数据整合式迁移的一些总结
说起数据迁移,感觉也算是有些感受了,但是最近参与的几个迁移案例还是和以前大大不同,以前的迁移项目是比拼停机维护时间,尽可能在短时间诶导入大批量的数据,有参与表空间传输的场景,还有跨平台的数据迁移,数据库迁移式升级等等,相对难度大一些的算是增量数据的迁移场景。为此也算把sqlldr,datapump和exp/imp玩了一圈,最后写了一个小的工具使用外部表迁移,也算是有了一些谈资。
最近的迁移项目还是有些特殊,有schema级别的迁移,这种情况数据库版本的影响就没有那么大了,基本就是schema级别的平移,这种听起来还算容易,有些场景是同名schema,同名表的整合,这种情况就有些让人头疼,每个owner用户可能有若干个连接用户,还需要考虑每个连接用户的权限和对应关系。有些用户如果整合起来重合度够高,还需要调整用户名。
像比如下面的迁移场景,其实难度基本都不在数据量上,而在在整合的难度上,这个时候数据迁移基本上就成了整合。
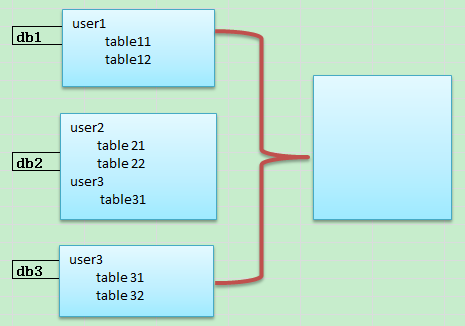
如果把上面三个数据库整合起来,其实也有几种方式,在11g中直接就是schema复制,导出导入即可,对于冲突重复的schema可能需要逐个确认,要不就是省事一些,直接修改用户名加以区分。
还有一种方案是放在12c的pdb里面。其实这种方式看起来还是能够解决大部分的兼容问题,但是个人感觉这种方式有个缺点就是会把原来的问题包装起来,原来的不规范的数据设计我们只是把它整合在一个数据库里,哪些问题还是问题,不规范还是不规范,如果其中一个pdb出现了大的性能抖动,影响是全局的。还有就是R2版本还为发布,在生产上使用还是存在一点的顾虑,不过那种方式有个很明显的优点就是省事。对于测试环境的整合还是一种好的方式。
所以现在重点已经不在于数据量了,主要还是在于环境的整合复杂度,因为涉及的有些系统是测试环境的整合,可能维护时间会宽裕一些,有些是重要的在线业务,可能需要前期准备要更多,保证停机维护时间短。
大体总结了一下,关于这种整合式的迁移,有一些信息需要考虑。
1.关于表空间的信息,这部分信息源端,目标端做比对,大小,可用空间等做一个比对。
2.用户的资源管理profile,对于原来用户设定的profile需要原封不对的复制过来,当然资源的整体使用情况是在合理范围之内。
3.crontab 原来的库中的crontab可以直接平移到目标库中
4.监听端口,原来库中的监听端口可能和目标端不同,这个时候可以根据情况做调整,是新建启用新的端口还是把端口整合在一个指定的范围之内。
5.防火墙,这部分信息需要保证访问的权限和源库要保持一致,当然在不考虑filter chain的情况下,还是简单的追加即可。
6.用户权限,关于系统权限,角色权限等,需要和源库保持基本一致。
7.关于db link这个部分比较纠结,可能需要手工逐个处理,确实这些细节没有搞头,但是又不得不做。
8.存储过程,pl/sql,视图 这部分信息还是需要和源库复制保持一致,当然还是会有一些细节差别。
9.序列 序列的处理其实还是一个比较特殊的部分,为了保证不会出现sequence的当前值比字段最大值小的情况,需要在迁移后同步sequence的值,对于此,一个比较省事的方式就是重建序列,当然需要注意的部分就是序列的权限设定,其它可以通过dbms_metadata或者解析dump文件得到对应的sequence 语句。
10.tns部分,如果是迁移,对于源库的配置可能就不需要了,但是对于db link相关的tns部分还是需要的。
所以这种整合式迁移的很多场景都是不断整合结构,这个骨架搭建好了,就好比上了高速公路。数据迁移才刚刚开始。
最近的迁移项目还是有些特殊,有schema级别的迁移,这种情况数据库版本的影响就没有那么大了,基本就是schema级别的平移,这种听起来还算容易,有些场景是同名schema,同名表的整合,这种情况就有些让人头疼,每个owner用户可能有若干个连接用户,还需要考虑每个连接用户的权限和对应关系。有些用户如果整合起来重合度够高,还需要调整用户名。
像比如下面的迁移场景,其实难度基本都不在数据量上,而在在整合的难度上,这个时候数据迁移基本上就成了整合。
如果把上面三个数据库整合起来,其实也有几种方式,在11g中直接就是schema复制,导出导入即可,对于冲突重复的schema可能需要逐个确认,要不就是省事一些,直接修改用户名加以区分。
还有一种方案是放在12c的pdb里面。其实这种方式看起来还是能够解决大部分的兼容问题,但是个人感觉这种方式有个缺点就是会把原来的问题包装起来,原来的不规范的数据设计我们只是把它整合在一个数据库里,哪些问题还是问题,不规范还是不规范,如果其中一个pdb出现了大的性能抖动,影响是全局的。还有就是R2版本还为发布,在生产上使用还是存在一点的顾虑,不过那种方式有个很明显的优点就是省事。对于测试环境的整合还是一种好的方式。
所以现在重点已经不在于数据量了,主要还是在于环境的整合复杂度,因为涉及的有些系统是测试环境的整合,可能维护时间会宽裕一些,有些是重要的在线业务,可能需要前期准备要更多,保证停机维护时间短。
大体总结了一下,关于这种整合式的迁移,有一些信息需要考虑。
1.关于表空间的信息,这部分信息源端,目标端做比对,大小,可用空间等做一个比对。
2.用户的资源管理profile,对于原来用户设定的profile需要原封不对的复制过来,当然资源的整体使用情况是在合理范围之内。
3.crontab 原来的库中的crontab可以直接平移到目标库中
4.监听端口,原来库中的监听端口可能和目标端不同,这个时候可以根据情况做调整,是新建启用新的端口还是把端口整合在一个指定的范围之内。
5.防火墙,这部分信息需要保证访问的权限和源库要保持一致,当然在不考虑filter chain的情况下,还是简单的追加即可。
6.用户权限,关于系统权限,角色权限等,需要和源库保持基本一致。
7.关于db link这个部分比较纠结,可能需要手工逐个处理,确实这些细节没有搞头,但是又不得不做。
8.存储过程,pl/sql,视图 这部分信息还是需要和源库复制保持一致,当然还是会有一些细节差别。
9.序列 序列的处理其实还是一个比较特殊的部分,为了保证不会出现sequence的当前值比字段最大值小的情况,需要在迁移后同步sequence的值,对于此,一个比较省事的方式就是重建序列,当然需要注意的部分就是序列的权限设定,其它可以通过dbms_metadata或者解析dump文件得到对应的sequence 语句。
10.tns部分,如果是迁移,对于源库的配置可能就不需要了,但是对于db link相关的tns部分还是需要的。
所以这种整合式迁移的很多场景都是不断整合结构,这个骨架搭建好了,就好比上了高速公路。数据迁移才刚刚开始。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

