自然语言处理(3)
中文分词
中文分词一直都是中文自然语言处理领域的基础研究。目前,网络上流行的很多中文分词软件都可以在付出较少的代价的同时,具备较高的正确率。而且不少中文分词软件支持Lucene扩展。但不管实现如何,目前而言的分词系统绝大多数都是基于中文词典的匹配算法。
下面分别探讨一下分词的几个经典算法:
正向最大匹配、逆向最大匹配、逐词匹配、最少切分、全切分。
最大匹配算法
最大匹配算法(Maximum Matching,以下简称MM算法) 。MM算法有两种:一种正向最大匹配,一种逆向最大匹配。
正向最大匹配的流程:
正向最大匹配算法:从左到右将待分词文本中的几个连续字符与词表匹配,如果匹配上,则切分出一个词。但这里有一个问题:要做到最大匹配,并不是第一次匹配到就可以切分的 。我们来举个例子:
待分词文本: content[]={"中","华","民","族","从","此","站","起","来","了","。"}
词表: dict[]={"中华", "中华民族" , "从此","站起来"}
1)从content[1]开始,当扫描到content[2]的时候,发现"中华"已经在词表dict[]中了。但还不能切分出来,因为我们不知道后面的词语能不能组成更长的词(最大匹配)。
2)继续扫描content[3],发现"中华民"并不是dict[]中的词。但是我们还不能确定是否前面找到的"中华"已经是最大的词了。因为"中华民"是dict[2]的前缀。
3)扫描content[4],发现"中华民族"是dict[]中的词。继续扫描下去:
4)当扫描content[5]的时候,发现"中华民族从"并不是词表中的词,也不是词的前缀。因此可以切分出前面最大的词——"中华民族"。
由此可见,最大匹配出的词必须保证下一个扫描不是词表中的词或词的前缀才可以结束。
最大匹配算法存储结构
很显然,匹配过程中是需要找词前缀的,因此我们不能将词表简单的存储为Hash结构。关于Trie树的讨论在上一个章节已经讨论过,也可以参考 Trie Tree 串集合查找 这种结构使得查找每一个词的时间复杂度为O(word.length),而且可以很方便的判断是否匹配成功或匹配到了字符串的前缀。也就是说时间复杂度完全取决于词的长度。
下图是我们建立的Trie结构词典的部分,(词语例子:"中华","中华名族","中间","感召","感召力","感受")。
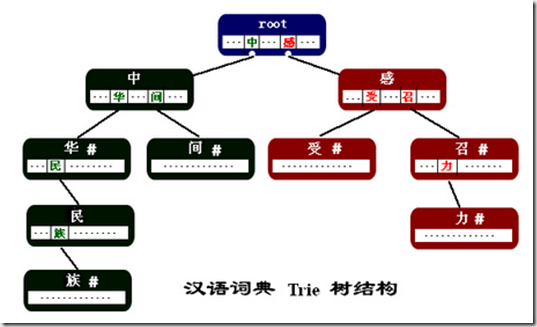
1)每个结点都是词语中的一个汉字。
2)结点中的指针指向了该汉字在某一个词中的下一个汉字。这些指针存放在以汉字为key的hash结构中。
3) 结点中的"#"表示当前结点中的汉字是从根结点到该汉字结点所组成的词的最后一个字。
在上一节已经详细讨论过,在这里不再详细描述。
最大匹配算法的优缺点
优点:分词效率高。传统的最大匹配算法需要实现确定一个切分的最大长度maxLen。如果maxLen过大,则大大影响分词效率。而且超过maxLen的词语将无法分出来。但本算法不需要设置maxLen。只要词表中有的词,不管多长,都能够切分。对非汉字的未登录词具备一定的切分能力。
缺点:暂时无词性标注功能,对中文汉字的未登录词无法识别,比如某个人名。内存占用稍大。
最少切分
使每一句中切出的词数最小。
全切分
全切分要求获得输入序列的所有可接受的切分形式,而部分切分只取得一种或几种可接受的切分形式,由于部分切分忽略了可能的其他切分形式,所以建立在部分切分基础上的分词方法不管采取何种歧义纠正策略,都可能会遗漏正确的切分,造成分词错误或失败。而建立在全切分基础上的分词方法,由于全切分取得了所有可能的切分形式,因而从根本上避免了可能切分形式的遗漏,克服了部分切分方法的缺陷。
全切分算法能取得所有可能的切分形式,它的句子覆盖率和分词覆盖率均为100%,但全切分分词并没有在文本处理中广泛地采用,原因有以下几点:
1)全切分算法只是能获得正确分词的前提,因为全切分不具有歧义检测功能,最终分词结果的正确性和完全性依赖于独立的歧义处理方法,如果评测有误,也会造成错误的结果。
2)全切分的切分结果个数随句子长度的增长呈指数增长,一方面将导致庞大的无用数据充斥于存储数据库;另一方面当句长达到一定长度后,由于切分形式过多,造成分词效率严重下降。
关于中文分词
下面的文章讲解的比较不错,可以参考下:
漫画中文分词
相信看过之后,对于中文分词及发展现状会有一个非常明晰的了解。
作者:skyme 出处: http://www.niubua.com/
联系方式:
邮箱【cloudskyme@163.com】
QQ【270800073】
本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

