一来,我们立即就能够确定新的部署是否破坏了某些特性,或是产生了回归缺陷而需要进行回滚。
选择分布式对于团队来说意味着什么
选择分布式就意味着团队要充分地理解整个系统变得更困难了。同时,不必强制每个成员都理解整个系统,这样就更容易招聘新员工,并且仅让他们专注于系统的一小部分,从而让他们更快地上手。
不过,我们相信一个高度关注于产品的团队是十分重要的,因此我们推出了一些实践,让每个人都参与这一循环:
- 两周长度的SCRUM :这种方法能够帮助我们让团队专注于产品,我们遵循了大部分实践,例如每日站会、回顾会议以及产品演示,整个团队通过这些实践能够看到产品在其他方面是怎样改进的。
- 对于重要的架构改变进行讨论 :当我们需要对架构进行重要的改动时,这不再是一个人的决定,而是团队的决定。每个人都需要适应这一点,至少要理解决定背后的原因,并接受实现的方式。在这些讨论中,每个人都能够指出新概念中出现的问题,并且提出替代方案的建议。最后,团队对于讨论的内容将达成共识。
- 路线图会议 :我们在每个季度至少要开一次会议,以通知全体人员这个季度从业务的角度来看将完成哪些功能。虽然大家都了解全年的产品路线图,但我们发现这种会议能够确保大家都处于正轨上,并专注于正确的功能。开发者也能够得以理解他们工作的目的,以及对于整个公司的意义。
我们也清楚,一旦团队的规模扩大到了一定程度,再让整个团队参与这些会议就比较困难了。不过对于我们目前的规模来说,这种会议还是很有效的。对于一个成熟的团队来说,应当能够做到按照自身的需求及规模进行适当的调整。
一旦选择了分布式系统之后,我们的工作方式也要加以调整。某些成员将转入一些特定的项目开发,而不是让所有开发者都去接触相同的代码库。经过一段时间之后,这些成员将成为项目中的专家,我们也很快意识到需要让开发者们在不同的项目之间进行切换,以减少巴士系数(bus factor,字面上的意思就是有多少个关键开发者被车撞了之后会让项目停摆),并增进知识的共享。
因为不同的项目所用的技术栈不同,有些情况下就需要为开发者培训新语言的知识。我们尽力保证技术栈的数量能够控制在一个合理的数量之内。有时,某种技术可以取代一种现有的技术,并且能够在一定时期内共存,不过这种情况很少发生。
ticketea的开发者们大多数都是全栈工程师。举例来说,部分开发者的职责既有前端也有后端开发,有些人甚至还可以参与移动开发。显然有部分开发者在某个领域具有特长,那么其他人都可以向他们询问技术方面的问题。团队的成员不仅了解自身的长处,同时也了解他人的长处。
当团队在持续发展时,整个开发组织也在保持变化。在开始阶段,组织中仅包括CTO与开发者的角色。而当开发者的数量不断增长之后,就诞生了“设计师主管”与“开发者主管”这样的角色,以分担CTO的职责,这种方式也让组织的其他部分能够保持一个非常扁平的架构。
目前团队的成员已经超过了15人,我们正开始将团队组织为由5-7人组成的多个小型非独立团队。每个团队将设立一个主管,他们将与团队成员密切合作,以帮助他们提高生产力。例如帮助其他开发者调试问题,或仅仅是确保他们正在做正确的事。
总结
分布式系统能够带来诸多益处,我们可以针对不同需求的项目采用不同的编程语言。这也可以让某个项目中成员更容易理解整个项目,但也使他们理解整个系统的架构变得困难了。因此,接口就显得非常重要。API及其版本控制变得至关重要,因为他们提供了协议与通信点,让你的基础设施与团队都能够自由伸缩,并且还能够减少代码冲突、降低一次发布的规模以及多步骤的发布周期。如果你能够小心仔细地处理好这些问题,就能够以优雅地方式面对失败。举例来说,即使我们的访问控制系统在极端情况下挂了,售票系统依然能够正常运作。
虽然分布式架构有着这些益处,但也带来了更高的成本。分布式架构难以维护,在进行部署及编排等操作时也将遇到更多的困难。因此,在实现这种架构时,你需要意识到它的益处与成本。
关于作者
 a href="https://avatars3.githubusercontent.com/u/252257?v=3&s=400"> Miguel Araujo 目前在ticketea担任开发者主管。当他在马德里完成了计算机科学专业的课程之后,就作为自由职业者在各个创业公司参与工作。之后,他成为了一名全栈开发者,并积极地为开源软件贡献力量。他在三年前加入了ticketea公司,职责是让ticketea的技术栈采用更现代化的技术,并帮助它进行扩张,在欧洲地区打开新的市场。他热爱学习、面对工作上的挑战、以及用电器进行一些修补操作。
a href="https://avatars3.githubusercontent.com/u/252257?v=3&s=400"> Miguel Araujo 目前在ticketea担任开发者主管。当他在马德里完成了计算机科学专业的课程之后,就作为自由职业者在各个创业公司参与工作。之后,他成为了一名全栈开发者,并积极地为开源软件贡献力量。他在三年前加入了ticketea公司,职责是让ticketea的技术栈采用更现代化的技术,并帮助它进行扩张,在欧洲地区打开新的市场。他热爱学习、面对工作上的挑战、以及用电器进行一些修补操作。
 Jose Ignacio Galarza 目前在ticketea担任CTO。他在马德里获得了计算机科学专业的学位之后留在了大学里进行研究工作,随后在一些专注于产品的创业公司中担任开发者职务。他在三年前加入了ticketea公司,负责改进产品,并将ticketea的技术栈转变为具备更高伸缩性的分布式系统。他非常爱吃汉堡。
Jose Ignacio Galarza 目前在ticketea担任CTO。他在马德里获得了计算机科学专业的学位之后留在了大学里进行研究工作,随后在一些专注于产品的创业公司中担任开发者职务。他在三年前加入了ticketea公司,负责改进产品,并将ticketea的技术栈转变为具备更高伸缩性的分布式系统。他非常爱吃汉堡。
查看英文原文: From Monolith to Multilith at ticketea
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

