美团在Redis上踩过的一些坑
版权声明:小午许整理。转载请联系听云College团队成员阮小乙,邮箱:ruanqy#tingyun.com
美团使用的在线储存数据库有很多,其中主要就是MySQL和Redis、还有Oracle、Postgis。接下来的内容就详细描述下美团在使用Redis上遇到过的问题。
谈到Redis,非常好的地方在于它的功能性丰富,支撑的数据形式多样化。作为一个开发人员,这些多样化数据类型对于架构会有非常大的帮助。其次,它还支持非常重要的功能就是Lua脚本,这些在特殊的场景下使用起来不会太复杂,同样Redis也支持持久化、过期时间,性能非常高。如今在国内外,Redis的使用范围非常广泛。说到这里,也想提醒大家在选型使用的时候,最好选择开源的并且使用非常广泛的,这样有很多好处,过程中遇到的问题之前会有很多人发现,可以在网上查找解决方法以及如何规避,问题就会少很多。
一、持久化:
Redis的持久化分为两种
-
rdb(定期全量snapshot的方式)
-
aof(追加日志的方式)
这两种方式各有优缺点,如下图
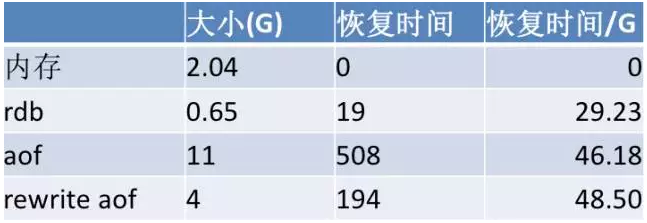
如果Redis在内存里边总共2G,rdb只有0.65G,aof就需要11G,当然这也会跟场景有关系。再看简单测试恢复时间,rdb只需要19秒,aof用了508秒,假设先不考虑恢复场景,单纯恢复的效果和存储来看rdb比aof好很多。由于是定期的snapshot,所以中间的数据会丢失。这样来说也需要了解它们之间的差异。
二、周期性connect timeout
首先遇到一个问题是业务部门反馈他们的Redis周期性出现connect timeout,然而之后费了很多精力却没有找到。经过对比监控发现TPT数量周期性变得很高,又从这个问题出发去找原因,最终发现与TCP三次握手有关系。
listenoverflows表示在TCP建立三次握手过程中,服务器在收到客户端发送的ack之后,会将连接放在accept队列中,等待上层应用调用accept,如果上层迟迟不调用accept,处于established的连接超过了accept队列的容量。在发给客户端SYN和SEQ时,如果一直不调用SYN方法,机器中间有队列的,队列满了之后会发生异常。

Redis的实践模型用的IO,将事件处理器、命令请求处理器、命令回复处理器、连接应答处理器连接在一起。在使用Redis的过程中,如果有一个命令执行时间非常长,导致Redis迟迟没有响应,监控项就会看到它的值特别高,接连客户端会报警。那么知道整个事情原因之后,怎样解决这个问题呢?

很重要的一点是,首先我们知道连接慢是由于一些命令执行过久导致的,可以对慢查询增加监控。如果执行时间很长,Redis处理请求能力会急速下降。这时可以使用脚本持续的将慢查询进行收集,收集起来存到库里边随后告诉开发人员发现Redis里边有慢查询,将原始的发现过程详细描述出来,问题自然得到优化。
三、bgrewriteaof的问题
bgrewriteaof最主要的问题是可能会出现swap,这样一来请求会变的非常慢。还有一个现象是经常出现oom。导致这两个现象的原因分别是
-
Fork子进程(copy-on-write)
-
子进程遍历所有key写入临时文件
-
父进程更新aof写入缓冲区
-
缓冲区追加临时文件
-
替换已有的aof文件
这个问题怎么解决?
第一个方法简单暴力:关闭aof。这个是要根据场景进行选择,对数据要求较低,很快可以重建出来并且访问量大可以选择关闭aof。
第二个方法是在数据要求很高不能丢失定期备份的情况下:写一个bgrewriteaof集中控制。这样做不但可以错开高峰期,还避免了同一台机器同时进行。
四、内存占用飙升
使用Redis的过程中出现了一个很怪异的问题,就是会看到Redis内存呈以相当高的速度增长,排查很久发现有一个奇怪的地方,可以看到Client为非常大的值。

为了查找原因就把Client list打印出来,可以看到有一个omem用了7个G,而且从ID可以看出线索里有一个Client导致内存非常高。就找到业务方询问是不是执行monitor,最后停掉,整个内存快速降了下去。
解决这个问题的方法就是在测试环境复现。连接到Redis上,正常执行monitor性能会下降非常厉害,但是不会出现内存突增的情况。还有用ctrl+Z将job stop,这样job无法读取client output,再通过Client list观察。
五、内存使用优化
讲过内存使用飙升的问题,下面来讲下内存使用优化的技巧,就是将string转化hash。
实现方法:
-
使用Redis字符串数据结构, userId为key, weiboCount作为Value
-
使用Redis哈希结构,hashkey只有一个, key="allUserWeiboCount",field=userId,fieldValue= weiboCount
-
使用Redis哈希结构, hashkey为多个, key=userId/100, field=userId%100, fieldValue= weiboCount
六、Cluster遇到的一些问题
-
master和slave在同一台机器部署
-
基本上Redis实例本身不会挂掉,通常是机器出了问题(断电、机器故障)、甚至是机架、机柜出了问题,造成Redis挂掉。
-
如果Redis-Cluster的主从都在一个机器上,那么如果这台机器挂了,主从全部挂掉,高可用就无法实现。(如果full converage=true,也就意味着整个集群挂掉)
在后来的修复过程中,创建集群就是用redis—trib .rb创建,如果在同一个机器需要手工迁移,在使用过程中要注意。
-
Redis-Cluster误判节点fail进行切换
-
Redis-Cluster是无中心的架构,判断节点失败是通过仲裁的方式来进行(gossip和raft),也就是大部分节点认为一个节点挂掉了,就会做fail判定。
-
如果某个节点在执行比较重的操作(可能短时间redis客户端连接会阻塞(redis单线程))或者由于网络原因,造成其他节点认为它挂掉了,会做fail判定。
-
Redis-Cluster提供了cluster-node-timeout这个参数,作为fail依据
七、Redis安全漏洞
很多人反映Redis有安全漏洞,安全漏洞会导致别人可以通过你的Redis达到机器平衡,并且连接进去。有两个前提条件,一个是Redis未添加认证,第二个是Redis以root用户启动。
八、其他问题
使用Redis的过程中,需要Redis配备充裕的磁盘空间。像之前遇到过一个问题,启动量特别大居然将磁盘写满,Redis会直接出现Redis直接不响应请求或停止的情况。另外就是网卡软中断,使用Redis的时候,在一个机器跑很多的Redis实例,而Redis网卡的软中断非常高,需要网卡软中断分布在所有CPU上,而不是一个。
想阅读更多技术文章,请访问听云技术博客,访问听云官方网站感受更多应用性能优化魔力。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

