技术剖析韩剧《幽灵》中使用的隐写术
0×00 前言
最近有一部剧人气非常高,据说是将军官和医生的浪漫故事。咦?!!这不是好几年前的老片子了么。

后来有人告诉我,是一部韩剧,里面的欧巴超帅妹子超靓。~/(≧▽≦)/~

说起韩剧,很多真是在用心做剧,抛开里面的细节,光凭人气来说, 不得不佩服其文化输出软实力。小伙伴们还记得2012年出品的黑客剧《幽灵》吗?该剧以网络犯罪和网络刑警为题材,讲述了虚拟搜查队在揭开一个个不为人知的隐藏在网络世界尖端技术中的秘密时,所经历的各种骇人听闻事件和奇遇。剧中出现了Encase、wireshark、od、process、nmap、DDOS、winhex、bt5等等多款大家熟悉的工具,不得不佩服其做剧的专业程度。

今天我们就来看看其第二集,男主角在所谓的“证据”面前,坚称自己是清白的,说“证据”视频其实是使用了隐写技术,里面隐藏着重要秘密,为了证明自己,便在警察面前当场进行了隐写信息的提取。
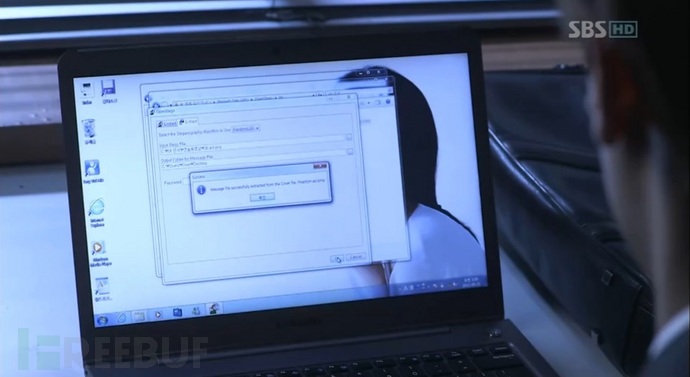
根据视频,我们可以判断出,男主角使用的是openstego隐写软件,但是视频中的情节确实有些瑕疵,有穿帮的成分。
这是男主角在挑选隐藏有信息的载体视频文件,大家可以看到里面全都是avi格式的视频。
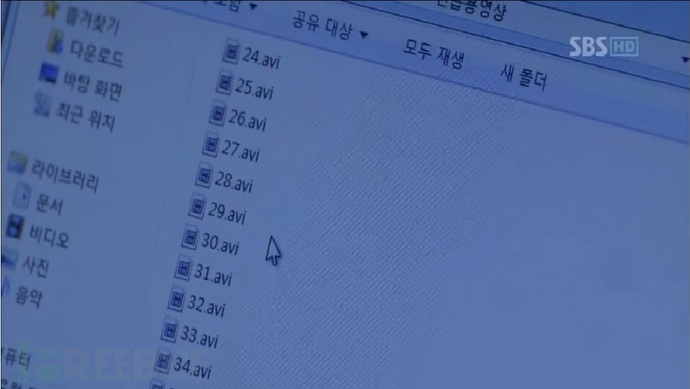
这是选中后的画面,明显可以看到载体文件实际上是png图像文件。
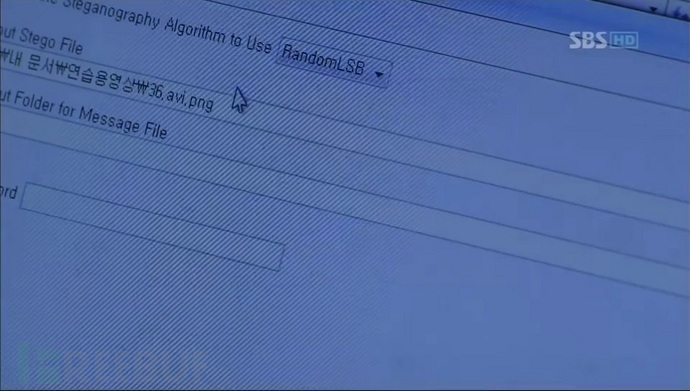
下面是提取出的秘密文件,该文件记录了被害人遇害的一些重要信息。

剧中讲述的是,男主角从一段视频中提取出了另外一段视频。而根据上面的细节判断,显然不是这样,而是从一个png文件中提取了视频文件。
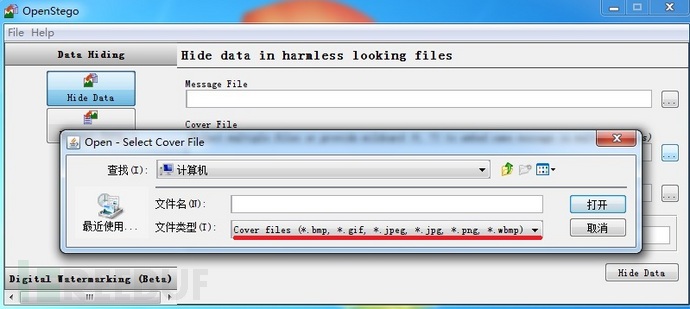
这是该软件在选取载体文件时的显示,可以看出只支持图像文件作为载体进行隐写,难怪剧组为了剧情的完整性,不惜使用改后缀名的方式来走捷径。其实剧组可以专门去找支持视频隐写的软件来进行这段剧情,估计是不太好找。o(︶︿︶)
既然都讲到这了,那我们不妨一起来看看剧中所使用的隐写术到底是神马鬼。
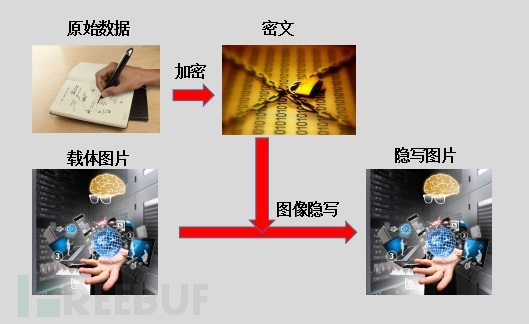
隐写术是信息隐藏( Information Hiding )的一个重要分支,而 信息隐藏 是为了 不让除预期接收者之外的任何人知晓信息的传递事件或者信息内容 , 可见信息隐藏与信息加密的不同处在于前者很好地隐蔽了传递事件。 隐写术英文名为 Steganography ,来源于特里特米乌斯的一本讲述 密码学 与隐写术的著作 Steganographia ,该书书名源于希腊 词汇 stegons 和 graphia ,意为 “ 隐秘书写 ” 。
0×01 数字图像隐写原理
图像隐写,顾名思义就是将目标信息隐藏在载体图片中,而这里的目标信息包含任何格式的数字文件(图像、文本、视频、声音等)。可能有同学会说,这个我也会, copy /b 分分钟搞定隐写。是这样吗?!!!我们先来看看 copy /b 是何方神术。
C opy /b 命令
命令格式: copy/b file1+file2+ …… +fileN 合并后的输出文件名
命令讲解:使用“ + ”将多个相同或不同格式的二进制文件合并为一个文件
例: copy/b 1.mpg+2.mpg 3.mpg ,即把视频 1.mpg 和 2.mpg 合并为 3.mpg
使用 copy/b image.jpg+text.txt new.jpg 命令将文本 text.txt 附加到图片 image.jpg 中
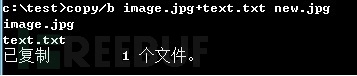
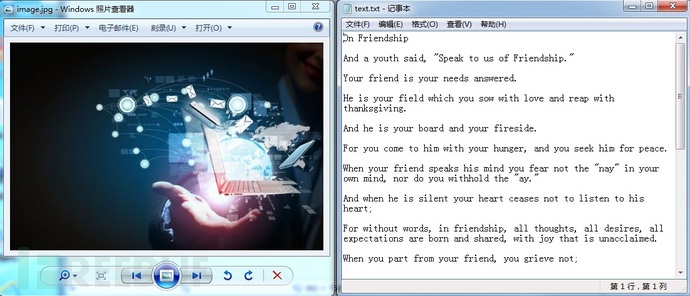
可以从源文件和生成文件的文件信息中观察到,源文件的文件大小相加正好等于生成文件的大小。
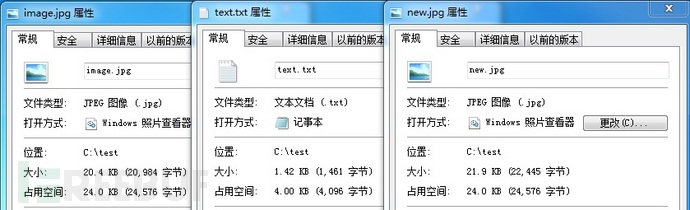
同时打开原图片和生成的新图片,视觉上并没有任何差别。
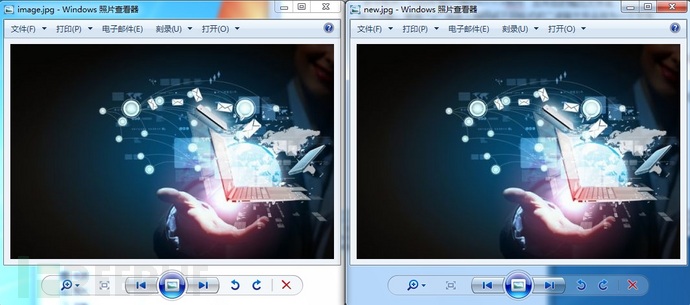
使用 UE 对比两图片的二进制差异,发现新生成的图片末尾追加了 text.txt 文本内容。
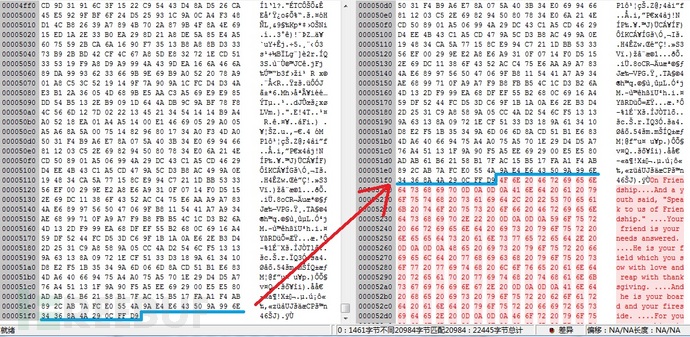
疑问:为什么新生成的图片末尾添加了新的数据,却用图片查看器查看时并没有看到图片新增了其他内容?
释疑: jpg 格式图片中,文件头中包含有图片 X 轴、 Y 轴的像素数目,所以图像查看器只根据像素信息进行图像的解析显示,而不会将末尾追加的二进制信息进行显示(即使将追加的信息也显示出来,也不会是文本内容,而是一堆杂乱的像素噪点)。
由此可见, copy /b 命令只是将几个文件进行了简单的追加合并,以达到隐蔽传送信息的目的,但是这种方法通过对比图像大小和文件大小,很容易检测到图像后面是否追加数据,所以 copy/b 只能算作一种简单的图像隐写技术。
而通常的图像隐写为了躲避检测,会利用载体的冗余度,在不破坏图像画质信息的基础上,嵌入被隐写信息,达到隐写目的。所以,如何利用图像文件的冗余来进行信息的隐藏,是隐写技术的关键所在。
0×02 bmp图像文件格式
常见的图像文件格式有 BMP 、 JPG 、 JPEG 、 PNG 、 GIF 。由于 BMP 采用位映射存储格式,除了图像深度可选以外,不采用其他任何压缩,占用的空间很大,所以存在着较多的冗余空间利用,并且在 bmp 格式图片中进行隐写较为容易。这里我们选用 BMP 格式的图片来做接下来的讲解。首先我们先了解 bmp 图像文件的格式。
BMP 图形文件,又叫 Bitmap (位图)或是 DIB(Device-Independent Device ,设备无关位图 ) ,是 Windows 采用的图形文件格式,在 Windows 环境下运行的所有图象处理软件都支持 BMP 图象文件格式,并且 Windows 系统内部各图像绘制操作都是以 BMP 为基础。
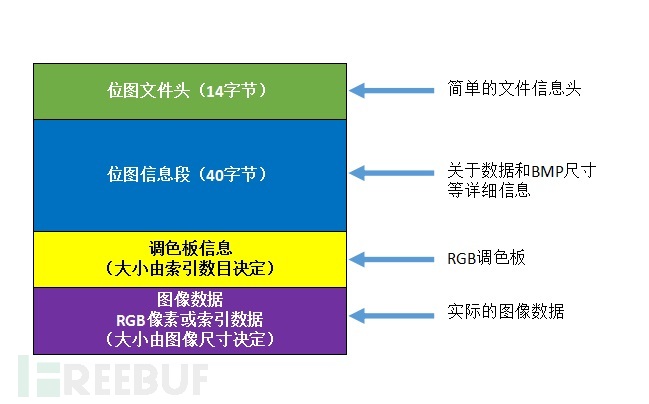
BMP 文件头: BITMAPFILEHEADER
typedef struct tagBITMAPFILEHEADER { // bmfh
WORD bfType; // 文件类型,该值必需是 0x4D42 ,也就是字符 'BM'
DWORD bfSize; // 说明该位图文件的大小,用字节为单位
WORD bfReserved1; // 保留,必须设置为 0
WORD bfReserved2; // 保留,必须设置为 0
DWORD bfOffBits; // 文件头开始到实际的图象数据之间的字节的偏移量
} BITMAPFILEH EADER;
注释:位图信息头和调色板的长度会根据不同情况而变化,所以可以根据 bfOffBits 这个偏移值迅速的从文件中读取到位数据。

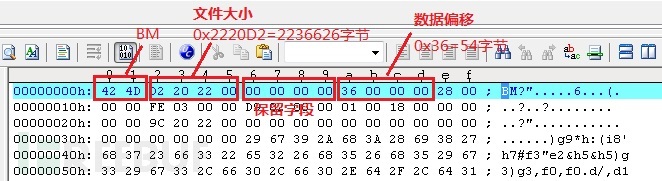
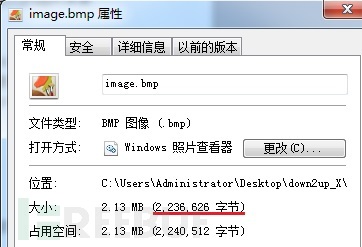
以上图作为测试图,查看其文件头的对应信息
位图信息段:BITMAPINFOHEADER
typedef struct tagBITMAPINFOHEADER{
DWORD biSize; //该结构所需要的字节数
LONG biWidth; //图象宽度,以像素为单位
LONG biHeight; //图象的高度,以像素为单位
WORD biPlanes; // 表示 bmp 图片的平面属,恒等于 1
WORD biBitCount // 说明比特数 / 象素,其值为 1 、 4 、 8 、 16 、 24 、或 32
DWORD biCompression; //图象数据压缩的类型
DWORD biSizeImage; //图象的大小,以字节为单位
LONG biXPelsPerMeter; // 水平分辨率,用象素 / 米表示
LONG biYPelsPerMeter; // 垂直分辨率,用象素 / 米表示
DWORD biClrUsed; // 位图实际使用的彩色表中的颜色索引数(设为 0 的话,则说明使用所有调色板项)
DWORD biClrImportant; // 对图象显示有重要影响的颜色索引的数目,如果是 0 ,表示都重要
} BITMAPINFOHEADER;
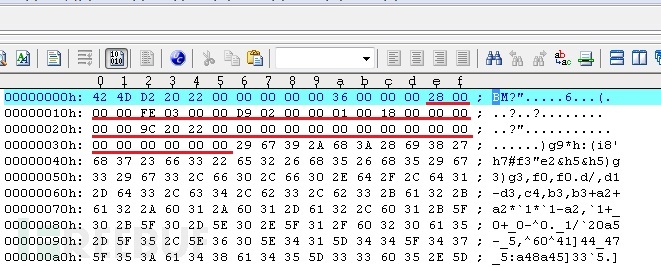
| 名称 | 值 | 注释 |
|---|---|---|
| biSize | 0×28=40字节 | |
| biWidth | 0x3FE=1022像素 | |
| biHeight | 0x2D9=729像素 | |
| biPlanes | 1 | 平面属性为1 |
| biBitCount | 0×18=24位 | 24位图,即1个像素由24位(3个字节)表示 |
| biCompression | 0 | 0表示未压缩 |
| biSizeImage | 0x22209C=2236572字节 | 文件大小减去头信息长度正好等于图像大小,所以该图没有调色板信息 |
| biXPelsPerMeter | 0 | |
| biYPelsPerMeter | 0 | |
| biClrUsed | 0 | 无索引信息 |
| biClrImportant | 0 | 无索引信息 |
调色板
根据图像尺寸和信息头大小,我们可以得知这幅图是不含调色板信息的。这是为什么呢?
首先需要了解一下图像文件中颜色的表示方法,我们知道自然界中的所有颜色都由红、绿、蓝( R , G , B )组合而成,下表位常见的 RGB 组合。
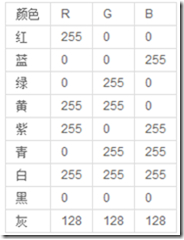
给一幅图中每个象素赋予不同的 RGB 值,就形成了彩色图。但是,如果有一个长宽各为 200 个象素,颜色数为 16 色的彩色图,每一个象素都用 R 、 G 、 B 三个分量表示。每个象素需要用 3 个字节,整个图象要用 200 × 200 × 3 ,约 120k 字节!这也太浪费了!
这幅图中最多只有 16 种颜色,而我们却为每一个像素付出了 3 个字节的空间。为了压缩,我们可以用一个表来记录这 16 种颜色,表中的每一行记录一种颜色的 R 、 G 、 B 值。这样表示一个象素的颜色时,只需要指出该颜色是在第几行,即该颜色在表中的索引值。例如,如果表的第 5 行为 255 , 0 , 0 (红色),那么当某个象素为红色时,只需要标明 5 即可。
这样可以节省多少空间呢? 16 种状态可以用 4 位( bit )表示,所以一个象素要用半个字节。整个图象要用 200 × 200 × 0.5 ,约 20k 字节,再加上表占用的字节为 3 × 16=48 字节,整个占用的字节数约为前面的 1/6 ,可见这个压缩效果非常明显。
调色板( Palette )的作用便是上面的颜色查找表。调色板在 windows 里的结构定义如下:
typedef struct tagPALETTEENTRY { // pe
BYTE peRed;
BYTE peGreen;
BYTE peBlue;
BYTE peFlags;
} PALETTEENTRY;
该结构除了 R 、 G 、 B 三个元素外,还有一个颜色深度信息。
既然调色板可以压缩存储空间,为什么这张 BMP 不带调色板呢?
这张 BMP 是 24 位真彩色的 BMP ,所谓真彩色图( true color ),就是它的颜色数高达 256 × 256 × 256 种,也就是说包含我们上述提到的 R 、 G 、 B 颜色表示方法中所有的颜色。真彩色图并不是说一幅图包含了所有的颜色,而是说它具有显示所有颜色的能力,即最多可以包含所有的颜色。如果用调色板,则调色板的长度高达 24 位,即索引需要 24 位来表示,则一个象素也要用 24 位,和直接用 R , G , B 三个分量表示用的字节数一样。这样即没有起到压缩的作用,反而因为有一个庞大的调色板的存在而体积增大。所以真彩色图直接用 R 、 G 、 B 三个分量表示,又叫做 24 位色图。
数据区域
B mp文件最后的区域则是数据区域,存储着图像像素信息,从前面信息段里得知该图为24位图,所以每一个像素都以3字节的RGB形式进行存储。

现在我们大体了解了 BMP 图片的基本结构,那么要把隐写的数据藏在哪里呢?显然,藏在文件头或者信息头里是不现实的,因为这些区域中的每一个字段都对应着明确的值,改变这些值会彻底破坏原有的结构而导致图片损坏,虽然文件头中有保留字段,但是这些字段容量有限不适合用于隐写。看来只剩下图像数据段适合用于隐写了,如何利用像素的 RGB 来进行隐写呢?
0×03 像素视觉差异
bmp图像中一个像素点使用 3 个字节(即 RGB 结构)来记录色彩,而隐写是把信息拆解后分别藏入像素点中,并且不会产生视觉上的变化。首先来看一下像素色彩在发生不同变化时的色彩差异。
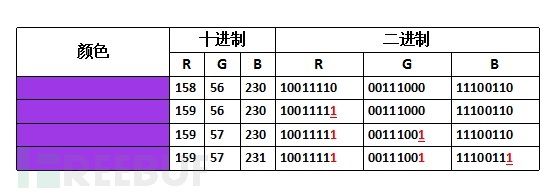
可见 RGB 最低位的变化不会产生视觉上的差异。
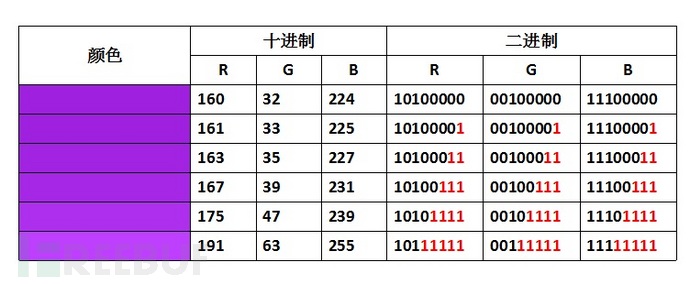
上图可以看出随着改变位数的增加,像素点的颜色开始发生变化,当低5位均变化后,与原像素点相比发生了较为明显的颜色改变。我们可以利用图像的这一特性,将信息分拆为若干比特位,将其逐一放入图像的像素点的低位,这便是著名的LSB(Least Significant Bit)隐写。
0×04 LSB隐写实战
我们采用 LSB 方式进行隐写,下图为需要隐写的文本信息。
将文件按比特分拆后,逐一写入载体图片的像素信息中。问题来了,解密的时候怎么知道需要解密的信息有多长?!!所以在隐写数据前需要把隐写的信息长度写入。
关键代码
count = struct.unpack('<L', all_the_bmp[10:14])[0]# 获取 bmp 像素数据偏移值
bmplength=len(all_the_bmp) - count;# 获取 bmp 像素数据大小
txtlength=len(all_the_text)#获取文本数据大小
bit=1;# 按照 bit 个比特位进行数据拆分
if(bmplength< txtlength*int(8/bit) ):# 判断 bmp 空间是否足够隐写
print("too small")
sys.exit()
result=[]
pos=0
for i in range(4):#将文本数据大小进行隐写
bchar = (txtlength>>(i*8)) & 0xff
for j in range(int(8/bit)):
temp = (bchar>>j*bit) & (pow(2,bit)-1)
result.append(((all_the_bmp[count+pos]>>bit)<<bit) | temp)
pos=pos+1
for bchar in all_the_text:#将文本数据进行隐写
for i in range(int(8/bit)):
temp = (bchar>>i*bit) & (pow(2,bit)-1)
result.append(((all_the_bmp[count+pos]>>bit)<<bit) | temp)
pos=pos+1
图片一个字节隐写 1 比特数据,效果如下图所示。

两张图的具体对比信息。
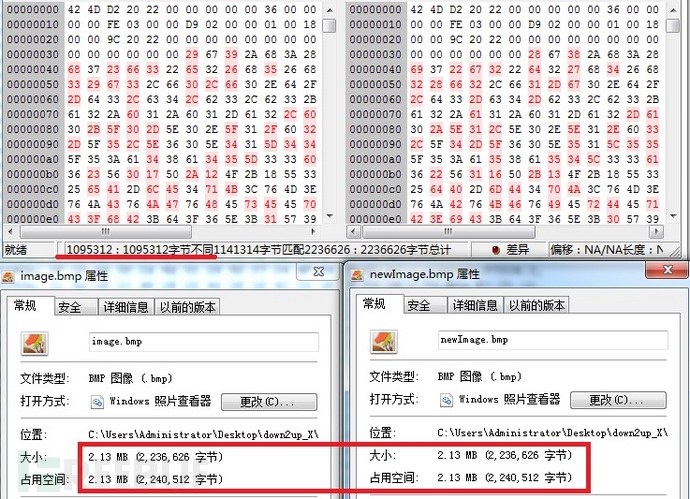
可以从两图的字节差异数中看到,并不等于隐写信息字节数 *8 。这是因为原数据的最低位恰好与隐写的比特值相等,从而使原数据并未发生变化。
现在我们将代码中控制拆分尺寸 bit=1 修改为 bit=2 ,即图像数据字节的低 2 比特位用于隐写,效果如下。
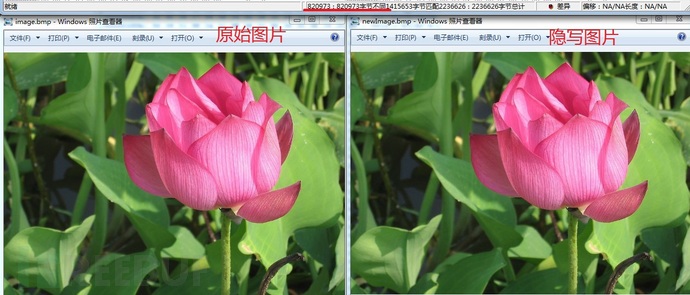
可见低 2 比特的改变并不会引起视觉上的差异,但却使得隐写空间增加了 2 倍。 设置 bit=4 ,即使用低 4 比特位用于隐写,效果如下。

可见隐写后的图片像素已经发生了明显变化。
再疯狂一点,我们将 bit 设置为 8 ,即把像素字节全部用于隐写,其实这已经相当于覆盖数据,结果则如下图惨不忍睹。

图中对应位置的原始像素值完全被破坏,完全成了文本文件的数据。由此可见,使用 LSB 技术隐写时,最佳选择最低位的 1-2bit 进行隐写。
下面是还原隐写信息的关键代码
bit=1#比特拆分尺寸
for i in range(4): #读取信息长度
bchar = 0
for j in range(int(8/bit)):
bchar=((all_the_image[count+pos]&(pow(2,bit)-1))<<j*bit) | bchar
pos=pos+1
lencontext = lencontext | (bchar << i*8)
result=[]
for i in range(lencontext):#读取隐写数据
bchar = 0
for j in range(int(8/bit)):
bchar=((all_the_image[count+pos]&(pow(2,bit)-1))<<j*bit) | bchar
pos=pos+1
result.append(bchar)
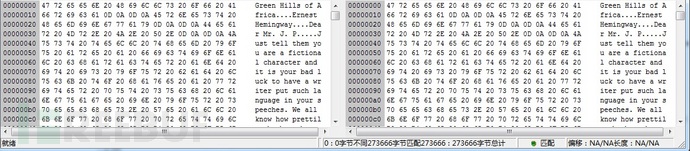
还原后的文本信息对比。
0×05 隐写升级
由于上面采用顺序隐写的方法,所以导致信息集中在图片的某一部分(下图中的差异对比图下方出现较宽区域的噪点)。

为了消除信息过于集中而导致图片某一区域像素信噪比过高,可以采用随机分配隐写位置的方式,将信息分散隐写在图片当中。这里需要注意的是,为了提取隐写信息的方便,我们并不会真正采用随机的方式进行隐写,否则需要将随机序列也一同记录在图片中。为了方便起见,我们采用将密码作为随机数生成器的种子,来生成一组伪随机数。
随机序列生成函数
def buildRandlist(key,length,size):#key 种子, length 图片长度, size 隐写信息的 bit 数
if size > length:
print("too small")
sys.exit()
random.seed(key)
rlist=[]
pos=0
num=0
while num < size:
maxvalue = int((length-pos)/(size - num))
minvalue = int(maxvalue/2)
if(maxvalue > 30):
minvalue=maxvalue-10
interval = random.randint(minvalue,maxvalue)
rlist.append(interval)
pos = pos + interval
num = num + 1
if pos > length:
print("too small")
sys.exit()
return rlist
可以看出生成随机数列有三个输入参数,其中图片长度可以根据图片文件的信息头进行获取,而其他两个参数可以作为密钥由用户保存,在信息提取时,必须在知道 key 和 size 的情况下才可以正确地提取完整信息。
下图为采用随机 LSB 隐写后的差异结果。

0×06 隐写与加密
隐写技术的基本原理和步骤了解后,我们会发现,如果对像素数据进行逐比特位提取,则很容易还原出原始数据,所以在实际应用中,隐写技术都配合加密技术一同使用,在隐写前,信息先进行加密处理,然后将加密后的密文进行隐写。这样便很好地保护了信息的安全性,即使信息被提取,也只是密文被暴露。
0×07 一些思考
图像的像素点在改变较低位比特数值时,并不会引起视觉的变化,那么视频、音频等一样可以作为隐写载体进行信息的隐写。可见能作为载体的素材很多,在互联网上也是海量的,如果一些有害信息通过这种技术来传播,则危害极大。
如何对含有隐写信息的载体进行快速检测便显得非常重要,图像各区域之间的像素值是有关联性的,而隐写的数据则打破了像素之间的关联性和图像的平滑性,而一些针对隐写技术的检测技术正是根据这一特性来进行的,感兴趣的同学可以查阅相关领域的研究资料,网上有很多相关素材。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

