达达日志系统(一)收集
随着达达业务迅猛发展,访问量的节节攀升,每天产生大量的日志,单日日志量从原来的约20G/天涨到超过500G/天,我们面临着新的架构设计挑战。
在提出解决方案之前,我们先来了解一下达达当前的日志现状:
1. 日志种类繁多
需要收集的日志包含:
- Nginx的访问日志
- Tomcat的访问日志
- 应用程序的业务日志
- 其他日志:移动App的日志,达达快递员位移的日志等等
2. 海量的日志记录,接近TB级别
随着系统功能越来越多,访问量的增长,记录的日志也越来越多,越来越大。高峰时期,单日日志文件大小超过500G,接近TB级别。
3. 日志的高度分散
日志的高度分散主要体现在几个方面:
- 日志分散在多台主机上
- 日志分散在主机的多个文件中
- 日志分散不同语言的不同应用中,主要是Python和Java应用
同时,日志的高度分散导致通过日志来分析线上问题变得越来越困难,不能清晰的定位一个请求的相关日志记录位于哪台主机上。
4. 日志的快速增长
在最近半年中随着达达订单量从几万到百万单,日志量更是呈指数级增长。
5. 通过分析海量的日志记录来监控系统的状态
随着系统的压力越来越大,通过分析海量的日志来实时获取系统当前的状态,变得越来越迫切。同时,随着系统功能的越来越多,离线分析当前的系统的功能设计及为未来的扩容提供参考,变得越来越重要。
问题
在了解了当前达达日志现状后,对于日志收集面临的挑战,越来越清晰:
- 如何收集多台主机上的多个日志文件?
- 如何来解决日志的快速增长和日志的海量存储?
- 如何来支持不同编程语言应用的,不同种类的日志的收集?
- 如何来通过日志来实时及离线分析系统的状态(性能指标等)?
达达的日志量增长图,如下:

达达的日志行数增长图,如下

达达日志收集架构
为了解决上述的问题,达达采用Apache的成熟组件Flume和Kafka来实现这一套日志采集系统,并使用HDFS来做数据存储。
数据采集采用Flume
业务的快速增加必然带来多种日志来源,Flume有着非常成熟且丰富的Agent组件用于收集,聚合处理本地日志文件。Flume是分布式且可靠的用于收集,聚合,迁移大日志数据的服务。它有许多特点: 分布式且可靠性强,基于流式数据的简易且灵活架构,健壮且容错性强,有可恢复机制,使用简单可扩展的数据模型用于各种分析应用。
一个完整的Flume Agent包括3大组件:source,channel,sink,数据(source)流入channel,而后从channel流入sink。详细流转如下图:
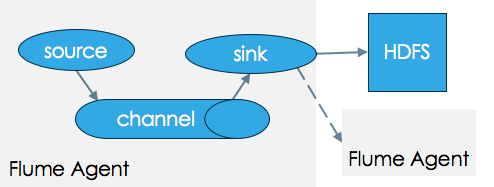
详细的数据流过程参见 Flume用户指南
日志消息采用Kafka
快速的日志增长必然会挑战系统的吞吐能力,尤其是在达达的配送业务80%是发生在高峰期,这意味着系统必须能在高峰期面对飙升的海量日志,因此,使用缓冲队列是必要的。使用Kafka作为系统的缓冲地带,可以很好的支持系统的运行。Kafka是分布式消息发布订阅系统,它的主要特性如下:
- 单broker可以每秒处理百万次读写,每一个broker可以在性能没有影响的情况下处理TB级消息
- 数据是以分区的格式存储在整个集群中; 消息持久化在磁盘上,且有多个备份,不会造成数据丢失
- Kafka可以不宕机地,透明地扩展,提供强持久性和容错性保证
存储采采用HDFS
快速增长的日志,必然需要扩容,而HDFS的高容错,大数据处理特性可以可以很好的解决海量日志存储问题和快速增长带来的扩容问题。HDFS和离线分析工具(HIVE)可以很好的结合,也可以支持HBase做到近实时分析。
现在系统负责所有系统和业务的日志收集工作,收集的日志用于实时在线分析和离线分析,最高峰一天处理的数据接近TB级。
达达日志收集架构如下图:
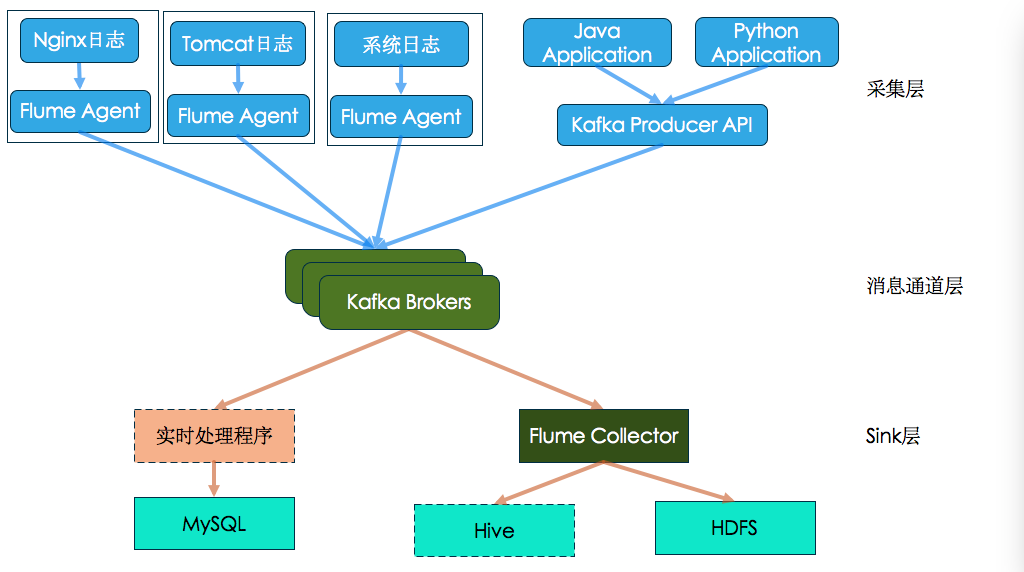
采集层
Flume Agent组件
- 散落在各个服务器上的各种日志,通过Flume Agent统一收集
- Agent使用tail方式来收集本地日志文件,并使用文件作为通道,目的是保证消息不丢失,文件通道默认保留最大日志量为2G
- Flume Agent在收集本地日志后,再发送日志消息到Kafka
Kafka Producer API
- Kafka支持多种客户端,包括Python和Java客户端
- 达达提供Python和Java两种客户端API来支持消息的发送
- 由Python和Java应用内直接通过Kafka Producer API发送日志消息
消息通道层
Kafka Brokers
日志消息的处理过程:
- 日志消息经由Flume Agent和Kafka Producer API,统一汇聚到Kafka Broker
- 通过Kafka Topic,可以无缝接入应用程序处理日志消息,也可以隔离不同类型的日志
Sink层
Flume Collector
- 使用KafkaSource接收来自Kafka的消息,
- 接收到日志消息,先缓冲到文件通道,最大保证消息不丢失
- 在通过HdfsSink消费日志消息,存储到HDFS
- 开启LZO压缩,在存储到HDFS前,先使用LZO压缩日志数据,一天的日志文件大小减少60%,使得IO消耗更少
实时处理程序
- 接收来自Kafka的日志消息,供给实时处理程序来做实时分析,例如Storm
- 通过Kafka Topic无缝接入其他实时处理程序
引入新的架构,解决了海量日志收集的难点,所有日志集中在一起,可迅速找到日志排查问题。统一汇聚所有日志消息,为后续的实时处理和离线处理打下了坚实的基础。
生产中遇到的问题
KafkaSink空转致CPU使用率100%
在我们部署Flume Agent时,发现客户端机器在没有日志时,CPU使用率升的很快,查看KafkaSink的源码时,发现在没有消息事件时,KafkaSink会导致空转,从而导致CPU使用率飙升。
解决方法是判断已处理的事件总数为0时,状态置为 BACKOFF ,关键代码如下:
if (event == null) {
// no events available in channel
if(processedEvents == 0) {
result = Status.BACKOFF;
counter.incrementBatchEmptyCount();
} else {
counter.incrementBatchUnderflowCount();
}
break;
}
详情见 FLUME-2632: High CPU on KafkaSink
Flume临时文件不关闭导致服务端收集程序不能正常工作
Flume按小时生成的目录下,最后的临时文件总是不能正常关闭,产生大量的.tmp文件,导致Flume服务端线程数超过1024,从而服务端数据不能正常收集数据。
解决方法是扩展 HDFSEventSink ,增加异步关闭临时文件,关键代码如下:
// compare with last file, it's new created,
// try to check lastProcessFile
if (!StringUtils.equals(lastProcessFile, currentLookupPath)) {
// lastProcessFile is still on open status
if (sfWriters.containsKey(lastProcessFile)) {
try {
final String ff = lastProcessFile;
checkWithTimeout(ff, new Callable<Integer>() {
public Integer call() throws Exception {
sfWriters.get(ff).close(true);
return 1;
}
});
} catch (Exception e) {
logger.error("checkWithTimeout error.", e);
}
}
}
日志系统进阶
日志收集系统强有力的支持了达达的业务系统,解决了海量日志收集和存储的难题,当然,收集日志仅是日志处理的第一步,如何对海量数据进行有效处理,是一个新的挑战,接下来,我们将介绍达达日志实时处理系统及离线处理系统。
达达实时处理系统实时的对线上日志进行处理,比如发现并屏蔽恶意访问,发现系统故障并报警,屏蔽作弊行为,以此保障业务系统健康运行。
离线处理系统则进行大数据分析,比如分析用户在App中的点击行为来优化产品功能,以及进一步分析用户喜好,调整运营策略。
更多关于日志系统的介绍,敬请关注达达技术博客。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

