产生环境下的性能监控 - Datadog
排查性能问题往往比排查功能性的Bug更让人头疼,主要有以下几个原因
- 很多性能问题只会在高负载的生产环境下出现,在开发过程中很难发现。
- 功能性出错时我们通常会抛出异常,我们可以通过Tracestack很快定位到问题所在代码的位置。但对于性能问题,我们很难做这样的快速定位。
- 虽然我们有各式各样的Profiling工具,但适用于对生产环境的并不多。当然这因编程语言而异,Glow服务器端的技术栈是Python + Gevent,目前为止我们都没有找到合适的Profiling工具。
对于服务器端的性能问题,我们常用的方法是写日志文件,例如把每个请求的响应时间都记录下来,但对海量日志文件的存储,聚合与分析又成了另一个麻烦。常用的解决方案有ElasticSearch + Logstack + Kibana,或是StatsD/CollectD + Graphite等等。在Glow,对于性能监控这样的通用服务,我们更偏向于选择云服务,而不是自己去维护这些系统,这样我们的精力才能集中在产品研发上。
在对于性能监控类的云服务做了一些横向比较后,我们选择了Datadog,使用一年多,感觉很不错,所在在这里分享给大家。
Datadog简介
Datadog的工作方式是在每一台需要监控的服务器上运行它的Agent。Agent不但会收集这台服务器的各类基础性能数据,如CPU使有率,剩余内存空间,剩余磁盘空间,网络流量等,也可以收集用户自定义的性能数据,灵活性很好。
Datadog另一个好用的地方在于它与 众多的云服务和开源项目有整合 ,我们在实际用的整合有
- AWS EC2
- AWS RDS
- Redis
- Nginx
- Slack (用来报警)
下面图中是我们一台Redis服务器的监控面板,除了可以看内置的基本性能信息外(CPU,内存,网络等),也可以实时地看到Redis服务器的连接数,Key的总数,每秒接收到指令数等,相当实用。 
Datadog也可以对各种监控的性能指标设定阈值,当指标超出阈值范围时,发出警报。我们可以利用它与Slack的整合,直接将警报推送到Slack上。

自定义指标 - Custom metrics
虽说Datadog内置系统监控以及第三方整合都很好用,但它真正强大之处在于可以方便地自定义指标。这些自定义的指标可以是Web server对每个请求的响应时间,或是数据库中每张表的读写请求数,也可以是Job queue里pending的job数量。因为可以自定义想要收集的数据,所以不会受限于Datadog原生提供的功能,这也是当初我们选择这个云服务的主要原因。
Datadog的自定义指标有两种类型Count和Histogram。Count比较直观,就是用于记数,用来统计某个事件在一个时间区间内发生了多次次,例如我们可以定义一个 page_view 来记录应用中每个页面的访问次数。但在性能监控中,Histogram更为有用,它的每个数据点是一个时间戳加上一个浮点值,所以它不但可以统计某个事件在一个时间区间内发生的次数,也可以统计这些事件所对应的浮点值的平均值,中位数,最大值,最小值等等。如果这听起来还是比较抽象,一个实际的例子就是记录服务器对每个请求的响应时间。用Histogram来记录,我们就可以方便地得到某个时间段的平均响应时间和最长响应时间,而这两个数据对于性能监控至关重要。
对发送到Datadog的每个数据点,我们都可以添加多个tag,这对于之后数据的查询与分类非常有帮助,比如我们可以根据数据来自哪个microservice,给它们打上不同的tag。在实际使用中,我们会以更细的粒度在数据点上添加tag。
下面是向Datadog发送自定义指标的Python代码示例,其中 statsd 是Datadog提供的一个类库。
from statsd import statsd # send count data statsd.increment('event.page_view', tags=['app:glow', 'page:home']) # send histogram data statsd.histogram('service.response_time', 0.2, tags=['app:nurture', 'service:user', 'api:get_user_by_id']) 第一个例子我们用 statsd.increment 来发送Count类型的数据,通过两个tag,我们告诉Datadog,这次访问发生在Glow app的Home page上。之后我们可以在多个粒度上统计某段时间内页面访问的次数
- Glow的Home有多少次页面访问
- Glow app有多少次页面访问
- 所有的app总共有多少次页面访问
第二个例子我们记录的是Histogram类型的数据。这里假设在我们的Nurture应用下,有一个专用于读写用户数据的User service,某次访问该服务下 get_user_by_id 这个API的响应时间为0.2秒。通过三个tag,我们之后可以在下面几个粒度对某段时间内的响应时间进行统计
- Nurture app的响应时间
- User service的响应时间
- User service下
get_user_by_id的响应时间
在Datadog上建立Dashboard
当我们把想要监控的数据发送给Datadog后,下一步就是将统计数据可视化,这一步可以通过在Datadog上创建Dashboard来完成。虽然Datadog提供了很多种图表的类型,但最常用的是Time Series和Top List。前者用于显示某组指标在一段时间内的变化,比如查看服务响应时间在最近24小时内的变化曲线。后者用于显示在某段时间内某一指标的排名,比如查看最近24小时响应时间最长的10个API。
下面看一个简单的Time Series Graph的例子
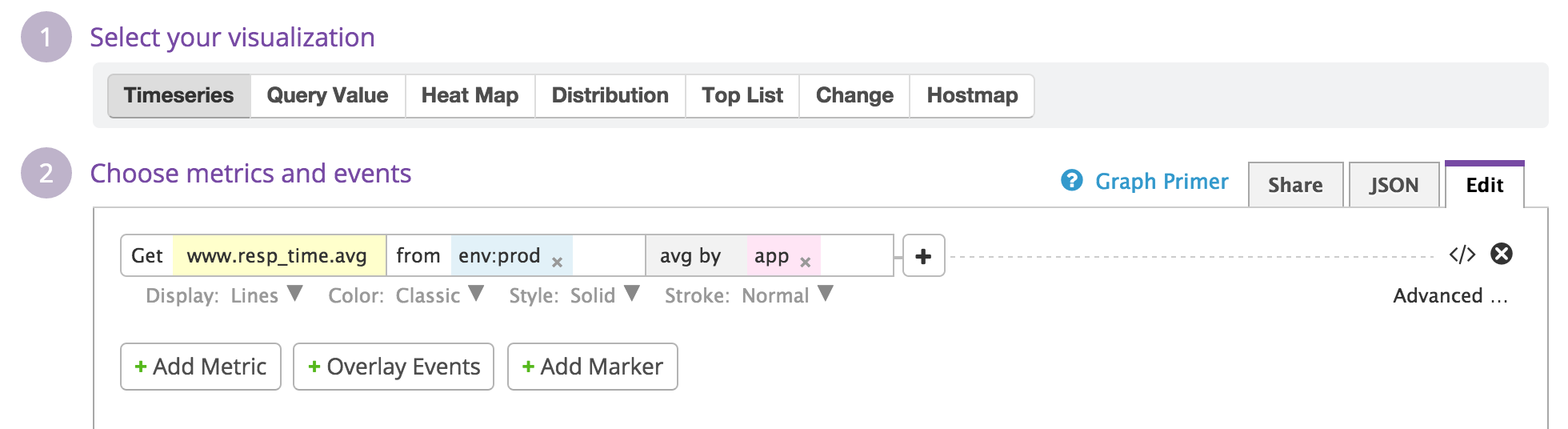
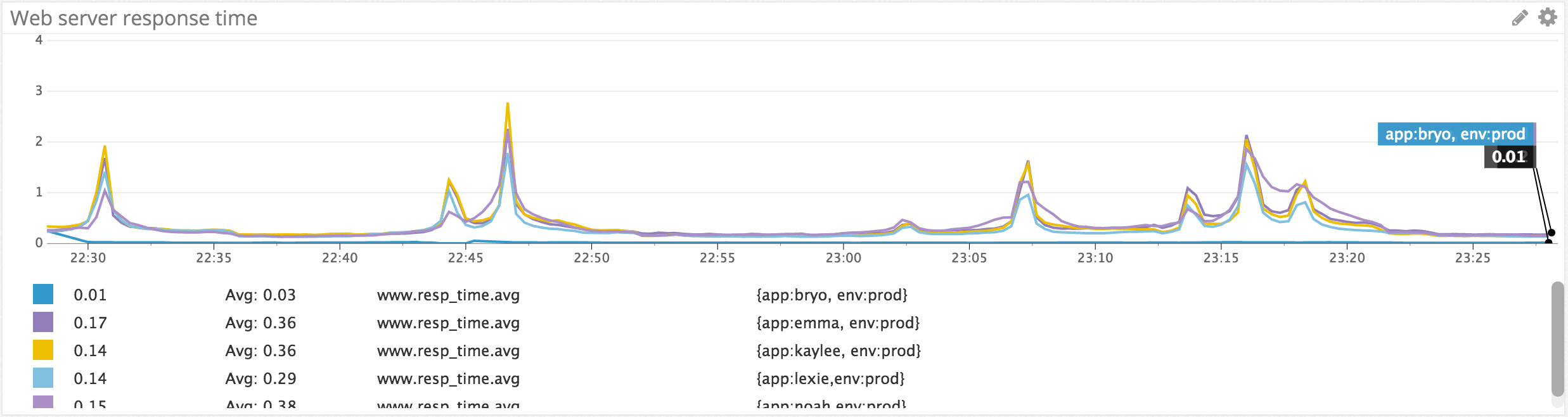
这里用的自定义指标名为 www.resp_time (web响应时间),它是从我们的代码里通过 statsd.histogram 发送到Datadog的。 from env:prod 限定了我们只关心生产环境下的数据,后面的 avg by app 表示在图中显示每个app响应时间的平均值。这里 app , env 都是在发送数据时附加在 www.resp_time 上的tag。下图是某段时间内响应时间的变化曲线,那段时间服务器有些不稳定,虽然平均响应时间在0.2 - 0.4秒之间,但一些时间点上的峰值超过了2秒。其中 bryo , emma , kaylee , lexie 等等都是我们app的code name。
下面再看一个的Top List的例子
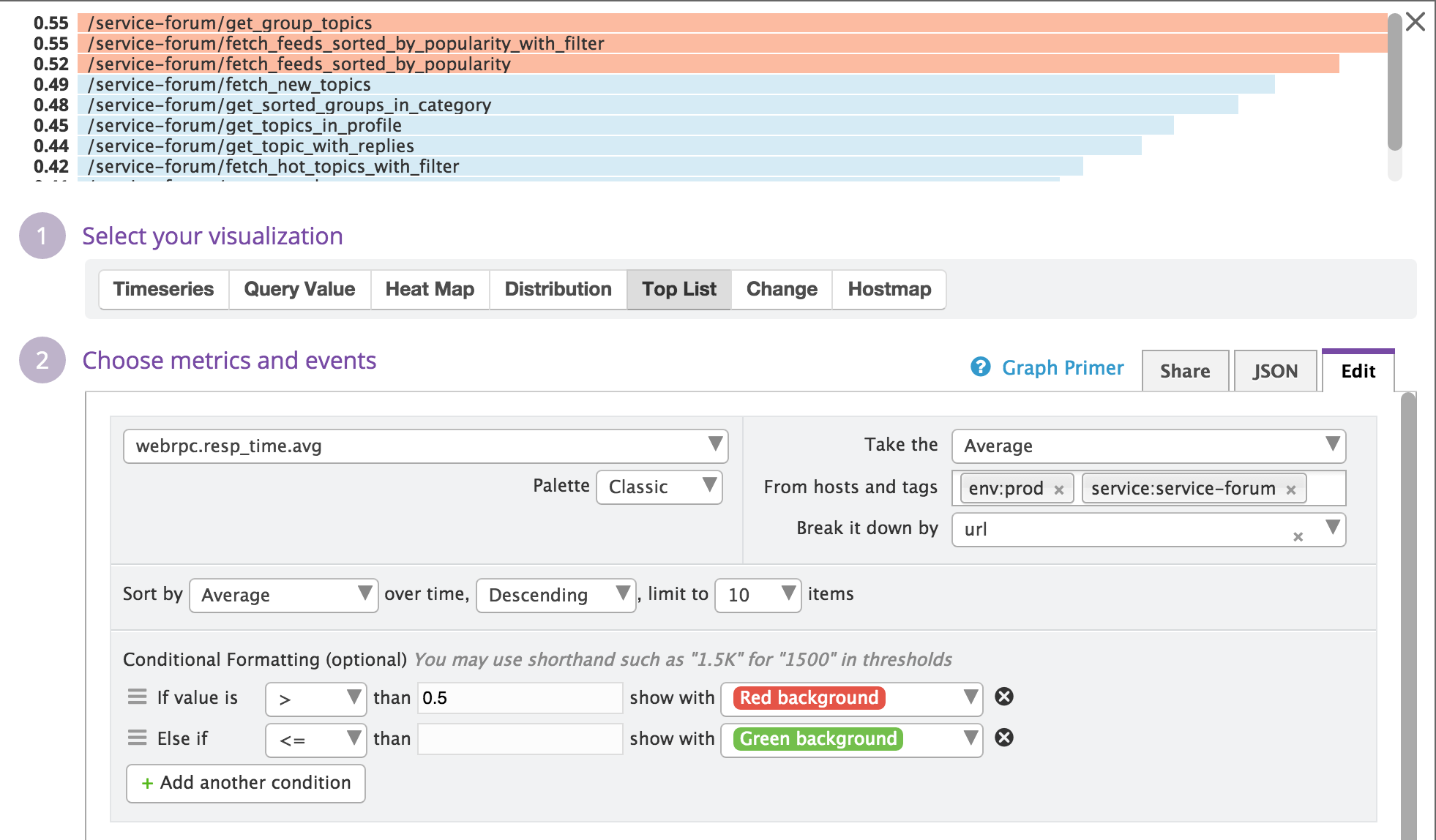
上面这例子列出了在生产环境中( env:prod ),Forum service下10个响应时间最长的API的URL。并且当响应时间超过0.5时,用红色背景显示。
图表中显示的数据也可以是若干个指标的数学运算组合。假设我们在代码中发送了应用层缓存的Cache hit与Cache miss的Count数据到Datadog,我们就可以创建一个图表来显示缓存的命中率,也就是 cache.hit / (cache.hit + cache.miss)

上图中 a 是 cache.hit , b 是 cache.miss ,然后我们把 Graph these queries as 设为 a / (a + b) 。
监控与报警
我们不可能每时每刻都关注Datadog上的Dashboard,但当某些服务无法工作或是性能指标异常时,我们希望可以立即被通知到。Datadog的监控报警可以与Slack整合。在发生异常时,Datadog可以把消息推送到Slack的一个Group里,这样所有在这个Group里的人都能在手机上收到推送通知。
Datadog的监控与报警和配置界面很直观,基本不需要什么学习成本。比如在下图中,我们创建了一个监控web server响应时间的监控,当最近5分钟内的平均响应时间超过1.0秒时报警
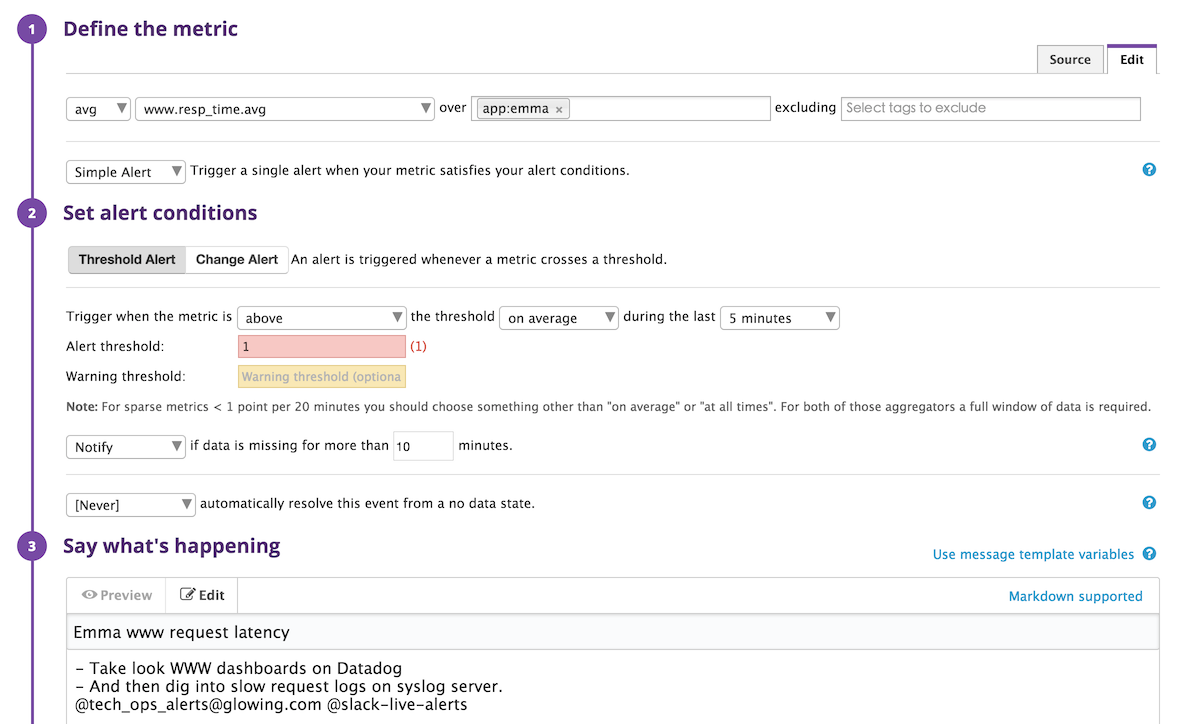
为了保证生产环境的正常运作,我们可能需要创建非常多的监控,这里有许多的重复劳动(例如,每个app都要对响应时间做监控),纯手动操作既低效又容易出错。幸运的是,Datadog可以通过它的 RESTful API 来管理监控。这样配合一些系统配置工具可以更有效地管理这些监控。下面这段Ansible代码可以为我们所有的app创建了响应时间的监控,其中 dd_monitor 是Datadog Monitor的简写,也是我们自己编写的一个Ansible的模块。
- name: Datadog monitor for web request latency dd_monitor: name: "{{ item }} web request latency" type: metric alert message: | - Take look WWW and Webrpc dashboards on Datadog - And then dig into slow request logs on syslog server. query: 'avg(last_5m):avg:www.resp_time.avg{app:{{ item }}} by {host} > 1' with_items: ['emma', 'kaylee', 'lexie', 'noah'] 小结
生产系统的性能监控并不仅仅是为了保证系统的稳定性,也是为了可以持续地改进整体的系统架构。性能调优是任何一个对技术有热情的团队都愿意做的事情。但很多时候一些技术人员虽热衷于尝试新的技术与想法,但却缺少一种“一切以数据说话”的态度。我的观点是,没有明确的量化指标,性能优化就无从谈起。也不要轻易地去拿一些网上的benchmark来说话,因为真实的生产环境复杂地多。这篇文章虽然是对Datadog这个工具的介绍,但我想传达是一种对生产环境的真实性能做全方位量化的态度。从每个API call所用的时间,到各个层级缓存的使用频率与命中率,再到数据库每张的读写频率与响应时间,这些数据都需要收集,不但要收集,更需要有效地可视化,让技术团队方便实时地分析这些数据,并基于数据来决定未来架构的发展。
扩展阅读
- Getting started with DogStatsD
- Datadog Graphing Primer
- Datadog Monitoring Reference
- Datadog API Reference
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

