LinkedIn分布式实时性能跟踪与效率优化实例
【编者按】LinkedIn领英作为全球性职业社交网站,为了能更好地服务用户,提供更加稳定可靠的系统访问服务,LinkedIn在监控方面下足了功夫,建立了自己的实时监测系统。近日,LinkedIn资深工程师Cuong Tran 发表了一篇博文 ,阐述了LinkedIn是如何结合工具inCapacity,通过使用调用图来进行有关性能和问题根源的案例分析。
Linkedln(领英 )的基础架构是面向服务的,即使是单个PV(页面浏览)请求也会涉及多个下游服务的调用。所以作为开发者来说,应当重视这些服务间的关系以及相互的性能影响。
为了实现对多层服务性能分析的需求,Linkedln建立了实时监测系统,具体请阅读 基于Apache Samza,揭秘LinkedIn架构背后的技术 。而本文的重点是围绕inCapacity工具以及从Samza获得的数据,透过使用实时调用关系图进行有关分析。
利用 inCapacity进行端对端性能和效率分析
以下是一个从移动端到网站前台服务的请求示例。

该请求会依次地向多个下游服务发出服务调用。根据前述 Apache Samza Blog 里所说,同一向内调用的服务跟踪会被分组然后重编为消息总线上用于实时分析的单一事件。同一个W eb页面的请求会被相同的pagekey标记,这样做的目的是使性能和效率分析着眼于Web应用上下文而不是个别的应用。比方说,移动应用和数据库服务的区别。
透过请求 ID,inCapacity会对同一向内调用进行跟踪,遍历调用路径,以不同的指标根据具体的应用上下文进行性能分析。这过程中能帮助开发者取得下述几个重要的性能数据:
- 服务或应用的使用频率;
- 哪些服务用时最多;
- APIs的调用频率,以及哪些APIs会对服务造成最大压力。
inCapacity反映的是架构中使用最频繁的情况;因为服务都是有规律地变更,该信息对于查找什么变更会影响或提升性能是很有帮助的。
请看以下一个简单的调用路径图:
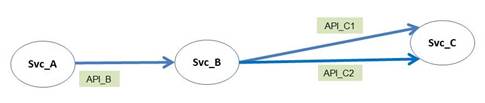
- 调用路径性能:对于每个调用图中的每条调用路径,inCapacity会进行跟踪计数和对每个API调用的返回时间进行记录。如果一个API会进行向下调用,inCapacity会提取出调用等待时间;其结果是API自身延时数据。例如在上图中,Svc_B中的API_B会依次调用API_C1和API_C2。API_B的自身延时不同于从API_B到API_C1和API_C2之间的延时总和。因此,在比较API自身延时和API总延时时,inCapacity能够判别出造成延时的主因来自于自身还是向下调用。沿着调用路径进行API调用和性能跟踪,能够让开发者了解到APIs对页面的依赖以及性能。
- 服务负载:对于调用路径中的每个服务,inCapacity会对每个页面的每个向内调用进行计数和延迟汇总。由于跟踪数据会被pagekeys进行标记,inCapacity能对请求发起者的负载进行分组,发起者会是页面或应用,而不仅仅是当前调用者。这样一来可以更好地基于页面上下文进行服务负载分析。
在 Linkedln中,每15分钟会进行页面调用路径聚合计算。因此API的计数和延时结果是每15分钟的总计数和平均延时。
除了进行性能和根源分析,调用图还可以进行 web页面效率分析。例如,对页面发出的向下调用进行开销汇总以计算出页面开销。页面的服务开销与服务的页面负载是成比例的,这类似于页面服务总延时的汇总计算。
最后对于能力计划方面,调用图也是能派上用场的。举例来说,如果想在下一季度把 PV提高20%,我们需要对硬件配置进行升级评估。又或者是针对新功能事前进行性能和关联服务性能分析。因此需要做好开销和效益间的平衡取舍。
使用 inCapacity进行性能分析
进行 web页面应用分析时,使用的是一种自上而下分析法,从高阶概要到具体调用路径,最后延伸到随机抽取调用树。
- 概要视图从总体上显示了应用对服务的依赖度以及服务的使用频率。inCapacity首先显示了使用得最多的服务。

- 调用路径视图中显示出从初始PV请求到每个下游服务的完整调用路径。开发者可以进行更细粒度的详细评估,例如应用中服务和APIs的依赖以及性能表现。这种广泛性视图能帮助找出被开发者忽略的向下调用问题,例如后端存储慢的问题。inCapacity会对同一调用级别的调用进行堆排序,以最慢->最快的顺序列示出调用路径。排序的依据是API总延时,是调用计数和平均延时的输出结果。
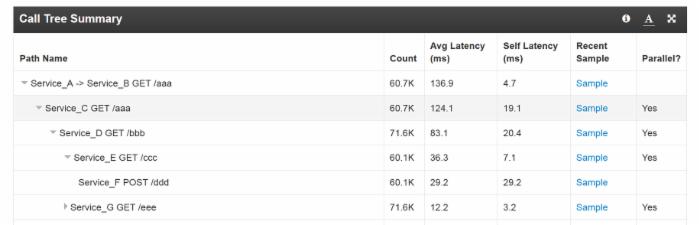
根据上图数据,造成 GET /aaa请求响应慢的原因在于对Service_C的调用,即GET /aaa的自身延时慢于等待时间。如果服务的自身延时比向下调用等待时间还长,那么该服务是响应最慢的服务。继续往下看,可见Service_F是响应最慢的服务。
当进行自身延时计算时, inCapacity会对并行的向下调用进行计算。而并行调用重叠的等待时间会被剔除。
- 单个调用图视图。该视图显示的是一个随机采样调用图。开发者可以依照时间线查看和检验跨数据中心的服务调用次序。在该瀑布试图下,开发者可以找出需要改进的地方以及分析出向下的调用频率和次数是否合理,2个向下调用之间的时延是否可接受的,又或者对这些调用采用并行方式会否会更加高效。

inCapacity允许开发者进行下列两种流量分析:
- 性能分析:识别出调用服务的页面,所使用的APIs,使用频率,以及相关的服务性能。分析对象可以是向内和向外调用。
- 依赖分析:找出受APIs调用与否影响最大的页面。
使用 inCapacity进行根源分析
要想对 Linkedln这样大型的网站进行性能问题的根源分析是有一定困难的;借助inCapacity的调用图性能比较特性则可事半功倍。
在对不同时间段的调用图进行性能对比时, inCapacity首先会根据总延时对调用路径进行堆排序。然后对不同调用级别的路径进行自身延时比较。如果发现自身延值较大,那么该API便是影响调用性能的问题所在。否则,分析程序会进入下级路径然后重新执行上述判断直到完结。
下图显示了如何使用调用图性能比较来进行 Service_B服务调用的问题根源分析。

这里根据时间线和当前时间进行了平均自身延时差值比较。第一级的延时是 24.4ms,自身延时仅为5.6ms,因此问题出在下一级。利用类似的思路,我们发现Service_D的自身延时达到11.4ms,所以该调用的性能问题出自Service_D。以此继续分析后得知问题根源是DB会话超限。因此,利用inCapacity进行根源探究是非常便捷的。
综述
实时分布式追踪与调用路径在评估 Web应用性能方面是不可缺少的。对性能和服务开销的分析不应孤立进行而是进行综合分析。本文结合工具inCapacity,通过使用调用图来进行了有关性能和问题根源的案例分析,希望对开发者有所启发。(编译:伍昆 责编:张红月)
英文来自: Linkedin Engineering
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

