通过demo学习OpenStack开发——数据库(2)
编者按:《通过demo学习OpenStack开发》专栏是刘陈泓的系列文章,专栏通过开发一个demo的形式来介绍一些参与OpenStack项目开发的必要的基础知识,希望帮助大家入门企业级Python项目的开发和OpenStack项目的开发。刘陈泓主要关注OpenStack的身份认证和计费领域。另外,还对云计算、分布式系统应用和开发感兴趣。
在上一篇文章,我们介绍了SQLAlchemy的基本概念,也介绍了基本的使用流程。本文我们结合webdemo这个项目来介绍如何在项目中使用SQLAlchemy。另外,我们还会介绍数据库版本管理的概念和实践,这也是OpenStack每个项目都需要做的事情。
Webdemo中的数据模型的定义和实现
我们之前在 webdemo 项目中已经开发了一个user管理的API,可以在这里回顾。当时只是接收了API请求并且打印信息,并没有实际的进行数据存储。现在我们就要引入数据库操作,来完成user管理的API。
User数据模型
在开发数据库应用前,需要先定义好数据模型。因为本文只是要演示SQL Alchemy的应用,所以我们定义个最简单的数据模型。user表的定义如下:
- id : 主键,一般由数据库的自增类型实现。
- user_id : user id,是一个UUID字符串,是OpenStack中最常用来标记资源的方式,全局唯一,并且为该字段建立索引。
- name : user的名称,允许修改,全局唯一,不能为空。
- email : user的email,允许修改,可以为空。
搭建数据库层的代码框架
OpenStack项目中我见过两种数据库的代码框架分隔,一种是Keystone的风格,它把一组API的API代码和数据库代码都放在同一个目录下,如下所示:

采用Pecan框架的项目则大多把数据库相关代码都放在db目录下,比如Magnum项目,如下所示:

由于webdemo采用的是Pecan框架,而且把数据库操作的代码放到同一个目录下也会比较清晰,所以我们采用和Magnum项目相同的方式来编写数据库相关的代码,创建 webdemo/db 目录,然后把数据库操作的相关代码都放在这个目录下,如下所示:

由于webdemo项目还没有使用 oslo_db 库,所以代码看起来比较直观,没有Magnum项目复杂。接下来,我们就要开始写数据库操作的相关代码,分为两个步骤:
1. 在**db/models.py**中定义`User`类,对应数据库的user表。 2. 在**db/api.py**中实现一个`Connection`类,这个类封装了所有的数据库操作接口。我们会在这个类中实现对user表的CRUD等操作。 定义User数据模型映射类
db/models.py中的代码如下:
from sqlalchemy import Column, Integer, String from sqlalchemy.ext import declarative from sqlalchemy import Index Base = declarative.declarative_base() class User(Base): """User table""" __tablename__ = 'user' __table_args__ = ( Index('ix_user_user_id', 'user_id'), ) id = Column(Integer, primary_key=True) user_id = Column(String(255), nullable=False) name = Column(String(64), nullable=False, unique=True) email = Column(String(255)) 我们按照我们之前定义的数据模型,实现了映射类。
实现DB API
DB通用函数
在 db/api.py 中,我们先定义了一些通用函数,代码如下:
from sqlalchemy import create_engine import sqlalchemy.orm from sqlalchemy.orm import exc from webdemo.db import models as db_models _ENGINE = None _SESSION_MAKER = None def get_engine(): global _ENGINE if _ENGINE is not None: return _ENGINE _ENGINE = create_engine('sqlite://') db_models.Base.metadata.create_all(_ENGINE) return _ENGINE def get_session_maker(engine): global _SESSION_MAKER if _SESSION_MAKER is not None: return _SESSION_MAKER _SESSION_MAKER = sqlalchemy.orm.sessionmaker(bind=engine) return _SESSION_MAKER def get_session(): engine = get_engine() maker = get_session_maker(engine) session = maker() return session 上面的代码中,我们定义了三个函数:
-
get_engine:返回全局唯一的engine,不需要重复分配。 -
get_session_maker:返回全局唯一的session maker,不需要重复分配。 -
get_session:每次返回一个新的session,因为一个session不能同时被两个数据库客户端使用。
这三个函数是使用SQL Alchemy中经常会封装的,所以OpenStack的 oslo_db 项目就封装了这些函数,供所有的OpenStack项目使用。
这里需要注意一个地方,在 get_engine() 中:
_ENGINE = create_engine('sqlite://') db_models.Base.metadata.create_all(_ENGINE) 我们使用了sqlite内存数据库,并且立刻创建了所有的表。这么做只是为了演示方便。在实际的项目中, create_engine() 的数据库URL参数应该是从配置文件中读取的,而且也不能在创建engine后就创建所有的表(这样数据库的数据都丢了)。要解决在数据库中建表的问题,就要先了解数据库版本管理的知识,也就是 database migration ,我们在下文中会说明。
Connection实现
Connection 的实现就简单得多了,直接看代码。这里只实现了 get_user() 和 list_users() 方法。
class Connection(object): def __init__(self): pass def get_user(self, user_id): query = get_session().query(db_models.User).filter_by(user_id=user_id) try: user = query.one() except exc.NoResultFound: # TODO(developer): process this situation pass return user def list_users(self): session = get_session() query = session.query(db_models.User) users = query.all() return users def update_user(self, user): pass def delete_user(self, user): pass
在API Controller中使用DB API
现在我们有了DB API,接下来就是要在Controller中使用它。对于使用Pecan框架的应用来说,我们定义一个Pecan hook,这个hook在每个请求进来的时候实例化一个db的 Connection 对象,然后在controller代码中我们可以直接使用这个 Connection 实例。关于Pecan hook的相关信息,请查看 Pecan官方文档 。
首先,我们要实现这个hook,并且加入到app中。hook的实现代码在 webdemo/api/hooks.py 中:
from pecan import hooks from webdemo.db import api as db_api class DBHook(hooks.PecanHook): """Create a db connection instance.""" def before(self, state): state.request.db_conn = db_api.Connection()
然后,修改 webdemo/api/app.py 中的 setup_app() 方法:
def setup_app(): config = get_pecan_config() app_hooks = [hooks.DBHook()] app_conf = dict(config.app) app = pecan.make_app( app_conf.pop('root'), logging=getattr(config, 'logging', {}), hooks=app_hooks, **app_conf ) return app 现在,我们就可以在controller使用DB API了。我们这里要重新实现API服务(4)实现的 GET /v1/users 这个接口:
... class User(wtypes.Base): id = int user_id = wtypes.text name = wtypes.text email = wtypes.text class Users(wtypes.Base): users = [User] ... class UsersController(rest.RestController): @pecan.expose() def _lookup(self, user_id, *remainder): return UserController(user_id), remainder @expose.expose(Users) def get(self): db_conn = request.db_conn # 获取DBHook中创建的Connection实例 users = db_conn.list_users() # 调用所需的DB API users_list = [] for user in users: u = User() u.id = user.id u.user_id = user.user_id u.name = user.name u.email = user.email users_list.append(u) return Users(users=users_list) @expose.expose(None, body=User, status_code=201) def post(self, user): print user
现在,我们就已经完整的实现了这个API,客户端访问API时是从数据库拿数据,而不是返回一个模拟的数据。读者可以使用API服务(4)中的方法运行测试服务器来测试这个API。注意:由于数据库操作依赖于SQL Alchemy库,所以需要把它添加到 requirement.txt 中: SQLAlchemy<1.1.0,>=0.9.9 。
小结
现在我们已经完成了数据库层的代码框架搭建,读者可以大概了解到一个OpenStack项目中是如何进行数据库操作的。上面的代码可以到 GitHub 下载。
数据库版本管理
数据库版本管理的概念
上面我们在 get_engine() 函数中使用了内存数据库,并且创建了所有的表。在实际项目中,这么做肯定是不行的:
1. 实际项目中不会使用内存数据库,这种数据库一般只是在单元测试中使用。 2. 如果每次`create_engine`都把数据库的表重新创建一次,那么数据库中的数据就丢失了,绝对不可容忍。 解决这个问题的办法也很简单: 不使用内存数据库,并且在运行项目代码前先把数据库中的表都建好 。这么做确实是解决了问题,但是看起来有点麻烦:
- 如果每次都手动写SQL语句来创建数据库中的表,会很容易出错,而且很麻烦。
- 如果项目修改了数据模型,那么不能简单的修改建表的SQL语句,因为重新建表会让数据丢失。我们只能增加新的SQL语句来修改现有的数据库。
- 最关键的是 :我们怎么知道一个正在生产运行的数据库是要执行那些SQL语句?如果数据库第一次使用,那么执行全部的语句是正确的;如果数据库已经在使用,里面有数据,那么我们只能执行那些修改表定义的SQL语句,而不能执行那些重新建表的SQL语句。
为了解决这种问题,就有人发明了数据库版本管理的概念,也称为 Database Migration 。基本原理是: 在我们要使用的数据库中建立一张表,里面保存了数据库的当前版本,然后我们在代码中为每个数据库版本写好所需的SQL语句。当对一个数据库执行migration操作时,会执行从当前版本到目标版本之间的所有SQL语句 。举个例子:
1. 在Version 1时,我们在数据库中建立一个user表。 2. 在Version 2时,我们在数据库中建立一个project表。 3. 在Version 3时,我们修改user表,增加一个age列。 那么在我们对一个数据库执行migration操作,数据库的当前版本 Version 1 ,我们设定的目标版本是 Version 3 ,那么操作就是:建立一个project表,修改user表,增加一个age列,并且把数据库当前版本设置为 Version 3 。
数据库的版本管理是所有大型数据库项目的需求,每种语言都有自己的解决方案。OpenStack中主要使用SQL Alchemy的两种解决方案: sqlalchemy-migrate 和 Alembic 。早期的OpenStack项目使用了sqlalchemy-migrate,后来换成了Alembic。做出这个切换的主要原因是Alembic对数据库版本的设计和管理更灵活,可以支持分支,而sqlalchemy-migrate只能支持直线的版本管理,具体可以看OpenStack的WiKi文档 Alembic 。
接下来,我们就在我们的webdemo项目中引入Alembic来进行版本管理。
Alembic
要使用Alembic,大概需要以下步骤:
1. 安装Alembic 2. 在项目中创建Alembic的migration环境 3. 修改Alembic配置文件 4. 创建migration脚本 5. 执行迁移动作 看起来步骤很复杂,其实搭建好环境后,新增数据库版本只需要执行最后两个步骤。
安装Alembic
在 webdemo/requirements.txt 中加入: alembic>=0.8.0 。然后在virtualenv中安装即可。
在项目中创建Alembic的migration环境
一般OpenStack项目中,Alembic的环境都是放在 db/sqlalchemy/ 目录下,因此,我们先建立目录 webdemo/db/sqlalchemy/ ,然后在这个目录下初始化Alembic环境:
(.venv)➜ ~/programming/python/webdemo git:(master) ✗ $ cd webdemo/db (.venv)➜ ~/programming/python/webdemo/webdemo/db git:(master) ✗ $ ls api.py api.pyc __init__.py __init__.pyc models.py models.pyc sqlalchemy (.venv)➜ ~/programming/python/webdemo/webdemo/db git:(master) ✗ $ cd sqlalchemy (.venv)➜ ~/programming/python/webdemo/webdemo/db/sqlalchemy git:(master) ✗ $ ls (.venv)➜ ~/programming/python/webdemo/webdemo/db/sqlalchemy git:(master) ✗ $ alembic init alembic Creating directory /home/diabloneo/programming/python/webdemo/webdemo/db/sqlalchemy/alembic ... done Creating directory /home/diabloneo/programming/python/webdemo/webdemo/db/sqlalchemy/alembic/versions ... done Generating /home/diabloneo/programming/python/webdemo/webdemo/db/sqlalchemy/alembic/script.py.mako ... done Generating /home/diabloneo/programming/python/webdemo/webdemo/db/sqlalchemy/alembic.ini ... done Generating /home/diabloneo/programming/python/webdemo/webdemo/db/sqlalchemy/alembic/README ... done Generating /home/diabloneo/programming/python/webdemo/webdemo/db/sqlalchemy/alembic/env.pyc ... done Generating /home/diabloneo/programming/python/webdemo/webdemo/db/sqlalchemy/alembic/env.py ... done Please edit configuration/connection/logging settings in '/home/diabloneo/programming/python/webdemo/webdemo/db/sqlalchemy/alembic.ini' before proceeding. (.venv)➜ ~/programming/python/webdemo/webdemo/db/sqlalchemy git:(master) ✗ $
现在,我们就在 webdemo/db/sqlalchemy/alembic/ 目录下建立了一个Alembic migration环境:
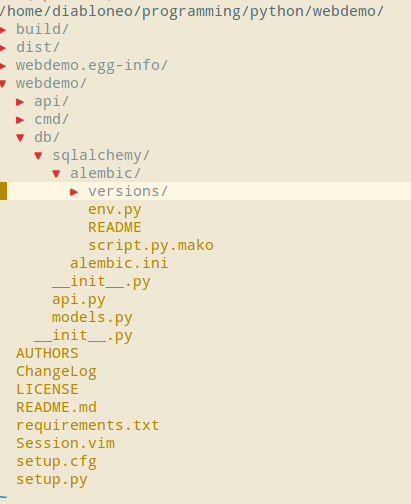
修改Alembic配置文件
webdemo/db/sqlalchemy/alembic.ini 文件是Alembic的配置文件,我们现在需要修改文件中的 sqlalchemy.url 这个配置项,用来指向我们的数据库。这里,我们使用SQLite数据库,数据库文件存放在webdemo项目的根目录下,名称是 webdemo.db :
# sqlalchemy.url = driver://user:pass@localhost/dbname sqlalchemy.url = sqlite:///../../../webdemo.db
注意:实际项目中,数据库的URL信息是从项目配置文件中读取,然后通过动态的方式传递给Alembic的。具体的做法,读者可以参考Magnum项目的 实现 。
创建migration脚本
现在,我们可以创建第一个迁移脚本了,我们的第一个数据库版本就是创建我们的user表:
(.venv)➜ ~/programming/python/webdemo/webdemo/db/sqlalchemy git:(master) ✗ $ alembic revision -m "Create user table" Generating /home/diabloneo/programming/python/webdemo/webdemo/db/sqlalchemy/alembic/versions/4bafdb464737_create_user_table.py ... done
现在脚本已经帮我们生成好了,不过这个只是一个空的脚本,我们需要自己实现里面的具体操作,补充完整后的脚本如下:
"""Create user table Revision ID: 4bafdb464737 Revises: Create Date: 2016-02-21 12:24:46.640894 """ # revision identifiers, used by Alembic. revision = '4bafdb464737' down_revision = None branch_labels = None depends_on = None from alembic import op import sqlalchemy as sa def upgrade(): op.create_table( 'user', sa.Column('id', sa.Integer, primary_key=True), sa.Column('user_id', sa.String(255), nullable=False), sa.Column('name', sa.String(64), nullable=False, unique=True), sa.Column('email', sa.String(255)) ) def downgrade(): op.drop_table('user') 其实就是把 User 类的定义再写了一遍,使用了Alembic提供的接口来方便的创建和删除表。
执行迁移操作
我们需要在 webdemo/db/sqlalchemy/ 目录下执行迁移操作,可能需要手动指定PYTHONPATH:
(.venv)➜ ~/programming/python/webdemo/webdemo/db/sqlalchemy git:(master) ✗ $ PYTHONPATH=../../../ alembic upgrade head INFO [alembic.migration] Context impl SQLiteImpl. INFO [alembic.migration] Will assume non-transactional DDL. INFO [alembic.migration] Running upgrade -> 4bafdb464737, Create user table
alembic upgrade head 会把数据库升级到最新的版本。这个时候,在webdemo的根目录下会出现 webdemo.db 这个文件,可以使用sqlite3命令查看内容:
(.venv)➜ ~/programming/python/webdemo git:(master) ✗ $ ls AUTHORS build ChangeLog dist LICENSE README.md requirements.txt Session.vim setup.cfg setup.py webdemo webdemo.db webdemo.egg-info (.venv)➜ ~/programming/python/webdemo git:(master) ✗ $ sqlite3 webdemo.db SQLite version 3.8.11.1 2015-07-29 20:00:57 Enter ".help" for usage hints. sqlite> .tables alembic_version user sqlite> .schema alembic_version CREATE TABLE alembic_version ( version_num VARCHAR(32) NOT NULL ); sqlite> .schema user CREATE TABLE user ( id INTEGER NOT NULL, user_id VARCHAR(255) NOT NULL, name VARCHAR(64) NOT NULL, email VARCHAR(255), PRIMARY KEY (id), UNIQUE (name) ); sqlite> .header on sqlite> select * from alembic_version; version_num 4bafdb464737
测试新的数据库
现在我们可以把之前使用的内存数据库换掉,使用我们的文件数据库,修改 get_engine() 函数:
def get_engine(): global _ENGINE if _ENGINE is not None: return _ENGINE _ENGINE = create_engine('sqlite:///webdemo.db') return _ENGINE 现在你可以手动往webdemo.db中添加数据,然后测试下API:
➜ ~/programming/python/webdemo git:(master) ✗ $ sqlite3 webdemo.db SQLite version 3.8.11.1 2015-07-29 20:00:57 Enter ".help" for usage hints. sqlite> .header on sqlite> select * from user; sqlite> .schema user CREATE TABLE user ( id INTEGER NOT NULL, user_id VARCHAR(255) NOT NULL, name VARCHAR(64) NOT NULL, email VARCHAR(255), PRIMARY KEY (id), UNIQUE (name) ); sqlite> insert into user values(1, "user_id", "Alice", "alice@example.com"); sqlite> select * from user; id|user_id|name|email 1|user_id|Alice|alice@example.com sqlite> .q ➜ ~/programming/python/webdemo git:(master) ✗ $ ➜ ~/programming/python/webdemo git:(master) ✗ $ curl http://localhost:8080/v1/users {"users": [{"email": "alice@example.com", "user_id": "user_id", "id": 1, "name": "Alice"}]}% 小结
现在,我们就已经完成了database migration代码框架的搭建,可以成功执行了第一个版本的数据库迁移。OpenStack项目中也是这么来做数据库迁移的。后续,一旦修改了项目,需要修改数据模型时,只要新增migration脚本即可。这部分代码也可以在 GitHub 中看到。
在实际生产环境中,当我们发布了一个项目的新版本后,在上线的时候,都会自动执行数据库迁移操作,升级数据库版本到最新的版本。如果线上的数据库版本已经是最新的,那么这个操作没有任何影响;如果不是最新的,那么会把数据库升级到最新的版本。
关于Alembic的更多使用方法,请阅读官方文档 Alembic 。
总结
本文到这边就结束了,这两篇文章我们了解OpenStack中数据库应用开发的基础知识。接下来,我们将会了解OpenStack中单元测试的相关知识。
感谢魏星对本文的审校。
给InfoQ中文站投稿或者参与内容翻译工作,请邮件至editors@cn.infoq.com。也欢迎大家通过新浪微博(@InfoQ,@丁晓昀),微信(微信号: InfoQChina )关注我们。
正文到此结束
- 本文标签: 云 认证 sql API 实例 微博 src 2015 测试 数据库 管理 Select 总结 dist 下载 翻译 NSA App 开发 build 文章 服务器 git IDE CTO 参数 example python root ip 数据 需求 REST schema 数据模型 web mail UI 代码 list Connection 删除 update db 配置 GitHub value 企业 http Logging 目录 tab 安装 OpenStack key Developer DDL SQLite
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

