浅析基于态势感知的网络安全事件预测方法
机器学习应用在安全领域,尤其是各种攻击检测(对外的入侵检测与对内的内部威胁检测)中,相信很多人早已习以为常。当前机器学习应用的焦点在于能够及时检测出系统/组织中发生的攻击威胁,从而缩短攻击发生到应急响应的时间差。
但是即便是最理想的威胁检测系统,当发现威胁报警时,威胁大多已经发生,对系统/组织的危害已经造成,因此 检测 永远只能作为一种相对被动的安全机制。因此,学界和业界开始将目光投向攻击威胁的事先防御,即 预测 机制的研究。
今天我们给大家介绍一个基于安全态势感知技术实现的网络安全事件预测方法,相信可以给感兴趣的广大攻城狮、程序猿们带来启发。
0×00 Outline
- 介绍(Introduction)
- 数据收集(Data Collection)
- 数据预处理(Data Pre-processing)
- 特征集(Feature Set)
- 训练与测试(Training and Test Procedure)
- 事件预测(Incident Prediction)
- 小结(Summary)
- 参考文献(Reference)
0×01 介绍
最近几年报道的网络安全事件对于社会和经济的影响越来越大,比如轰动全球的JPMorgan Chase Hack事件,就设计到76,000,000个普通家庭,而其在搜索引擎中可以找到近120,000条相关条目,如图1:

类似的安全事件还有很多,其共同点都是造成的社会经济影响已经远不是之前局限在系统/组织内部的微观Hack攻击。现有的安全研究集中在使用基于机器学习的多种主动主动防御机制来保护系统/组织免收这类威胁。然而由于现有主动防御机制的本质依旧是 检测 存在的攻击威胁,因此即便报警采取应急措施,实际的损失也已经不可避免。研究事先防御的 预测 方法势在必行。
我们今天所介绍的“预测”方法,单纯依靠外部公开可得的系统/组织信息,对系统可能发生的网络安全事件进行预判,从而作为原有检测机制的有益补充,提高系统防范网络威胁攻击的能力。
在继续我们今天的讨论之前,先来简单介绍下 安全态势 的背景。
安全态势简要介绍
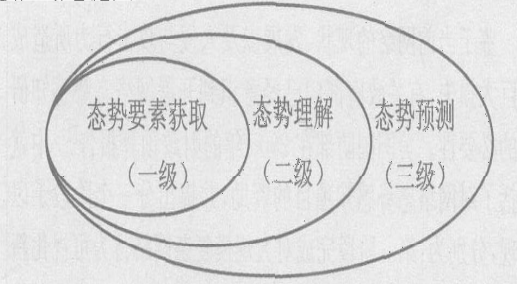
安全态势的概念来自于 态势感知 ,最早源于航天飞行的人因研究,之后在军事、核反应控制、空中交通监管等多个领域被广泛研究,原因在于在动态复杂的环境中,决策者需要借助态势感知的工具显示当前环境的连续变化情况,才能准确地做出决策。 网络态势 指的是由各种网络设备运行状况、网络行为以及用户行为等因素所构成的整个网络当前状态和变化趋势。 网络态势感知 则是在大规模网络环境中,对能够引起网络态势发生变化的安全要素进行获取、理解、显示以及预测未来的趋势。
一般的网络安全态势分为三个层次,如图2:
0×02 数据收集
作为一种实际可行的态势评估、预测方法,我们今天的方法所使用的所有数据均来自公开可得的数据源,这些数据源主要分为:
1. 安全态势数据(Security Posture Data)
网络安全态势可以使用许多测量方法,这里采用两种,一种是测量网络的误配置或与标准/建议配置的差异;另一种则是测量来自于该网络的恶意行为程度。具体地:
1.1 管理失当的数据表现(Mismanagement Symptoms)
此类数据主要表现为以下五类数据,分别来自于文献[1]中的数据特征的一个子集:
>Open Recurisive Resolvers:错误配置的DNS服务器很容易被用于*DNS放大*攻击;这部分数据来源于一个开源项目Open Resovler Project [2],该项目自动搜索、记录配置不当的DNS服务器信息; >DNS Source Port Randomization:RFC-5452建议出于安全考虑,DNS源端口和查询ID都应当随机化,然而实际中很多DNS没有遵循这一建议,这非常容易遭受*缓存中毒*攻击,这部分数据同样来自于文献[1]; >BGP Misconfiguration:BGP配置错误或重新配置都会造成不必要的路由协议更新和出现生存期很短的临时路由表项,这部分数据也来自文献[1]; >Untrusted HTTPS Certificates:X509证书用于实现TLS协议中d客户端认证,但是很多没有正确配置。通过网络扫描获得了2013年3月22日的10,300,000台主机配置错误[1]; >Open SMTP Mail Relays:这常被用来发送垃圾邮件,论文中使用的是2013年7月23日收集到的22,284个开放邮件中继服务器信息[1]; 1.2 恶意行为数据(Malicious Activity Data)
恶意行为数据主要指的是在外部检测观察到的,源自于某组织内部的恶意行为,这里我们只关注三种恶意行为,分别是 Spam、Phishing以及Scan 行为。
这部分数据主要来自以下数据库:
>SPAM:CBL、SBL、SpamCop、WPBL和UCEPROTECT; >Phishing:SURBL、PhishTank和hpHosts; >Scanning:Darknet scanners list、Dshield和OpenBL; 2. 安全事件数据
安全事件数据主要来自于三大公开的网络安全数据库,分别是:
>VERIS Commnunity Database(VCDB)[3]; >Hackmageddon[4]; >The Web Hacing Incidents Database(WHID)[5]; 下面用图3来简单展示下VCDB数据库中的安全事件示例:
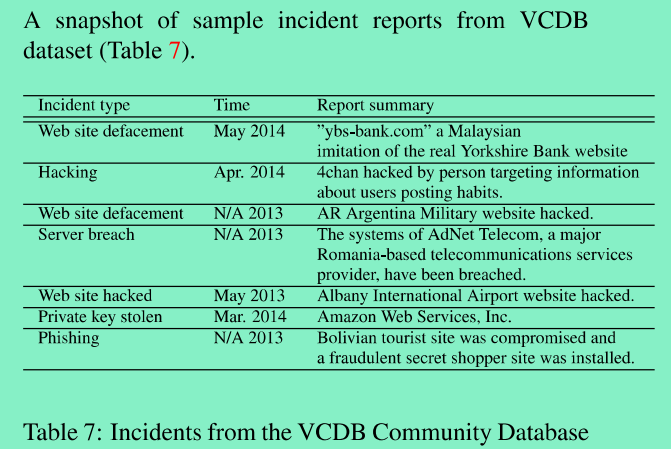
为了实验基于安全态势感知的网络安全事件预测方法,在收集安全事件数据时,事件发生事件应晚于收集的网络安全态势数据,如图4,其中的态势数据(前两类)用于训练,而最后的事件数据则用于预测测试。
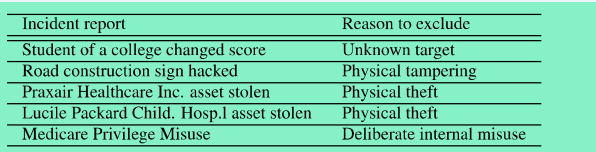
在事件集中,选择了700个安全事件,排除掉物理攻击、偷窃、内部攻击行为以及目标不明的事件报告,如图5:
0×03 数据预处理
在收集到安全态势数据之后,实际使用前一般都需要进行预处理。这里主要的预处理工作是将安全态势数据与安全事件数据结合,即映射(Mapping Process)与聚合(Aggregation Process)。
我们所收集到的安全态势数据与安全事件数据结合最大的问题在于:安全态势数据是基于主机IP层次的,而安全事件数据则是基于组织/企业层次的,那么如何利用基于IP的安全态势数据来预测基于组织/企业的安全事件呢?
一种可行的方法是:通过确定一个 Sample IP 作为代表IP来确定本次攻击目标的实际所有者(组织/企业),再通过查询公开的RIR数据库获得与攻击目标相关的所有IP地址块,然后这些IP地址块作为一个聚合单元与安全态势数据进行结合。
RIR(Reginal Internet Registry)负责将IP地址块分配给ISP的多家国际组织之一,全球五大RIR分别是RIPE(欧洲)、LACNIC、ARIN(美国)、AFRINIC以及APNIC(亚太地区)。 Sample IP 的思想是用一个代表IP反向查找RIR获取相关的所有IP块,从而得到一个组织/企业对应的IP集合信息。即:
Attack Target's Sample IP --->RIR--->Owner ID--->IP Block with the Owner--->Corporate IP Set 3.1 Sample IP提取算法
为了说明如何获得一次攻击事件中的目标 Sample IP ,我们简单地描述算法:
- 获取一个安全事件报告;
- 从安全报告中提取出与事件相关的公司的网站;
- 如果该网站是此次安全事件的起始点/入侵点,则将该网站的IP地址作为 Sample IP ,如文献[6]中对曼德菲尔城的官网攻击,官网就是入侵点;
- 如果该网站不是入侵点,但是却可以代表攻击目标,即该网站的所有者ID正是攻击事件的受害方,则也可以将该网站的IP作为本次事件的 Sample IP ;
- 其它情况的 Sample IP 暂不考虑;
- Sample IP 必须根绝安全事件报告人工分析确定;
3.2 聚合分析
在获得了攻击目标的 Sample IP 后,接下来就要查询RIR得到相关的IP块了,具体地:
- 通过 Sample IP 查询RIR数据库,得知其所有者ID,然后将RIR数据库中属于该ID的所有IP地址作为一个聚合单元;
- 全局聚合:将没有遭受攻击的组织也处理成聚合单元的模式,所得受害方与非受害方的聚合单元的全集(攻击目标与非目标都要分析);
-
聚合分析:
对于安全态势数据中的管理不善的数据表现,计算一个聚合单元中命中的IP地址比例(fraction);
对于安全态势数据中的恶意行为数据,计算聚合单元中被列入攻击黑名单中IP地址的个数;
对受害方和非受害方均执行上述分析;
0×04 特征集
我们从所得到的处理过的数据中,分类成两类数据用于特征提取,一类是主数据集(Primary Set),用于表示原始数据;另一类是次数据集(Secondary Set),用于表示从原始数据中分析得到的统计数据。
实验共用到258个特征属性,其中隶属于主数据集180个特征属性,隶属于次数据集72个特征属性。
4.1 主数据集特征(Primary Features)
- Mismanagement Features:来源于前述的管理不善的五种数据表现,分别作为了特征。特征计算方法是计算配置不当的IP地址数量/聚合单元的IP地址数量,取值在[0,1]之间;
- Malicious activity time series:每个组织(聚合单元)收集三种恶意行为的时间序列,分别是spam、phish以及scan,其中第i个组织的三种恶意行为的时间特征如图6,
 且数据收集周期为60天,每个组织共180个记录特征,聚合单元的规模 Size 也作为一个特征;
且数据收集周期为60天,每个组织共180个记录特征,聚合单元的规模 Size 也作为一个特征;
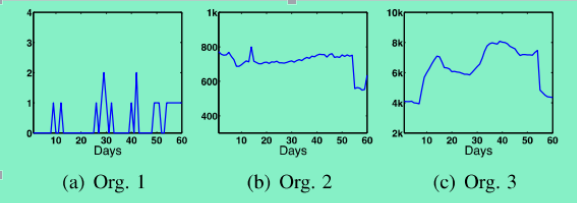
为了便于理解,我们给出三个组织中恶意行为时间序列的例子,如图7,其中Y轴表示60天的周期中,每一天出现在所有Spam黑名单上的唯一IP地址数量:
4.2 次数据集特征(Secondary Features)
从原始数据中分析获得的统计特征作为次数据集特征,这里引入了 Region ,概念,用于表示是图形中的特定区域,低于Normal的区域为正常(Good),高于Normaal的区域为异常(Bad),如图8:
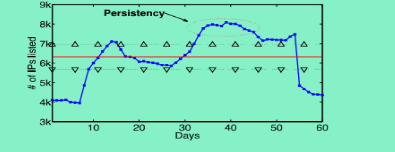
其中的红色实线表示Normal准线,高于红实线的区域为Bad,低的则是Good区域,持续性(Persistency)用于表示保持在同一个区域中的时间。
每个Region具备四个基本的统计特征:
- 归一化平均幅度(normalized average magnitude)
- 非归一化平均幅度;
- 处于该区域的时间;
- 进入该区域的频率;
- 一个时间序列具有good、bad、normal三个区域,因此一共有12个统计特征;同时每个聚合单元由三条事件序列(三种恶意行为),因此有36个统计特性,记为Fi;根据数据收集时间(60天和14天)又分为Recent-60和Recent-14两大类,总共72个统计特征;
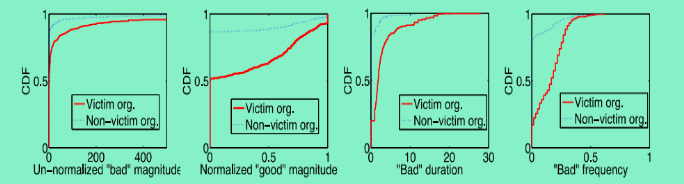
归一与非归一幅度的例子如图9:
0×05 训练与测试
数据处理完毕,提取到所需的特征集后,接下来使用 随机森林 构建分类器。
5.1 训练集构建
训练部分采用的数据集由两个部分组成,分别是Group(1)和Group(0); 安全事件中攻击目标的特征数据被作为Group(1),即安全事件发生; 从非攻击目标中随机抽取目标的特征数据作为Group(0),即安全事件未发生;
Group(1)特征集的抽取有着不同的比例,如50:50,意味着一半的数据用于训练,另一半用于测试,也可以是70:30;
Group(0)选取数据的过程会重复多次,每次都会通过RF学习获得一个分类器,最终实验预测结果是所有这些分类器预测的平均值;
5.2 随机森林分类器(Randome Forest Classifier)
Randome Forest,称作随机森林算法,是一种由多棵决策树组合而成的联合预测模型,天然可以作为快速有效的多分类模型;
简要介绍学习算法:
- 1. 用N表示训练例子的个数,M表示变量的数目;
- 2. 选择一个数m,用来决定在一个node上做决定时使用多少个变量,m<M;
- 3. 从N个训练案例中重复取样N次形成一组训练集合,并使用这棵树预测剩余案例的类别;
- 4. 对于每一个节点,随机选择该节点上的m个变量用于计算最佳的分割方式;
- 5. 每棵树都会完整成长不会剪枝;
5.3 测试
选择那些不包含在Group(1)中的安全事件数据加入到测试集,同时随机抽取非攻击目标的数据一起构建实验测试集。实验中根据预测的时间长短分短期预测(Short-term Forecasting)与长期预测(Long-term Forecasting),如图10:
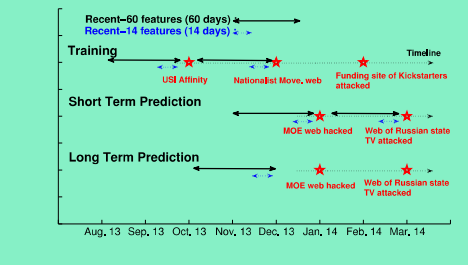
因为要预测安全事件的发生,因此采用的训练集必须在事件发生前的某个阶段。设定每个阶段为一个月(30天),一般对于短期预测而言,使用第一次安全事件发生的该阶段即可(30天),对于长期预测而言,训练集应当从测试集中安全时间第一次发生的阶段之前开始。
0×06 事件预测
实验预测结果如下,图11中展示了不同安全事件集中的事件预测的TP与FP的关系:
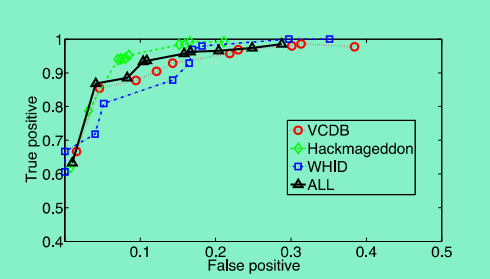
图12给出了上图中效果最佳的(TP, FP)值,如图12:

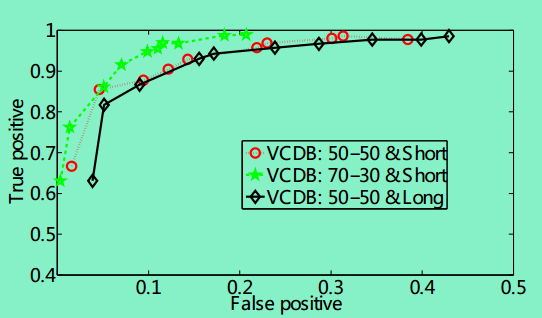
图13给出了同一个事件集VCDB上采用50-50/70-30的训练集/测试集比例效果对比,以及长短期预测的效果对比:
0×07 小结
我们今天介绍了一种基于安全态势的网络安全事件预测方法,其目标是能够仅仅基于组织网络外部的可观测信息,对该组织中可能发生的网络安全事件进行预测的预警系统。
预测中使用了258个目标组织/企业网络的外部可测量特征属性,一类是管理不善的特征,如配置错误的DNS或BGP,另一类则是恶意行为时间序列,如垃圾邮件、网络钓鱼,以及发自组织内部的扫描行为。
通过使用这些特性树形,建立随机森林分类器,实验针对约1000个事件训练测试了预测方法的准确性,最佳可以达到90%的正确检测率,10%的误报率。
0×08 参考文献
[1]. On the Mismanagement and Maliciousness of Networks, ZHANG, J, etc, NDSS’14
[2]. http://openresolverproject.org/
[3]. VERIS. http://veriscommunity.net/index.html
[4]. http://cbl.abuseat.org/
[5]. http://project.webappsec.org/w/page/13246995/Web-Hacking-Incident-Database
[6]. Syrian hacker Dr.SHA6H hacks and defaces City of Mansfield, OH website, http://hackread.com/ syrian-hacker-dr-sha6h-hacks-and-defacescity-of-mansfield-oh-website-for-free-syria.
[7]. Evernote resets passwords after major security breach, http://www.digitalspy.co.uk/tech/news/ a462959/evernote-resets-passwords-aftermajor-security-breach.html
[8]. Cloudy with a Chance of Breach: Forcasting Cyber Security Incidents, Yang Liu etc, 2015 USENIX
[9]. 网络安全态势感知, http://wenku.baidu.com/link?url=kNGzzx1r84u1ImJ7KkIESlnzI34FpJZLVtKZXEIUDmZxUTFUkfwj3Y3OAAxl3OchzMmHeupsI1dpFa-NW-W9m6rt50E5eAbx3AwOQKKPaYy
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

