零星数据结构与算法
今天在一个技术群里面,有同学提到了HyperLogLog(数据结构),排序方面技术。所以今天看一下相关的资料,算作一个总结。
HyperLogLog(数据结构)
HyperLogLog 可以接受多个元素作为输入,并给出输入元素的基数估算值:
• 基数:集合中不同元素的数量。比如 {'apple', 'banana', 'cherry', 'banana', 'apple'} 的基数就是 3 。
• 估算值:算法给出的基数并不是精确的,可能会比实际稍微多一些或者稍微少一些,但会控制在合
理的范围之内。
HyperLogLog 的优点是,即使输入元素的数量或者体积非常非常大,计算基数所需的空间总是固定的、并且是很小的。
一个特定使用场景就是统计某个网站的独立IP访问数量。常规基于cardinality(基数)统计已经不能满足空间的存储要求。有人列出过一个表格,是拿HyperLogLog与常规统计所占用的空间对比:
HyperLogLog 实现独立 IP 计算功能
独立 IP 数量 一天 一个月 一年一年(使用集合)
一百万 12 KB 360 KB 4.32 MB 5.4 GB
一千万 12 KB 360 KB 4.32 MB 54 GB
一亿 12 KB 360 KB 4.32 MB 540 GB
结论:
使用 HyperLogLog 记录不同数量的独立 IP 时,需要耗费的内存数量:
可以看到,要统计相同数量的独立 IP ,HyperLogLog 所需的内存要比集合少得多。
为 了更好地解决像独立 IP 地址计算这种问题,Redis 在 2.8.9 版本添加了 HyperLogLog 结构。这样,我们直接在NOSQL层面调用相应的方法传入IP,然后就能很快的统计出一个相对的统计结果。在 Redis 里面,每个HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以HyperLogLog 不能像集合那样,返回输入的各个元素。redis的PFADD 和 PFCOUNT 的使用示例
redis> PFADD unique::ip::counter '192.168.0.166'
(integer) 1
redis> PFADD unique::ip::counter '127.0.0.1'
(integer) 1
redis> PFADD unique::ip::counter '255.255.255.255'
(integer) 1
redis> PFCOUNT unique::ip::counter
(integer) 3
排序
无意间查看Arrays这个类,发现它的sort方法有点意思。
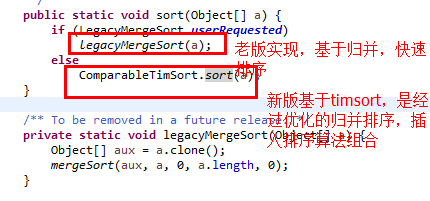
看得出来,JDK已经准备主推TimSort算法了。目前只是把老版的实现看懂了。
Timsort 是结合了合并排序(merge sort)和插入排序(insertion sort)而得出的排序算法,它在现实中有很好的效率。Tim Peters在2002年设计了该算法并在Python中使用(TimSort 是 Python 中 list.sort 的默认实现)。该算法找到数据中已经排好序的块-分区,每一个分区叫一个run,然后按规则合并这些run。Pyhton自从2.3版以来一直采用 Timsort算法排序,现在Java SE7和Android也采用Timsort算法对数组排序。
原理解释:
TimSort 算法为了减少对升序部分的回溯和对降序部分的性能倒退,将输入按其升序和降序特点进行了分区。排序的输入的单位不是一个个单独的数字,而是一个个的块-分 区。其中每一个分区叫一个run。针对这些 run 序列,每次拿一个 run 出来按规则进行合并。每次合并会将两个 run合并成一个 run。合并的结果保存到栈中。合并直到消耗掉所有的 run,这时将栈上剩余的 run合并到只剩一个 run 为止。这时这个仅剩的 run 便是排好序的结果。
综上述过程,Timsort算法的过程包括
(0)如何数组长度小于某个值,直接用二分插入排序算法
(1)找到各个run,并入栈
(2)按规则合并run
TimSort , wiki地址
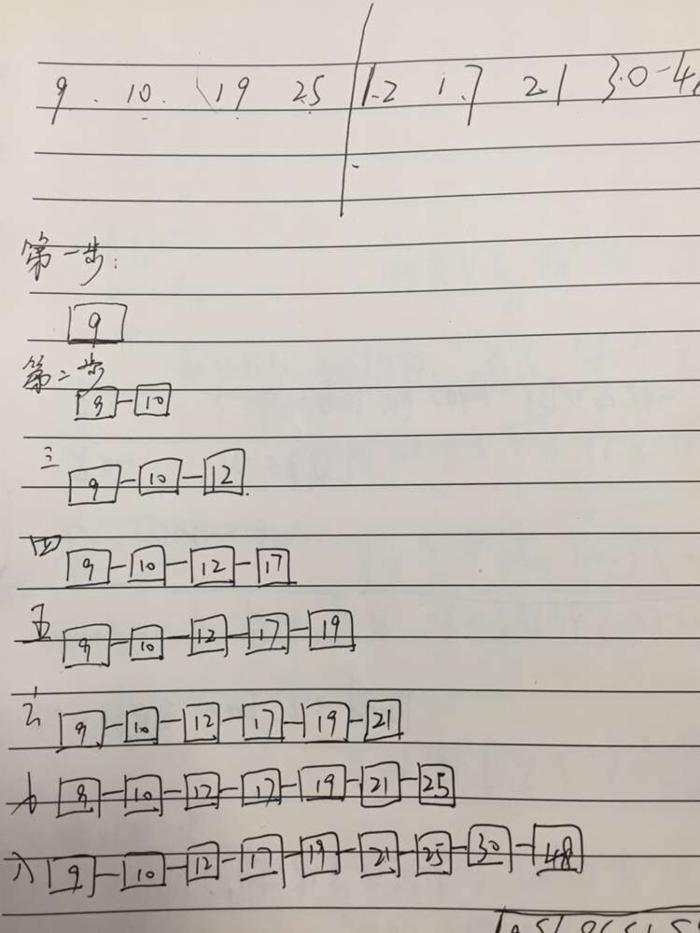
大概意思,就是对任意一段串进行拆分,每一个串一定是经过排好序的小集合。然后再拿出一个小集合与另外一个集合进行比较,组成一个更大的有序集合,直到最后所有的小集合变成一个集合为止。简要如图:

排序演示
原理基本就是这样,再慢慢消化一下,看看源码。
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

