记录一个sql tuning的过程
在上周 客服同事反馈,客户放映我们的数据查询很慢,页面需要十多分钟才可以刷新出来。接到客服组的反馈,和开发的同事碰了下头,找出现场环境中执行的sql。
首先,决定对SQL的执行情况入手,其中 customer_visit_log 的数据量在400w 不是很大的
通过对sql中的表进行统计信息的收集后,查看在现场数据库中的执行计划
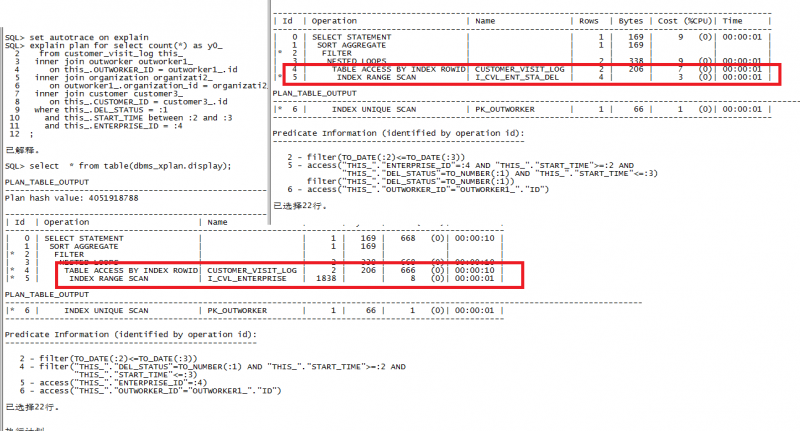
可以明确的看到,对表CUSTOMER_VISIT_LOG的访问消耗巨大,返回的rows为1838行,cpu的cost为666,表是通过索引I_CVL_ENTERPRISE返回表查询数据的。
接下来查看该索引是什么情况的?view table 可以发现 该索引只对应一个字段的b-tree索引。而这是不理想的,博客中提到的SQL对table customer_visit_log 主要通过三个地段确定数据,分别是ENTERPRISE_ID ,START_TIME,DEL_STATUS .
该SQL在执行的时候,通过上述索引I_CVL_ENTERPRISE 确定ENTERPRISE_ID的值,然后回表查询需要的START_TIME,DEL_STATUS值。就设想创建另外一个联合索引,让SQL的执行计划通过查询新建立的索引就可以获得CUSTOMER_VISIT_LOG 的值,
从而降低返回的rows值和cost消耗
点击(此处)折叠或打开 创建好新索引后,新执行计划看看是否和设想的一样结果呢?效果很理解,经过生产系统的页面测试发现,只需要3秒就可以返回业务数据了。
前后的对比图
扩展一下索引 TABLE ACCESS BY INDEX ROWID 。 表示sql在执行过程中,可以通过索引可以快速的计算出而不是全部需要的执行结果,而获得的部分执行结果通过回表查询来获得全部的值,所以TABLE ACCESS BY INDEX ROWID 对CPU的消耗大和花费的时间长。
TABLE ACCESS BY INDEX ROWID means that the Oracle kernel is going through your index and knows that not all needed information is contained in the index (columns needed are not in this index). Therefore it takes the pointer to the actual table data (rowid) and looks it up.
Popular trick to make things run faster is in this case including missing columns in the (non unique) index. It avoids one lookup in the table at the expense of larger indexes.
扩展一下索引 INDEX RANGE SCAN。 在这个SQL中有个where后面的条件中使用了范围操作符(如>、<、<>、>=、<=、between)。
索引范围扫描是一种比较常见的获取数据的方式。在索引范围扫描的,数据库只需要根据索引中的rowid就可以获得table中的数据值。所以 index range scan的效率比table access by index rowid 效率高,速度快。
首先,决定对SQL的执行情况入手,其中 customer_visit_log 的数据量在400w 不是很大的
点击(此处)折叠或打开
- select count(*) as y0_ from customer_visit_log this_
inner join outworker outworker1_ on this_.OUTWORKER_ID = outworker1_.id
inner join organization organizati2_ on outworker1_.organization_id = organizati2_.id
inner join customer customer3_ on this_.CUSTOMER_ID = customer3_.id
where this_.DEL_STATUS = :1 and this_.START_TIME between :2 and :3 and this_.ENTERPRISE_ID = :4;
点击(此处)折叠或打开
- SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Plan hash value: 4051918788
-----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 169 | 668 (0)| 00:00:10 |
| 1 | SORT AGGREGATE | | 1 | 169 | | |
|* 2 | FILTER | | | | | |
| 3 | NESTED LOOPS | | 2 | 338 | 668 (0)| 00:00:10 |
|* 4 | TABLE ACCESS BY INDEX ROWID| CUSTOMER_VISIT_LOG | 2 | 206 | 666 (0)| 00:00:10 |
|* 5 | INDEX RANGE SCAN | I_CVL_ENTERPRISE | 1838 | | 8 (0)| 00:00:01 |
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
|* 6 | INDEX UNIQUE SCAN | PK_OUTWORKER | 1 | 66 | 1 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter(TO_DATE(:2)<=TO_DATE(:3))
4 - filter("THIS_"."DEL_STATUS"=TO_NUMBER(:1) AND "THIS_"."START_TIME">=:2 AND
"THIS_"."START_TIME"<=:3)
5 - access("THIS_"."ENTERPRISE_ID"=:4)
6 - access("THIS_"."OUTWORKER_ID"="OUTWORKER1_"."ID")
已选择22行。
执行计划
----------------------------------------------------------
Plan hash value: 3013799171
---------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 16360 | 32720 | 39 (0)| 00:00:01 |
| 1 | COLLECTION ITERATOR PICKLER FETCH| DISPLAY | 16360 | 32720 | 39 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------
接下来查看该索引是什么情况的?view table 可以发现 该索引只对应一个字段的b-tree索引。而这是不理想的,博客中提到的SQL对table customer_visit_log 主要通过三个地段确定数据,分别是ENTERPRISE_ID ,START_TIME,DEL_STATUS .
点击(此处)折叠或打开
- create index I_CVL_ENTERPRISE on CUSTOMER_VISIT_LOG (ENTERPRISE_ID)
从而降低返回的rows值和cost消耗
点击(此处)折叠或打开
- create index i_cvl_ent_sta_del on customer_visit_log(enterprise_id,start_time,del_status);
点击(此处)折叠或打开
- SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Plan hash value: 2328037851
-----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 169 | 9 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 169 | | |
|* 2 | FILTER | | | | | |
| 3 | NESTED LOOPS | | 2 | 338 | 9 (0)| 00:00:01 |
| 4 | TABLE ACCESS BY INDEX ROWID| CUSTOMER_VISIT_LOG | 2 | 206 | 7 (0)| 00:00:01 |
|* 5 | INDEX RANGE SCAN | I_CVL_ENT_STA_DEL | 4 | | 3 (0)| 00:00:01 |
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
|* 6 | INDEX UNIQUE SCAN | PK_OUTWORKER | 1 | 66 | 1 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter(TO_DATE(:2)<=TO_DATE(:3))
5 - access("THIS_"."ENTERPRISE_ID"=:4 AND "THIS_"."START_TIME">=:2 AND
"THIS_"."DEL_STATUS"=TO_NUMBER(:1) AND "THIS_"."START_TIME"<=:3)
filter("THIS_"."DEL_STATUS"=TO_NUMBER(:1))
6 - access("THIS_"."OUTWORKER_ID"="OUTWORKER1_"."ID")
已选择22行。
执行计划
----------------------------------------------------------
Plan hash value: 3013799171
---------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 16360 | 32720 | 39 (0)| 00:00:01 |
| 1 | COLLECTION ITERATOR PICKLER FETCH| DISPLAY | 16360 | 32720 | 39 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------
扩展一下索引 TABLE ACCESS BY INDEX ROWID 。 表示sql在执行过程中,可以通过索引可以快速的计算出而不是全部需要的执行结果,而获得的部分执行结果通过回表查询来获得全部的值,所以TABLE ACCESS BY INDEX ROWID 对CPU的消耗大和花费的时间长。
TABLE ACCESS BY INDEX ROWID means that the Oracle kernel is going through your index and knows that not all needed information is contained in the index (columns needed are not in this index). Therefore it takes the pointer to the actual table data (rowid) and looks it up.
Popular trick to make things run faster is in this case including missing columns in the (non unique) index. It avoids one lookup in the table at the expense of larger indexes.
扩展一下索引 INDEX RANGE SCAN。 在这个SQL中有个where后面的条件中使用了范围操作符(如>、<、<>、>=、<=、between)。
索引范围扫描是一种比较常见的获取数据的方式。在索引范围扫描的,数据库只需要根据索引中的rowid就可以获得table中的数据值。所以 index range scan的效率比table access by index rowid 效率高,速度快。
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

