Kubernetes集成外部服务实践
亚信公司有一些多年来在大数据方面的积累,比如数据,计算工具,算法等。现在要把这些能力结合起来做一个PaaS平台。经过一些前期选型与评估,我们决定用kubernetes+外部服务形式的架构来建立PaaS平台。
首先我们简单回顾一下kubernetes。
关于kubetnetes的架构大家应该都有所了解,主要的组件比如apiserver、etcd、controlle rmanager、scheduler以及cluster node上的kubelet跟proxy。但是我们今晚的主题,关注点主要在apiserver和controller。
Api server是kubernetes集群管理的入口,我们在做集群部署,诸如起pod,rolling update,建rc之类都是通过kubectl这个CLI工具。
kubectl接收命令行的输入,再发请求给apiserver,apiserver在接收到请求后会做一些验证,比如请求体是否合法、格式是否规范等。校验后,格式化的请求数据便会被写入到etcd。
Controller manager则一直在监控etcd的数据变化,kubenetes里的各种资源对应到自己相应的controller,比如pod会有pod的controller,service有service的controller,等等。当这些资源在etcd的存储数据发生变化时,controller manager则会监控到这些变化。
当我们在master node上观察kubenetes的网络连接时,我们会看到有在apiserver与etcd服务端口之间有许多tcp长连接。这些长连接就是在通过etcd的watch接口监控etcd中的数据变化。我们甚至可以用curl来直接调用这些接口,便会发现这是一个不会断开的长连接,当etcd里的数据发生变化时,这个长连接会不断地收到全量数据。
Scheduler的任务则是调度具体的节点来拉取镜像,起pod等调度工作。并且把结果写入到etcd。当我们使用 kubectl get xx命令时,便会从etcd中取出相应资源的存储值并格式化输出到终端。
Kubenetes整体上采用了优美的异步机制设计,从kubectl发起一个命令后,apiserver本身不会执行命令要求的动作,只是把请求数据写入到etcd中,然后由conrtoller manager从etcd观察到数据发生变化,再调用controller去执行具体的动作。如果是一个get操作,则是简单的从etcd返回相应资源数据。这里要注意的是,controller或者scheduler在完成任务,要写回数据至etcd时,也是通过api server来操作etcd。
关于kubernetes的内容我们简单回顾到这。下面我们来看看Backing Service,即后端服务。
Backing Service指需要通过网络调用来完成的服务。比方数据库啊,消息队列啊,以及api访问的服务比如Twitter api等等。目前大家开发应用都比较讲究应用与服务分离,开发者只需要关注应用业务本身的开发,对依赖的服务只需通过外部接入,直接使用。
外部服务有诸如持久化、插件化,服务化等特性。拿mysql来做比方,如果要把mysql跟应用打包在一起跑在集群容器里,需考虑把数据存储挂一个volume出来。而这一点在集群中会表现的更加复杂,因为涉及到跨主机数据同步的问题,开发者也许并不熟悉这些细节原理,如果总是纠结于应用之外的问题,那毫无疑问,开发效率会明显降低。目前主流的方式是把mysql的连接信息注入到应用的环境变量中,如果应用不再使用这个数据库,那么可以随时卸载这个数据库,或者接入另一个数据库,只要简单地清除或修改环境变量就可以,而不用再关心怎样优雅地去停掉那个不再被使用的数据库。
在PaaS上,应用开发者依赖的服务都会产生交集,这也是我们为什么以后端服务的形式来提供这些服务的原因之一,我们把这些后端服务作为一个支撑服务体系,给开发者提供服务。还以mysql来比方,如果没有后端服务,那每一个依赖mysql的应用都要起一个mysql的容器。对于集群管理者,意味着集群里会跑许多mysql容器。
另一个原因是,有很多后端服务比如大数据算法和分析工具,只以api或者独立服务的形式提供出来,如此一来,开发者也没有能力在自己的应用里打包一个这样的容器/镜像。
最后一个主要原因是,这些后端服务对开发者是热插拔的。使用的时候只要通过命令/接口来创建一个服务实例,然后绑定实例到自己的应用上就可以了,非常便捷。
那么再具体地,开发者如何使用这些后端服务,与自己的应用对接呢?我们采用了Service Broker协议规范。
Service Broker是CloudFoundry中的概念,目标就是把应用与服务分离。Service Broker实现7个REST API,通过API,我们可以知道一个Broker会提供何种服务,并且轻松地实现对服务实例的创建、绑定、解绑,以及销毁。采用ServiceBroker规范还有一个好处就是,所有实现了ServiceBroker协议的服务,都可以以后端服务的方式无缝接入我们的PaaS平台。这样,一些第三方服务就可以轻松地为开发者提供诸多服务。
我们来看一看Service Broker API。

(Service Broker API)
上面7个api便是server broker协议中需要实现的接口。获取服务,创建实例,绑定应用,这一系列操作都通过这几个api完成。关于service broker api的更多信息,我们从cloudfoundry网站可以看到更详细的介绍,想进一步了解的同学可以到这个链接查看: docs.cloudfoundry.org/services/api.html
下面分享如何扩展kubernetes。
Kubernetes的代码架构设计使得扩展其功能变得容易。正如前面所述,kubernetes里的概念诸如pod,service,在kubernetes里都被当作一种资源(Resource)来对待。所以我们的扩展首先是增加新的Resource类型。
针对Backing Service,我们增加了三个新的Resource,分别是:ServiceBroker,BackingService,BackingServiceInstance。相应地,我们增加了这三种Resource的controller,api,以及CLI。这样一来,我们就可以用命令行工具或者API,像操作其他资源一样去操作后端服务资源,来完成对应的功能。
下面我们以mongodb的Service Broker来举例说明,开发者如何在应用里同一个经由后端服务提供的mongodb实例交互。我们用oc命令来展示。oc是openshift客户端,也是由kubernetes扩展而来,完全兼容kubernetes。
首先是一个mongodb的Service Broker的yaml定义,内容如下:

(mongo.yaml)
我们用oc create -f mongo.yaml 把这个Broker接入到平台。
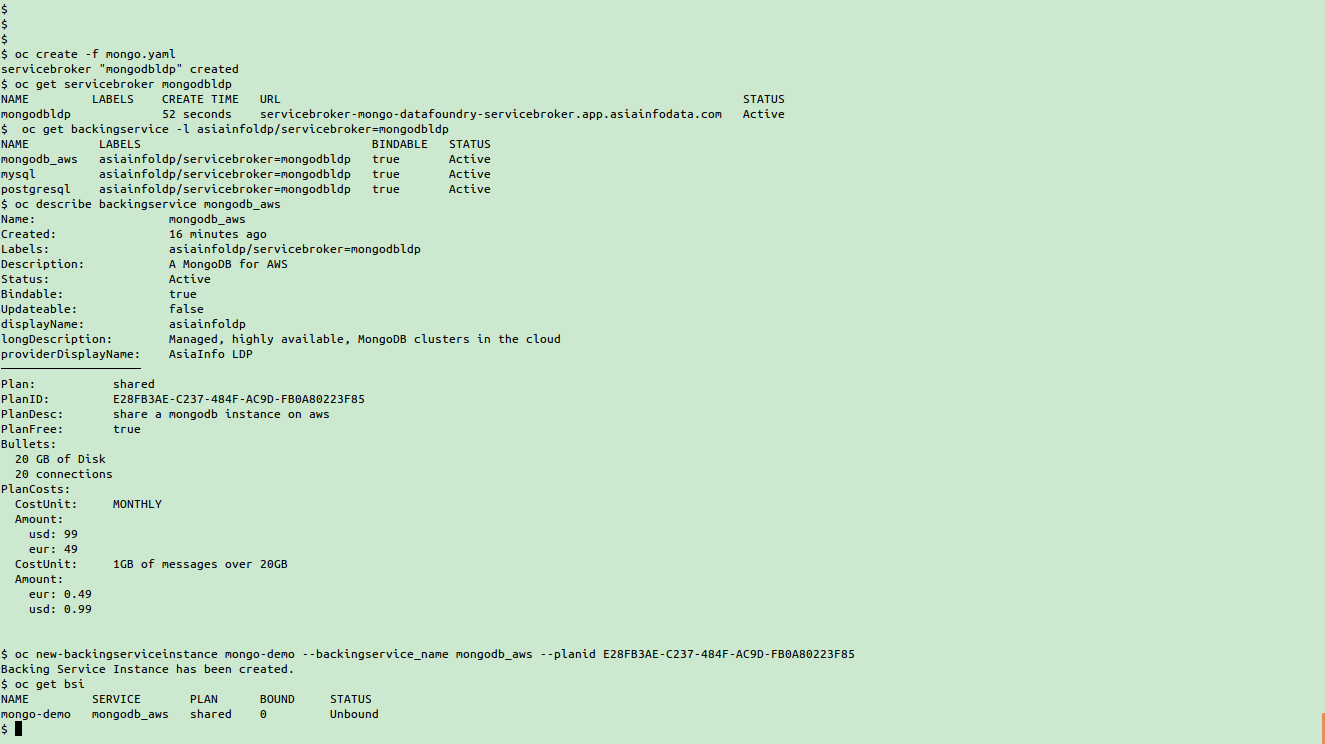
(接入mongoServicerBroker,并创建一个mongodb实例)
上面是几个命令执行的截图,分别解释一下。
用oc create命令创建一个broker后,我们用oc get servicebroker mongodbldp来查看刚刚创建的broker。
然后用oc get backingservice来查看刚刚接入的broker都提供什么服务。我们从图中看到,有mongodb_aws这个服务处于激活状态,也就是说,我们可以用它来创建mongodb实例。oc describe backingservice会列出mongodb这个后端服务更详细的信息,例如提供哪些套餐计划,套餐价格等等。其中,planid我们会在创建实例时用到。
oc new-backingserviceinstance mongo-demo --backingservice_name=mongodb_aws --planid xxxxxxxx 这个命令会创建一个mongodb实例。这个命令需要两个参数。一个是后端服务名,和planid。这两个参数将对应到所有后端服务中一个唯一的plan。
到这里,我们的实例就创建好了,通过oc get bsi可以看到刚刚创建的一个实例,处于未绑定状态。
下面把这个实例绑定到我们的应用中。我们继续看一张截图。

(绑定mongo实例)
首先我们有一个应用叫docker-2048,用oc describe dc docker-2048来观察,可以看到输出的ENV项,是我们注入到pod/container的环境变量。只有一个值TEST=test。
我们绑定刚刚创建的实例到这个应用。用命令oc bind mongo-demo docker-2048。bind命令也需要两个参数,就是服务实例和要绑定的应用。这里是dc的名字。dc是deploymentconfig,是openshift里的概念。在kubernetes中,则用rc。
绑定实例到应用后,我们用oc get bsi mongo-demo可以看到,这个实例上已经绑定了一个应用。我们再用oc describe bsi来观察,可以看到,连接mongodb数据库的必要信息已经以环境变量的方式注入到了应用docker-2048。在kubernetes中,当rc(openshift中是dc)发生改变时,会触发pod重启。
继续来看一张命令截图:

(解绑实例前后环境变量变化)
从这张截图看到,刚刚与mongo-demo绑定的docker-2048,现在已经有了几个新的变量,BSI_开头的,就是我们新注入的环境变量,此时pod已经被重启了。这时候,我们的应用docker-2048就可以通过这几个环境变量来访问mongodb。至此,外部服务和应用已经完成了对接。
当我们的应用不再使用mongodb这个实例,我们只需简单的命令oc unbind把实例与应用解绑即可,也很方便。上面的截图显示了当实例与应用解绑后,应用的环境变量再次发生了变化。之前注入的环境变量被清除了。只剩注入变量之前的那个环境变量TEST。
从上面几张截图,我们可以依次看到一个mongodb的后端服务实例被创建的过程,并且演示了实例如何被绑定到我们的应用docker-2048。我们观察到,在绑定了实例后,docker-2048的容器里多了一些mongodb的环境变量。这些环境变量随着解绑操作,被从应用容器里清除。上面的绑定与解绑过程,dc的改变会自动触发应用pod被重启。
Q&A:
Q: 请问在举的mysql服务的例子中,讲到不是采用应用与mysql一起打包成容器运行的方式,而是只需要把应用链接mysql服务的环境变量注册到pass平台上面就可以使用mysql的服务了是吗?那么你们平台上面不是运行多个mysql镜像吗?
A: 后端服务与PaaS在逻辑上是分开的,可能独立运行在平台集群外部,也可能运行在集群里,以service的形式服务。所以是否运行多个mysql容器,取决于servicebroker的设计实现。每一种servicebroker的设计都不必相同。
Q: 如果我把mysql环境变量注册到pass平台后,我应用链接你们平台上面的mysql服务后,如果后期分库分表可以吗?还需要重新配置环境变量信息吗?
A: 这个取决于后端服务提供的套餐。不同套餐计划提供不同程度的服务。
Q: 1.k8s自定义扩展具体怎么做的?2.后端服务你弹性伸缩直接用k8s自带的,还是有什么改造?
A: 1.扩展k8s是我们参考k8s的api server、controller这种异步机制直接在k8s中增加代码,k8s在易扩展性上做的挺好。后端服务可以运行在k8s集群上,或独立运行,其弹性伸缩由后端服务自身的设计来决定。
Q: 请问容器里的环境变量是Kubernetes的backingservice自动生成的,还是openshift特有的?是不是可以说因为backingservice会自动在容器里注册环境变量,所以某些场景下使用起来比起直接使用mongo地址来得方便?
A:是实例在绑定的时候由我们的扩展生成,并更新到pod里,不是openshift特有的。第二个问题的话,确实是这样,多数情况下,用环境变量都会很方便。
Q: k8s的volume,你们是如何使用的,当pod发生迁移后,如何保证volume还挂在pod上?
A: k8s本身提供了persistent volume功能,并且支持多种存储机制。pod迁移时,k8s会维护其对应的volume,根据不同的存储,k8s有不同的调度实现。
Q: 现在生产上用什么监控,监控有报警吗,什么粒度的?还有就是日志收集怎么处理有什么成熟的方案吗?
A: 我们采用了多种监控机制。主机、容器、和k8s服务本身,我们都采取不同的监控策略/工具。至于粒度,也跟监控的对象有关。日志我们用ELK。
Q: k8s的部署可否做到跨数据中心吗?如何实现?谢谢。
A: k8s是分布式的异步系统,理论上是可以跨数据中心的。但考虑到网络环境的复杂性,我们当前还没有作这方面的尝试。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

