线性回归:预测上海车牌成交价格
上海是全国最早实行私人轿车牌照拍卖方式来控制交通流量的城市,需要通过投标拍卖的形式购买车牌。
而车牌的拍卖并不是简单的价高者得,服务器只接受最低可成交价上下300元区间内的出价,意思就是说,如果现在最低成交价是60000,你出价范围必须在57000~63000之间,并且这个最低成交价是在不断变化的,到了最后几分价格上涨太快根本来不及操作。
如果能提前根据历年数据预测本次拍卖成交价格,那么成功率必定比盲拍要高很多。
下面就尝试使用 scikit-learn 这个机器学习工具库来进行价格预测。
收集数据
在 上海国拍竞标网 等其他公告网站收集到了最近几年的完整拍卖记录:

另外,一些重要的政策搜集也很重要,如果出现异常值可以剔除:
- 2013年4月,开始有最低警示价的约束。
- 2013年10月,取消警示价。
- 2013年11月,重启警示价。
- 2014年1月,试行车牌拍卖年度统一警示价72600元。同时,将实行个人、单位分场拍卖。
- 2014年4月,投标卡参拍增至6次。
- 2014年7月,拍牌者必须提交驾驶证件。
- 2014年11月,二手车牌照不能私下交易,买卖纳入统一拍卖平台。
- 2015年1月,警示价设定标准为剔除价格波动异常月份后,取最近三个月拍卖成交均价的加权平均值。
加载数据
数据和政策都收集好了,接下来就是数据预处理部分。预处理主要是读取数据并除掉无用的列,重命名中文列名等等:
df = pd.read_csv('data.csv')
df.rename(columns={'拍卖时间':'date','投放数量':'number',/
'警示价':'start','最低成交价':'low',
'平均成交价':'mean','投标人数':'enrollment'},
inplace=True)
df = df[['date','number','start','low','mean','enrollment']]
df = df[:-1]
这是浏览一下数据大概是这样的:
| date | number | start | low | mean | enrollment | |
|---|---|---|---|---|---|---|
| 0 | 2013-4 | 11000 | 83600 | 83900 | 84101 | 26174 |
| 1 | 2013-5 | 9000 | 79900 | 80700 | 80803 | 222243 |
| … | … | … | … | … | … | |
| 33 | 2016-2 | 8363 | 80600 | 83200 | 83244 | 196470 |
初步观察
我们可以初步浏览一下数据的关联度。将发放的车牌数、警示价、最低成交价、参与人数四个数据作为 x 变量,将平均成交价作为 y 变量,绘制他们的散点图观察分布情况:
import seaborn as sns
%matplotlib inline
sns.pairplot(df,x_vars=['number','start','low','enrollment'],y_vars='mean',size=7,kind='reg')
结果如下:
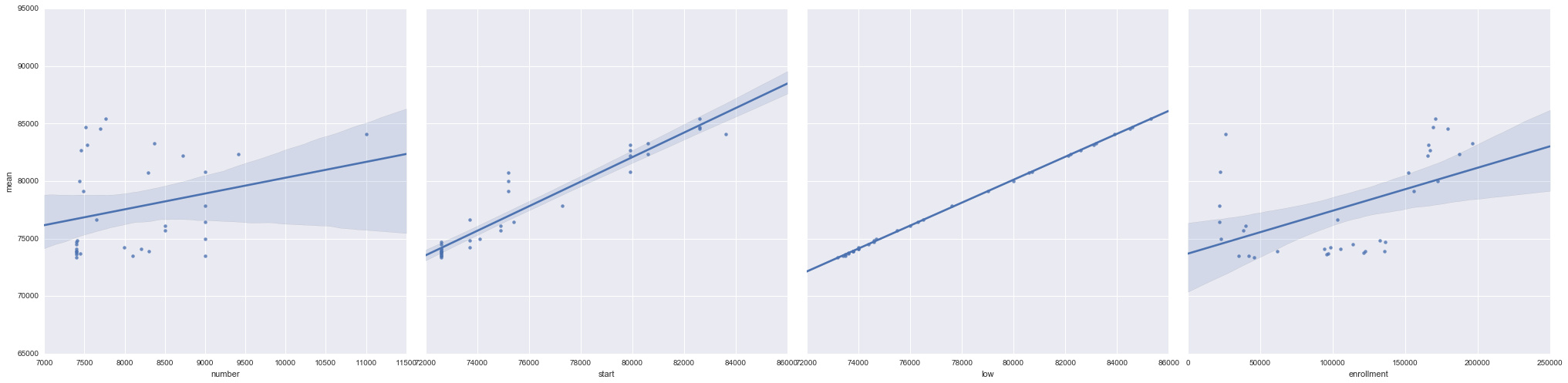
我看见了什么!一条直线!这简直就是完美吻合啊!

定睛一看,是最低成交价。

这本就该完美吻合,最低成交价不会比平均成交价低超过300元。
然后再想一下,在预测价格的时候,我们可以获取到的数据是:
- 日期:2016-3
- 投放数量:8310
- 警示价:80600
- 投标人数:目前未知,当天可知,假设为 200000
所以我们需要关注的是:投放数量、警示价、投标人数,之间的关系。
单独绘制警示价和成交均价的柱状图:
df.plot(y=['start','mean'],kind='Bar',figsize=[16,6])
观察一下警示价与成交均价之间的关系:

似乎差值十分接近啊,将每个月的差值单独绘制看看:
df['mean-start'] = df['mean']-df['start']
ax = df.plot(y=['mean-start'],figsize=(16,6))
ax.set_xticks(df.index)
ax.set_xticklabels(df.date,rotation=90)
绘制结果如下:

本来差值稳定在1000左右,结果到了2015年突然失去了控制。可能和人数陡增有关,也有可能和某些政策出台有关,暂且就先这样。
线性回归
我们先用最基础的线性回归模型来测试一下。
首先先把 X 和 y 单独取出来,选择投放数量、警示价、投标人数作为 X 变量,将成交均价作为 y 变量:
feature_cols = ['number', 'start', 'enrollment']
X = df[feature_cols]
y = df['mean']
然后区分训练集和测试集:
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)
print X_train.shape # (25,3)
print y_train.shape # (25,)
print X_test.shape # (9,3)
print y_test.shape # (9,)
然后进行线性回归分析:
from sklearn.linear_model import LinearRegression
linreg = LinearRegression()
linreg.fit(X_train, y_train)
看一下各个特征的系数:
print linreg.intercept_
# 991.359968817
zip(feature_cols, linreg.coef_)
# [('number', 0.31616020072308526),
# ('start', 0.9541013878172625),
# ('enrollment', 0.015502778511636449)]
也就是说,最后的公式是:
y = 991.36 + 0.316 投放数量 + 0.954 警示价 + 0.0155 * 投标人数
这个结果合情合理,和我们一开始观察数据的结果接近。
接下来评测一下这个模型的准确性,用模型预测测试数据集,计算预测结果和真实结果的 RMSE 值:
from sklearn import metrics
y_pred = linreg.predict(X_test)
zip(y_test,y_pred)
print np.sqrt(metrics.mean_squared_error(y_test, y_pred))
计算结果是:RMSE = 1174.38,并不是很理想。RMSE 可以用于模型评价,后面优化参数的时候可以进行模型之间的对比。
直观对比一下原始数据和预测数据:
fig, ax = plt.subplots()
x = np.arange(len(y_test))
ax.bar(x,y_test-y_pred,width=w)
fig.show()
显示结果如下:
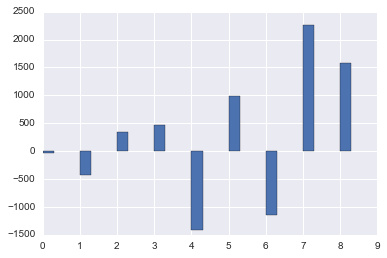
而理论上,误差值不能超过300才能抢到牌照。可见预测的结果并没太多作用。
观察到模型中投标人数的影响似乎不是很大,不妨把投标人数从模型中去除,看看结果如何:
feature_cols = ['number', 'start']
X = df[feature_cols]
y = df['mean']
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)
linreg.fit(X_train, y_train)
y_pred = linreg.predict(X_test)
print np.sqrt(metrics.mean_squared_error(y_test, y_pred))
计算结果是:RMSE = 1318.04,似乎误差更大了。
模型虽然不准,不过预测一下2016年3月的成交均价还是可以的。从公告来看,发放牌照8310张,警示价80600,假设参与人数为20000,那么预计成交价:
linreg.predict([[8310,80600,200000]])
结果是:83619.78 元。
小结
在 Coursera 上跟着学 Machine Learning 也有段时间了,一直是跟着教程使用 GraphLab Create 来做。今天第一次用 scikit-learn 进行数据分析,即使是最最最简单的线性回归也是一路磕磕绊绊,学艺不精呐。
如果有更好的想法欢迎和我交流:)
从结果来看,这个模型预测的结果误差会在 2000 元以内,并不能达到最后需要的 300 元的要求,只能使用其他方法来解决了。
预知后事如何。
我解决了也不会告诉你。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

