争鸣:婚恋平台的推荐系统,怎么做才能助人脱单?
编者按: 社交软件尤其是婚恋社交平台不能让青年们脱单,说起来恐怕会让婚恋平台的工程师们沮丧。局内人的解释,是婚恋平台只能增大交友范围但不能精准、高效。那么,目前广泛运用的推荐系统能否帮上忙呢?辞旧迎新之际,@breezedeus(世纪佳缘研发中心总监吴金龙)总结了世纪佳缘4年来从算法到工程再到产品构建其用户推荐系统的经验,指出“推荐系统是为产品服务的,而不是直接为用户服务”。算法工程师@飞林沙(极光推送首席科学家黄鑫)却评论认为,除了传统的特征工程以及算法模型的优化外,明确推荐评价指标、Reciperocal Recommendation思想的业务化应用、从数据和算法出发的产品形态改进等8种做法才是婚恋网站推荐算法成功的关键。在此将两文及相关评论整理如下,供读者参考。
@飞林沙:世纪佳缘推荐系统之我见
昨天看到同事在朋友圈以及机器学习日报推荐的这篇文章: 《佳缘用户推荐系统》 ,再结合自己之前的几年的推荐系统经验,以及在婚恋网站半年多的经验,来谈谈我眼中的婚恋市场的推荐系统。
如作者所说,佳缘作为第一家也是中国最大的婚恋网站,的确在推荐系统上走了很多的弯路,但也正是这些弯路以及作者的分享精神,才给后来者的我们提供了许多一线的参考价值。我相信任何在今天看来不完善的,甚至有一些可笑的设计,在当时都是有着合理性和必要性的。那么我再回顾自己的2011年如果开始从头搭建这样一套系统,是否能做成这个样子,自认也没有这样的把握。所以这篇文章纯粹是站在我今天的角度来做点评和分析,也望大家多多探讨。
一、推荐算法的问题
首先,我们先顺着作者的思路去看佳缘经历的推荐算法:
在2011年到2013年的算法年,佳缘尝试了两个算法方向,与我的想法非常背离,第一个不是最基本的Content-based,而是Item-based,相信Item-based算法大家都再了解不过,所以就不多做解释。我们只来分析算法的业务应用。Item-based是在构建一个User-Item矩阵,然后计算Item-Item之间的相似度。那么具体到婚恋网站的业务场景,其实也就是构建了一个Man-Woman的矩阵,将Woman当做Item,计算Woman之间的相似度,这个算法场景基于背后的假设是认为,如果一个男人喜欢一个女人,那么他必然喜欢和这个女人相似的女人,换句更直白的话说,每个男人都喜欢自己女朋友的闺蜜。相似,我们将User-Item矩阵做转置后,可以继续做Man的相似度,不再复述。
这个算法设计有如下几个问题:
- 如作者所说,给男性展示美女,男性的发信就会暴涨,这样少量女性收到大部分信,而大多数女性却收不到信。但是作者可能没有把这部分给说透,如果单纯从这一点来看,这并不是协同过滤算法本身的原因。这其实是一个恶性循环,算法本身就是基于了一个严重有偏的User-Item矩阵来计算相似度,于是产生的推荐结果最终会造成给所有人都推荐美女。
- 但是这并非是一个无解的问题,我们回归Item-based的本源思考为什么热门的条目会受到额外的照顾,抛出业务场景,其实根源在于Cosine-Similarity里分母开的那个根号惹的祸,可以想象10000的平方根和1000的平方根到底有多大差别,其实罪魁祸首就是平方根弱化了热门条目的作用,如果一定希望去调整,可以根据实际的业务情况去调整指数。
- 稀疏性问题。对于婚恋网站来说,长尾性和稀疏性比传统的条目网站都大得多,大家可以想象一下大多数人来婚恋网站的目的,以及走在大街上看到美女的概率即可,所以单纯的Item-based是无法解决问题的,只会造成大部分人可能一辈子都收不到一封信。但是这其实也有解,最粗暴的方法就是对于一部分用户配合Content-based做随机展示(对于展示哪一部分,我们之后再来具体说)。
- 协同过滤的传统问题,就不多说了,比如说实时性,参数调整的复杂性等等。
- 具体到婚恋业务上来说,“如果一个男人喜欢一个女人,那么他必然喜欢和这个女人相似的女人”这句话结合业务场景和业务目标是有着悖论的,我们做个逻辑推演,如果我喜欢某个女人,就会给这个女人发信,如果这个女人理我了,我就愿意和她“结婚”(记住,这里不是约炮),那么我就不会也不应该再去找其他女人。 如果这个女人看不上我,那么和她相似的人也不会看上我….. 所以…..我想大家应该可以明白这个其中的问题了。
第二个尝试也是我曾经有段时间努力探索的:Reciprocal Recommendation。也许大家对这个不熟悉,我大概讲一下,这种推荐算法广泛地应用于双向选择的业务场景下,例如求职网站,交友婚恋网站。不同于传统的网站推荐系统,搭建的是基于条目的推荐系统,或者是基于用户单向关注的推荐关系。求职网站给我推荐了一份Google CEO的工作,我会感兴趣,但是他对我不感兴趣是没有意义的。婚恋推荐也是如此。
那么这个算法解决的出发点很好,但是实话实说,其实paper一共就那么多,我总结着看了下,并没有真正有用的东西,也没有创造性的模型产生,只是对于传统推荐算法的一个后过滤, 整体思路就是把曾经的无向图变成了有向图,分别求出Man-->Women,Woman->Man的双向关系,然后或者相乘,或者搞一些奇怪的公式去做拟合。 作者说不太靠谱,但是我认为这个算法从思路上来说是对路的,无论是不是用他们那些莫名其妙的模型,但是作为思想的参考还是值得借鉴的。
二、比拼特征工程是另一个极端
接下来佳缘推荐算法的阶段步入了2014的工程年,作者根据佳缘的团队及业务特点将佳缘推荐做了战略上的调整,从比拼算法模型改成了比拼特征工程。我不了解佳缘的实际情况,不敢多做评价,只是从个人感觉来说也许作者从一个极端走到了另一个极端。从外界来猜测一下佳缘的实现思路:抽出各种各样的特征,例如用户的基本人口学信息,加上用户的行为属性信息等等,然后针对每个用户训练一个分类器,来预测他是不是对对方感兴趣。
那我们来聊聊 逻辑回归的根本问题 吧:
- 大部分信息大多都是离散值,而这些离散值之间并非是按照数字本身的意义有着明确的大小关系,这个如果用逻辑回归,就会面临让人绝望的离散值连续化问题。
- 如果把希望寄往于特征工程,就需要对每个特征都做深入的业务和数学化理解,而且调参这个事儿结合到婚恋网站超长的训练反馈链,几乎是无解的。不要去讨论非监督化的特征工程了,因为婚恋网站的业务特别明确,人工特征往往比泛化的非监督特征工程好用得多。
- 高维特征下逻辑回归一样会面临维度爆炸的问题。
- 逻辑回归本质上是广义线性模型,但是这个假设是不是适用。
- 最关键的是,逻辑回归其实和最基本的感知机有什么不一样,从图形上面最基本的理解,其实就是把最两端的长尾巴给压缩了一下,但是对于婚恋网站来说,恰恰最需要的就是这些长尾巴的东西,因为这些长尾巴是最能让人付费的动力。
三、结合业务模式的改进思路
我相信接下来我说的很多尝试和做法,佳缘都已经尝试过了,但是站在局外者的角度,我认为 除了传统的特征工程以及算法模型的优化外,其实接下来的这些才是婚恋网站推荐算法成功的关键 (结合佳缘的模式: 收取用户的看信费用,其实我没用过):
- 明确推荐评价指标。 这一点是老生常谈,做任何一个系统前,尤其是数字化系统时,最重要的就是明确建立这个系统的指标。对于婚恋推荐系统来说,最核心的指标无外乎付费的转换率,那么继承OKR的思路,我们来对这个指标进行拆解Key Result,想提高付费转换率有几点需要提高: A. 收信人的覆盖率 B. 发信者的动力 C. 收件人的看信意愿(付费意愿),那么接下来逐渐说。
- 识别优质资源。 对于婚恋系统来说,帅哥就那么多,美女也就那么多,付费用户更是就那么多,所以识别用户成为了婚恋网站的重中之重。所以婚恋网站的第一步不是推荐问题,而是一个用户从多维度的分类问题。
- 懂得取舍 。我们继续做逻辑推演,用户到底愿意给什么人发信,但是到底什么人才愿意让用户看信。接下来什么用户才会愿意为了一封信而付费。其实这个时候问题已经变成了,如何给优质用户看到他感兴趣的人,而这个人又对他感兴趣,而且这个人恰恰又愿意付费。这个逻辑链条太长了。根本没办法来做,我们来精简逻辑链条,发信其实是成本最低的,而且可以通过鼓励或者产品引导来让用户发信,所以我们把第一层逻辑去掉。我们倒着来推,把问题转换为识别出最愿意付费的那些用户,然后找到这些用户感兴趣的用户,通过产品引导让这些用户发信。
- 推荐理由 。对于婚恋推荐来说,推荐理由比传统的网站要重要得多,因为你要明确给用户一个付费的理由,关于传统的推荐理由,就不再复述了,无外乎你们具有相同的属性,喜欢这个人的也喜欢,等等。但是最近的那篇也许会给我们一些额外的启发,大家也可以直接看我之前的博文: <商品推荐算法 & 推荐解释> 。
- Reciperocal Recommendation思想的业务化应用 。在之前,我简化了发信者发信这一链条的联系,但是如果精细化来说,不妨用这样的思想来做发信者和收信者之间的平衡。
- 在做分类以及评分预测时,不妨 针对业务的长尾现象来做模型改造和模型选择 ,因为只有小部分用户是必须要牢牢抓住的用户,从这一点来说,逻辑回归确实不合适。
- 我扫了下作者2015的展望,我很期待,尤其是ADMM的应用,目测我还没见过身边有人搞过,期待作者的尝试结果。但是特征哈希这个事儿真的不靠谱,因为 如果决心做特征工程,那么特征哈希这个事情就显得太远离业务本身而注重于泛化了 ,这样子不适合逻辑回归+特征工程这样的战略。
- 从数据和算法出发的产品形态改进。 这个没什么好说的了,其实我一直认为婚恋网站的出路不在于算法和数据本身,而是能不能从数据跳出来对产品提出一些创意性改进从而产生的产品模式和收费模式的变革。去年我和很多VC聊过现在国内资本市场对于婚恋市场的看法,大家无一例外都是摇头,婚恋市场太久没人去变革过了,至今的几大网站仍然是十年前的玩法。
说归说,我很佩服作者几年来一直坚持着做着同一个产品的推荐算法,也希望大家可以多多讨论。
@飞林沙: 推荐算法的经验
在 <商品推荐算法 & 推荐解释> 一文中,@飞林沙表示,我们 做推荐算法的时候要考虑 :
- 推荐的递进性 ,我们过去无论在做商品聚类,还是基于标签推荐时,都是基于一个无向的“图模型”。
- 区分出互补性和替代性 ,这一点其实我承认过去并没有系统地考虑过,我们通常的推荐都是基于互补性的。
但是从工程角度上,并不适合上来就搭建这么复杂的模型,所以我们 可以适当做简化 ,例如:
- 认为相同目录下的商品是替代关系,不同目录的商品是互补关系。
- 通过抽取不同类目的关键词和情感词,给每个类目一组关键词,例如鞋子可以分成Size, 颜色, 舒适度,性价比等,然后通过关键词抽取对商品的不同维度去做分级,从而在推荐理由的时候就可以形成推荐产品的递进关系。
- 做topic model的时候也应该是同一个类目下做,这样计算量也小了很多。
- 使用买了也买的link关系训练topic model中不同维度的权重时,只训练同一子目录就够了,因为不同目录下的商品的topic之间其实没啥联系。
@飞林沙认为,数据挖掘或推荐系统只要达到目的就足够了,用什么模型其实真的没有那么重要, 优化了好久的模型还真的不如加两条规则,或者人工清洗一下数据好用 。 模型真正的价值是泛化 ,但是对于工业界来说,泛化能力不需要太强,只要限定在当前的产品线就够了,如果产品形态改变可以再来一个算法。
@breezedeus:认同根据业务细分用户群体
对于@飞林沙的评论,@breezedeus的回应如下:
谢谢@飞林沙 细致的评论。我原文更多的是从系统的方向来说的,而这篇文章主要从算法来说明,刚好是个补充。虽然我不同意@飞林沙 的很多看法,比如对knn的解释没有考虑我们当时的主要目标是发信量,但有一点我很认同,就是根据业务细分用户群体。婚恋业务很复杂也很特别,欢迎牛人加入我们。
@breezedeus在原文中提出了自己的感想:
技术为产品服务,而不是直接面向用户
数据质量是地基,保证好的质量很不容易
如何制定正确的优化指标真的很难
业务理解 > 工程实现
数据 > 系统 > 算法
快速试错
他还曾在微博中写过如下评论:
很多刚工作的同学,最喜欢干的事就是套算法,认为懂了算法就什么都会了。真实产品基本都是数据 > 特征 > 算法。算法真不是那么重要!
@breezedeus:佳缘用户推荐系统
天真的算法年:2011-2013
2011年8月我加入世纪佳缘,开始时主要负责佳缘的交友推荐系统优化,后来我这个团队也负责其他的机器学习事情,比如佳缘的网警系统(抓恶意用户)。刚来时团队加上我只有3个人,做的事基本集中在推荐系统,以及对业务部门新产品的接口支持。当时我自己并没有推荐系统应用于工业界的实际经验,所以很想当然地就从自己了解的推荐算法开始工作了。
2011年到2013年中这段时间,我们在算法方面主要做了两个方向的尝试。第一个是尝试item-based kNN算法。对这个算法的优化尝试体现在以下几个方面:
- 离线计算效率的优化 :从开始的单机计算,到后来的Hadoop分布式计算。
- 离线计算效果的优化 :尝试了不同的相似度计算方法,以及不同的预测产生方式,但效果并不明显。
- 离线计算改为线上实时计算 :离线的工作方式是先在线下计算好推荐结果,然后把结果存入缓存;线上需要推荐结果时直接从缓存中取即可。显然这种方式对于缓存中没有推荐结果的用户无法产生推荐,而活跃的用户又很容易把缓存中的所有结果都消费完。为了解决这些问题,后来我们在Dubbo上构建了实时的Java推荐服务。
Item-based kNN算法的尝试最开始是基于最大化佳缘用户发信量的业务理解,但后来我们发现这个理解跟业务部门的需求偏差很大。比如给男性展示美女,男性的发信就会暴涨,但这样就会导致少量的女性收到大部分信,而大部分女性则没信可收。这是业务部门不愿意看到的。虽然我们尝试在item-based kNN基础上做调整来平衡其他的业务指标(如收信人数,看信人数等),但效果不理想。
第二个尝试是学术界的 可逆(Reciprocal)推荐算法 1,即在考虑用户体验的同时也兼顾item(对佳缘来说也是人)的体验。这个尝试基本是失败的,学术界发明的那些算法基本都有各种前提假设,真用起来都不太靠谱。
虽然到2013年我们团队人数上升到了六七人,但基本在推荐算法上做事的人还是只有两个左右。
工程年:2014
从2013年底开始我逐渐意识自己对算法的理解过于学术而无法满足业务部门的实际需求。所以从2013年底我开始从业务出发重新梳理推荐算法团队的工作方向。相对于给用户推荐物品的场景,佳缘的在线交友推荐有以下几个特点:
- 可逆性 :佳缘的物品是异性的人,他们也会有感受。所以在推荐时要考虑到双方的感受。
- 资源独占性 :通常一个人在一段时间内也就和一个人谈恋爱。这与电商卖东西是差别很大的,一本相同的书可以卖几十万册都可以,在佳缘这么干就不行。电商可以搞个畅销榜让用户购买最畅销的书,这其实也是很好的推荐。但对于佳缘这一招就很糟糕。
- 转化链很长,反馈延迟 :从展示到发信,再到看信和回信,过程很长,而且看信和回信又会有很长的时间延迟。另外,收益在转化链的末端才能体现。公司的收益在看信后才能体现(佳缘的业务模式是收取用户的看信费用),而用户的收益在回信后才能真正体现。

转化链很长,反馈延迟
佳缘业务的高复杂性,加上团队在使用算法上经验不够,让我决定把接下来的算法优化方向放在特征工程上,而算法就限制在最简单的 逻辑回归(Logistic Regression) 。团队在处理特征的过程中可以积累对数据的处理经验,以及对业务的理解。逻辑回归足够简单,解释性好,也有很好的开源实现。从它开始也可以让团队在算法使用上积累心得。这是“战术”上的第一个选择。我们把上图中每一步转化作为单独的问题分别进行优化,这样逻辑回归就适用于每一步。这是“战术”上的第二个选择。
上面说的“战术”,其实针对的只是推荐系统里的排序系统。当时我对推荐系统整体的想法是把运营需求和用户需求分开,然后分别对他们进行独立优化。具体说就是第一步以满足运营需求为目标获得候选集,而第二步是根据用户(双方)的喜好对候选集进行排序,系统流程图见下图。这样,在优化用户需求时就不需要考虑佳缘复杂的业务逻辑,可以极大地简化问题。同样,我们也可以比较独立地优化满足运营需求的候选系统。这可以认为是推荐系统的“战略”方向。

佳缘推荐系统流程图(2014)
2014年无疑是工程年。
产品年:2015
2014年工程年的效果还是不错的,多个转化模型的分别构建和组合使用,使得业务上的各个指标都有所提升,很多指标的提升幅度都超过了50%。
现在看来,2014年的战术是非常正确的。花了一年时间在特征工程上,团队确实对业务数据的理解更深入了很多,也积累了模型优化的一些经验。战略上虽然大方向没错,却也存在一些问题。首先,运营需求与用户需求本来就是相关的,它们不可能完全独立,我们在优化一个指标的同时很容易对另一个指标产生副作用。
例如,按照上面的流程图,第一步的候选系统通过考虑运营需求来产生候选集,然后候选集由考虑用户需求的排序系统进行排序。如果产生的候选集很小,那排序系统的优化空间就很小,作用自然也不会大;而如果候选集很大,那通过排序系统排序后获得最终推荐结果的做法就会降低运营需求的控制力度。
2014年底的时候我开始考虑2015年推荐系统团队的工作方向。那段时间我集中看了很多公司推荐相关的资料,其中几年前百度大推荐部门(现在已经解散)公开的一些演讲资料对我启发最大。很多公司讲推荐的资料都注重讲算法,或者数据和特征;而百度的这些资料主要偏向于从系统方向来讲。这启发我回到排序系统的本质来看推荐系统。
搜索,广告和推荐系统,本质都是大规模排序系统。它们都遵循“候选产生 –> 排序 –> 后处理”的一般流程(见下图)。
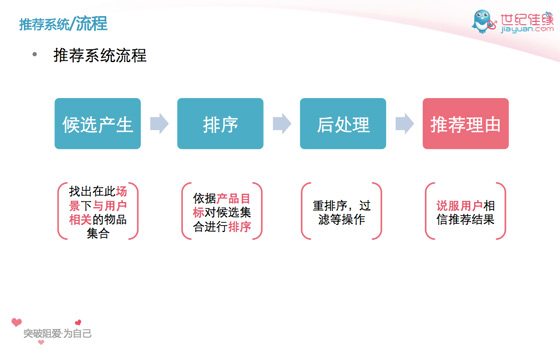
推荐系统通用流程图
再仔细说明下上面这个流程中的前两步:
- 候选产生(检索)系统 :找与用户相关的候选集合。对于佳缘来说,这里的相关候选集合可以通过(互相)满足择偶条件来获得,也可以通过算法如kNN,AR等来获得。不管用什么方式,最终目的就是把用户与候选集合联系起来。
- 排序系统 :排序系统里的排序目的是最大化产品目标。对佳缘来说,产品目标包括了运营目标和用户满意度。
相对于2014年运营需求与用户需求独立优化的“战略”,2015年的优化思路有所调整:
- 分离出运营需求中与用户需求耦合小的部分,使用规则控制 。这样做的原因主要还是佳缘的业务逻辑太复杂,完全依靠算法达成产品目标很困难,所以加入了一些规则进行宏观控制。
- 统一优化无法分离的运营需求与用户需求 。这种统一不仅体现在排序系统会同时考虑这两方面的指标,也会以较弱的形式体现在候选产生系统里,毕竟从候选产生系统产生的候选集不可能是所有与用户相关的物品(异性)。
那么,为什么把2015年叫做推荐系统的产品年?因为今年推荐系统的目标是优化产品目标!
推荐系统是为产品服务的,而不是直接为用户服务。
上面这句话听起来很简单,但其实很多时候我们会在不知不觉中认为推荐系统是直接在为用户服务的。我们在最早的时候就是犯了这个错误。
本节的最后, 汇总罗列下我这几年做推荐的感想 :
- 技术为产品服务,而不是直接面向用户
- 数据质量是地基,保证好的质量很不容易
- 如何制定正确的优化指标真的很难
- 业务理解 > 工程实现
- 数据 > 系统 > 算法
- 快速试错
@breezedeus: 一些技术尝试
这节我只是简单罗列下最近几年自己接触的比较有代表性的一些技术,跟工作关系不大。
- Dirichlet Process 和 Dirichlet Process Mixture模型
了解DP主要是因为当时在看Mahout源代码的时候发现有个算法以前竟然没接触过,觉得挺有意思就仔细学了下。DP不太好理解,它被称为分布的分布。从DP抽取出的每个样本(一个函数)都可以被认为是一个离散随机变量的分布函数,这个随机变量以非零概率值在可数无穷个离散点上取值。DPM是非参数贝叶斯聚类模型,聚类时可以让模型自动学习类数。虽然听着好像很不错,其实有很多槽点,具体可见参考文献2(参阅参考文献请点击原文链接)。
- Latent Dirichlet Allocation (LDA)
LDA是文本处理里的利器,经常被用于对文本进行聚类,或者预处理。更详细的理论介绍可见参考文献3。当时我尝试把它用于佳缘的发信数据,看看能不能找出一些有明显特征的发信群体。聚类结果整体上基本不可解释,但有一个类别意义很明显,这类人主要给离婚异性发信。大家可以想想这类人是什么人。尝试感想是LDA直接用于聚类未必靠谱,但是可以把它用于数据的预处理,比如降维什么的。
- Alternating Direction Method of Multipliers (ADMM)
ADMM是个优化算法框架,它把一个大问题分成可分布式同时求解的多个小问题。理论上,ADMM的框架可以解决大部分实际中的大尺度问题。槽点很多,谨慎使用!更详细的介绍可见参考文献4。
- Deep Learning
前段时间,我利用佳缘的用户头像数据,尝试了DL里的一些常用算法。为了看算法的效果,我把用户的性别作为预测目标。这种预测对于佳缘的业务直接意义不大,因为用户在注册时就被要求填写其性别。
算法预测的效果还是不错的,准确度达到了87%。这还是在很小训练集上训练后获得的精度。DL麻烦是训练时需要调整的超参数实在是太多了,改一次超参数就要重跑一次,真的是很耗时。没有好的计算资源的话,建议别考虑DL。
- 利用GBDT模型构造新特征
实在想不出更多的有用特征?尝试下Facebook提出的利用GBDT来构造新特征的方法吧。我们的使用经验表明确实还是挺靠谱的,只要你效率能扛得住。具体介绍可见参考文献5。
- 特征哈希(Feature Hashing)
很多个性化特征?特征数量太多?试试特征哈希的方法吧。此方法我们目前也没使用过,欢迎有经验的人发表意见。具体介绍可见参考文献5。
- 不平衡数据的抽样方法
正负样本数量差异太大?训练样本太多机器跑不动?尝试下参考文献7中的抽样方法吧。我们之前的尝试表明还是有点作用的。不过如果你的数据不是大得跑不动,那尝试的必要性就不太大了。
朋友,看完了两位的观点,您对推荐系统的构建有其他的观点吗?如果您希望加入讨论,请将稿件投递至小编邮箱:zhoujd@csdn.net。
原文链接: 世纪佳缘推荐系统之我见 , 商品推荐算法 & 推荐解释 , 佳缘用户推荐系统 (责编/周建丁)
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

