点击模型:提升算法精度的利器
在搜索、推荐、广告引擎中,系统会通过复杂算法生成一个最终的结果列表。用户在看到这个结果列表时,未必都会对排序满意,比如有时觉得排序的顺序有问题,或者发现一些不符合喜好的item。如果从算法层面来调优,总会有按住葫芦起了瓢的感觉,优化了某些bad case的同时,会带来新的bad case,这种情况下,往往就需要点击模型来在“近线端”进行修正。通过用户的点击反馈,可以从算法的另一个层面,对结果进行调优:将符合用户偏好但位置靠后的item提取至前,或者将不符合用户意图的item降权减分。达观数据在引擎架构研发实践中,大量使用到了点击模型,通过与用户的隐性交互,大幅提升了算法效果,积累了丰富的实战经验。
点击模型概述
随着大数据技术的发展,互联网上的数据呈现暴发式增长,通过收集海量用户行为数据,尤其是点击数据,能够更好地预测用户行为和挖掘用户需求。在机器学习领域的训练数据也不再仅仅是通过费时费力的人工标注方式获取,而是更多地基于点击反馈进行样本收集,既减少了数据获取成本,又保证了最新的时效性。
点击模型通过获取用户的历史点击,为用户行为进行建模,在模拟出用户的点击偏好后,能够最大程度优化系统效果。用户的点击行为都有一定的规律性,遵循这些规律,基于如下的假设,我们可以建立起用户的点击模型:
- 用户的浏览总是按某种顺序查看的,第一眼容易看到的结果会获得更多关注;
- 用户觉得标题、图片、摘要等初步满足了需求的结果,才会有可能点击查看;
- 如果某一个结果项完全满足了用户的需求,则再看其他项的可能性会比较低;
- 被点击越多的结果,越可能是好结果;
- 最后一次点击的结果往往是最好的结果,其次是第一次点击的结果;
等等。
点击模型挑战和难点
利用点击行为的假设,容易构建出初步的点击模型。但在实际应用中,一个好的模型需要面临和解决大量的挑战和难点,包括:
第一大问题是位置偏向(position bias)。因为用户点击会容易受到位置偏向的影响,排序在前的结果更容易获得用户的点击,在实际的应用中,一般会对点击偏向作一些惩罚,比如排在前列的结果被用户跳过了,将会比后面被跳过的结果降权更多;用户进行了翻页操作,上一页的结果都会获得减分处理。
第二大问题是冷启动问题。即新项目、新广告的点击预测问题。经常使用的方法是通过已有的点击反馈数据,挖掘学习出其中的规律,从而可以对新出现的项目,预测用户对它们可能的点击行为。
第三大问题是感知相关性。用户对结果的点击反馈很大程度是基于标题、图片、摘要等感官获取,具有很强的第一主观意识,很多时候并不能正确反映结果的有效性,但点击日志数据经常并不能获得用户对展示项“真实”的满意相关性数据,因此在基于现有的“感观性”数据之上,需要从其他方面进行补充,比如用户点击结果后的后续操作(点击商品后加购物车,点击书籍后加书架等),或者引入除点击率外的满意率等参数来构建点击模型。
第四大问题是稀疏性。在搜索排序中,点击数据一般只覆盖到排序结果的前面几页,容易出现长尾覆盖不足的问题,推荐和广告引擎中也经常会有物品冷门而不会被点击到。此外点击数太少也容易导致点击数据不可靠。因此除了使用一些平均值或预测值对数据进行补充外,经常也要对稀疏数据进行平滑处理。
第五大问题是点击作弊。因为点击行为容易生成,作弊者通常会使用模仿用户点击的行为进行对系统进行攻击,比如使用机器人对某个位置进行重复点击等。像这种情况下就需要识别出作弊数据,以免对系统结果产生人为的干扰。
第六大问题是Session收集。用户的session信息非常关键,它记录了用户在进入页面、查看结果、点击结果以及后继的操作(比如翻页、加购物车等)。只有通过session信息才能把用户的行为联系起来,构建出完整的模型,因此从海量数据中把每一个用户所有session的操作都完整地挖掘出来非常重要。
点击模型的类型
针对点击模型的研究非常多,很多种类的模型也被提出并应用到了实践中,现举一些常见的点击模型类型:
1)位置模型(position model)
位置模型考虑到每个用户对每个item位置都会有一定的查看概率(Examination),只有查看到该item后用户才会有一定概率点击。因此某个用户对某个位置的点击概率计算如下:
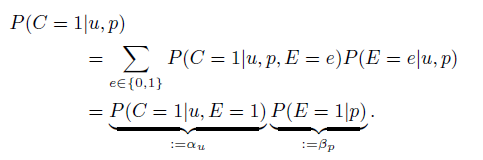
其中的βp表示的是在位置p上被查看到的概率(与用户无关),αu表示的是用户u在查看到某个item后点击的概率(与位置无关)。αu和βp的值可以根据用户历史点击记录,通过平均值法、极大似然法等方法计算。
2)瀑布模型(cascade model)
瀑布模型考虑到在同一个排序列表里的item的位置依赖关系,它假设用户从上至下依次查看页面里的item,如果结果满意就会进行点击,然后该session结束;否则跳过该项继续向后查看。第i个位置的item点击概率计算如下:
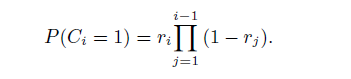
其中的ri表示第i个文档被点击的概率。
3)CCM模型
位置模型和瀑布模型都未考虑同一个session中不同排序结果之间的互相影响,考虑到如下情况:假如第一个和第二个item都非常符合用户偏好,那后续item的查看概率及点击概率将会减少;相反,如果前面几个item效果非常差,则后面的item将获得更高的查看和点击机会。CCM模型假设用户可以在对某一个item满意后,也还会继续查看后续结果;并且第j个排序结果的查看(Examination)和点击(Click)会影响到对第j+1个排序结果的行为:
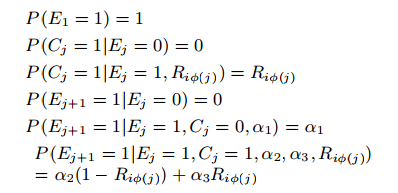
4)贝叶斯模型(DBN)
贝叶斯模型引入了满意度(satisfied rate)的概念,它考虑到用户点击了某一个item未必表示对它满意,点击代表了“感知相关性”,满意则代表了“真实相关性”,贝叶斯模型很好地把这两个相关性区分了开来。根据DBN的理论,具体模型图及原理如下:
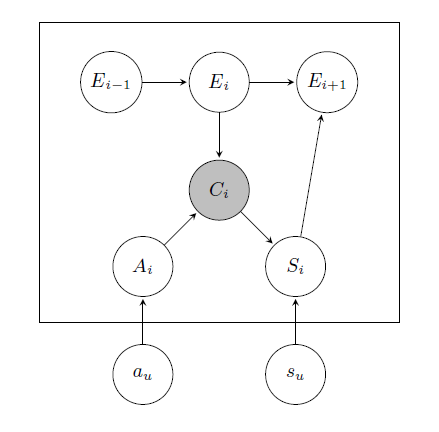
图1 贝叶斯模型
Ei表示用户是否查看了第i个item;Ai 表示用户是否被第i个item吸引;Si表示用户点击第i个item后是否对这个结果满意;Ci表示用户是否点击了第i个item。因此每个操作的关系传递如下:
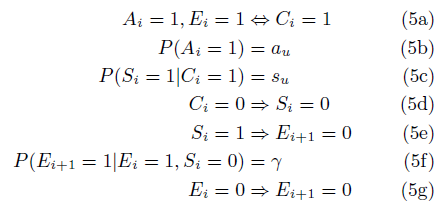
另外还有几个重要的参数:γ表示用户对当前第i个结果不满意后,查看下一条结果的概率;au表示用户对该结果的感知相关性,吸引用户进行点击;su表示用户点击item后,对其满意的相关性。au和su都存在一个Beta先验概率,指定γ后,可以通过EM算法计算出au和su的值。特别地,如果指定γ为1,表示用户会一直向后查看item,直到找到满意的结果为止,这时通过页面最后一个点击的位置,就能确定查看过的items(最后点击位置以上)和未查看过的items(最后点击位置以下),此时不用EM算法就能计算出au和su参数值,以α和β表示的相应的先验概率,计算au和su的方法简化为:
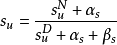
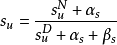
点击模型的相关性分数可以简单计算为:ru = au * su,意义表示为用户被结果吸引后,点击查看并对其满意的概率。
5)UBN模型
与CCM和DBN模型不同的是,UBN模型没有采用瀑布模型的假设,而是假设用户对某个位置i上的结果查看的概率,不仅受到位置的影响,还受到在同一个session内在之前某个位置点击过的item的影响。引入γrd表示用户在r-d位置点击后,查看r位置item的概率:
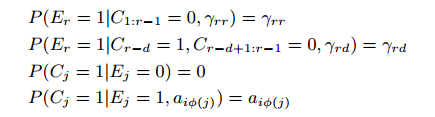
其中Ci:j = 0表示Ci = Ci+1 = · · · = Cj = 0。
如何运用点击模型来提升算法效果
点击模型经常应用于各类系统以提升算法效果,现就以搜索、推荐、广告以及数据挖掘中的各种使用场景介绍:
1)搜索系统
在搜索系统中,点击模型可以有如下集成方式:直接用在排序中,如将点击模型相关性分数简单加权在“近线端”,可以直接调整结果的排序位置;也可以通过学习排序的方式,样本获取是将排序页面的被点击item作为正样本,展示了但未点击的item作为负样本,每天积累起足够多的训练样本。通过选取丰富的特征,可以使用分类器学习出合适的排序模型。这些丰富的特征包括查询词在文档中的词频信息、查询词的IDF信息、文档长度、网页的入链数量、网页的pageRank值、査询词的Proximity值等等,能够充分体现查询Query和文档之间的联系。在用户下一次查询时,可以通过分类器来预估新的排序结果。
2)推荐系统
推荐系统在计算推荐结果时,也大量使用到了点击模型。比如协同过滤算法中,如果没有显性的评分机制,就需要收集点击的行为来作为正向的评分。不同类型的点击(如查看、加购物车、加关注等)可以生成不同维度的二维相似度矩阵,最后推荐的结果由这些矩阵计算生成的中间结果加权得到。推荐系统也可以在“近线端”进行调权,如用户点击过“不喜欢”过的物品,下次就不会再推荐展示;或者通过点击反馈实时调整切换算法,对不同的用户调整使用不同的算法引擎,达到最大的效果收益。
3)广告引擎
广告引擎中使用最多的就是CTR预估了。CTR预估使用到LR模型,因为它算法简单,运算速度快,输出0~1的概率值,正好符合广告引擎的需求。广告选取的特征也很丰富,在用户层面包括用户的性别、年龄、地域等,广告层面则包括广告大小、广告类别、广告文本、广告所属的行业等。广告引擎使用的样本也是基于点击反馈收集,用户点击的广告作为正样本,用户查看了但未点击的广告作为负样本。收集到足够多的样本后,使用LR训练出一个最优的模型。在用户查询广告时,LR模型通过用户和候选广告的特征,预测出各候选广告被用户点击的概率,这个计算出的预估概率是广告引擎中十分重要的分数结果,对广告排名展现起了决定性的作用。
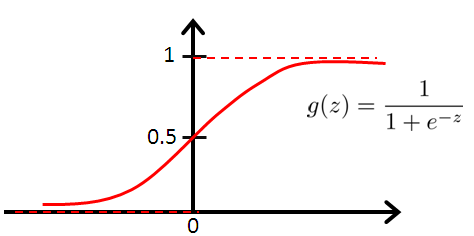
图2 Logistic Regression模型
点击模型系统架构
一般来说,点击模型需要大量采集用户点击位置、页面浏览时长、页面关闭、点击次数等交互信息。采集的大量数据在进行数据清洗,以及反作弊处理后,才能得到有效的点击数据,为后续数据分析挖掘提供支持。
1)数据采集模块
点击模型数据采集是非常重要的模块,因为所有原始数据都是从这导入。在移动端和pc端的采集还略有不同,目前移动端主要使用的是SDK采集,将SDK植入在APP内,由业务端调用接口上报采集数据;而pc端一般是将js植入到页面中,用户的每一次重要的行为都会触发数据上报。移动端和PC端数据汇集打通后,才能发挥数据的最大价值。上报的数据通过数据采集模块进入系统后,因为存在大量的格式不合法的数据、损坏的数据等,需要进行烦琐的数据清洗阶段。去除掉这些脏数据后,比较正常的数据才会进入数据仓库进行下一步的处理。
2)数据挖掘模块
在数据仓库中进行数据反作弊和数据挖掘处理时,由于数据量过于巨大,通常都会使用集群运算。通过反作弊算法排除掉伪造数据后,使用数据挖掘模块对点击展现数据进行处理,最终生成各种巨大潜在价值的数据结果。这些结果不仅包括点击模型,还有其他丰富的数据产品,包括数据关联信息、数据预测、数据报表等。
3)系统集成
点击数据挖掘的成果又会回馈到引擎架构中,优化系统的算法,提升整体效果。而新的点击模型作用下的用户点击结果又会在下一次的数据采集中被收集到,形成了闭环的回路。整个闭环图如下所示:
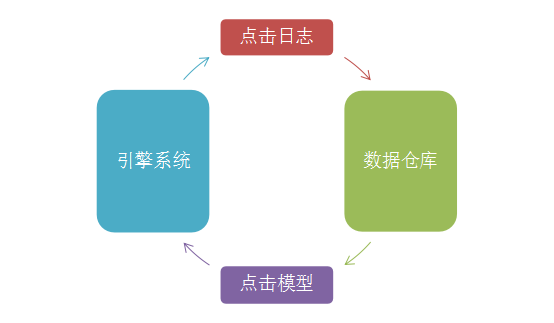
图3 点击模型系统架构
点击模型反作弊
点击模型对结果的排序起了至关重要的作用,因此也是容易受到攻击的部分。攻击的目的无非是两种,一个是提高目标物品的排名(推举攻击),另一种是降低目标物品的排名(打压攻击)。用户对系统的攻击一般是通过点击插入伪造数据产生的,因此基本的对策也是对用户恶性点击结果的识别和反作弊。
1)基于规则的识别
传统的反作弊是基于规则的识别,比如cookie去重、IP防作弊:通过记录监测cookie、ip的重复行为,防止同一用户/设备在某个时间段内多次点击同一个位置;有效期设置:限制某个展现/点击的有效期,在有效期内的转化属于合理收益,超过有效期的操作会作废弃处理;黑名单处理:在某些周期性的作弊行为,超过一定范围后可以标记为黑名单,用来长期过滤,以免其持续性攻击系统。基于规则的反作弊可以有很多种方法,因业务而异,需要对具体攻击行为而作出相应的对策。
2)分类方法
然而现如今的攻击手段已经非常多样化了,简单的基于规则的反作弊不足以有效的识别攻击者,因此需要更复杂的基于机器学习的方法来区分真实点击和伪造点击。比如使用有监督学习的方法,通过人工标注点击,或者人造伪造记录来训练分类器。由于点击数据样本类型多、数量大、维度高,因此使用的记录特征都是用聚合方法生成的,这些特征不是普通的记录属性,而是包含了各种统计量的信息特征。通过有监督学习这种方法,能够识别出大量不能通过规则辨别的攻击行为。
3)聚类方法
聚类方法主要用于识别系统中的多个用户联合起来进行攻击的情景。这些攻击的用户群一般攻击行为都会很相似很异常,而且经常会攻击很多个item。在反作弊模块中,通过聚类把正常行为和异常行为聚类区分出来,然后将异常行为的点击、评分等操作从计算点击模型的数据集合中移除。聚类方法尤其能够有效地阻止“群托”这类攻击者行为。
4)信息论方法
通过样本的信息变化来检测作弊者也是一个有效的方法。可以检测一段时间内某些物品的一些评分值来探测异常,如描述物品随时间变化的样本均值、物品评分值分布变化的样本熵等。通过在有限的时间窗口内观察各种信息值的变化,比较容易探测到攻击者的行为。
使用机器方法能有效识别出大部分基于规则无法解决的问题,增加攻击者的作弊难度,然而点击反作弊是一个与恶意攻击者斗智斗勇的过程,简单的一两个方法并不能完全解决作弊的问题,经常会使用多种方法组合到一起,如基于规则的方法首先排除掉大部分简单攻击,然后后端再组合多种机器学习方法识别出更复杂的作弊记录。因为攻击者的攻击方法一直都在持续升级,所谓“道高一尺,魔高一丈”,反作弊也要不断改进策略才能有效地阻止作弊者。
点击模型效果评估
评估搜索、推荐、广告效果的好坏有很多指标,包括通过点击位置计算的MRR、MAP分数,由点击的结果计算的准确率、召回率、长尾覆盖率等。在搜索、广告和推荐引擎的研发过程中,达观数据一直进行着充分缜密的数据评估,以保证每一次算法升级后的效果。以MRR和MAP分数评估为例,这两种分数的计算方式一直是信息检索领域评估算法好坏的重要指标:
1)MAP(mean average precision)
MAP为每个查询的相关排序结果赋予一个评价数字,然后对这些数字进行平均。比如q1对应相关的d排名是1,2,5,7(假设q1有4个相关d),那么对于q1的ap(average precision)的计算就是(1/1+2/2+3/5+4/7)/4 = ap1,对于q2的排序结果结果中与之相关的d的排名是2,3,6(假设q2有5个相关d),那么对于q2的ap就是(1/2+2/3+3/6+0+0)/5 = ap2,那么这个排序算法的MAP就是(ap1+ap2)/2;
在达观搜索引擎中,对原系统和使用点击模型后的MAP分数对比如下:

图4 使用点击模型的map分数比较
2)MRR(mean reciprocal rank)
MRR的评估假设是基于唯一的一个相关结果,比如q1的最相关是排在第3位,q2的最相关是在第4位,那么MRR=(1/3+1/4)/ 2。
在达观搜索引擎中,对原系统和使用点击模型后的MRR分数对比如下:
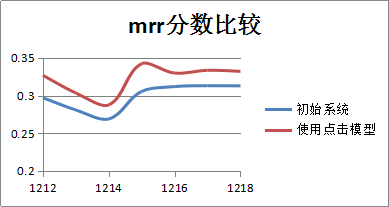
图5 使用点击模型后的mrr分数比较
由效果图可以看到,使用点击模型后系统的性能得到了近30%的大幅度提升。除此之外,使用NDCG、F值、长尾覆盖率等评估方式,都能看到点击模型的应用会对系统带来一定的效果收益。在搜索引擎、智能推荐、广告系统中,使用点击模型后,系统的效果都会得到令人满意的提高。
结语
在大数据公司里,点击模型都是搜索、推荐、广告系统使用的利器,对优化算法模型,达到“千人千面”的个性化效果都是必不可少的。点击模型在数据挖掘领域是热门研究问题,随着大数据发展出现了各种新技术和解决方案。
作者介绍
江永青,浙江大学软件工程专业硕士,现任达观数据联合创始人,曾在盛大创新院搜索组负责索引和检索模块,盛大文学部分负责数据平台架构和智能审核系统模块。对搜索系统,大数据平台,机器学习有较丰富的实践经验。
感谢杜小芳对本文的审校。
给InfoQ中文站投稿或者参与内容翻译工作,请邮件至editors@cn.infoq.com。也欢迎大家通过新浪微博(@InfoQ,@丁晓昀),微信(微信号: InfoQChina )关注我们。
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

