Spark新年福音:一个用于大规模数据科学的API——DataFrame
文章翻译自 Introducing DataFrames in Spark for Large Scale Data Science ,作者Reynold Xin(辛湜,@hashjoin),Michael Armbrust,Davies Liu。
以下为译文
今天,我们正式宣布Spark新的 API —— DataFrame 。作为2014–2015年Spark最大的API改动,DataFrame能够使得大数据更为简单,从而拥有更广泛的受众群体。
我们最早在设计Spark的时候,其中一个很重要的目标就是给大数据生态圈提供基于通用编程语言的(Java、Scala、Python)简单易 用 的API。Spark原本的RDD API通过函数式编程的模式把分布式数据处理转换成分布式数据集(distributed collections)。原本需要上千行用Hadoop MapReduce实现的代码,在Spark这个API上减少到了数十行。
然后随着Spark的不断壮大,我们希望拥有更广泛的受众群体利用其进行分布式处理,不局限于“大数据”工程师。这个新的DataFrame API在R和Python data frame的设计灵感之上,专门为了数据科学应用设计,具有以下功能特性:
- 从KB到PB 级 的数据量支持 ;
- 多种数据格式和多种存储系统支持 ;
- 通过Spark SQL的Catalyst优化器进行先进的优化,生成代码 ;
- 通过Spark无缝集成所有大数据工具与基础设施 ;
- 为Python、Java、Scala和R语言(SparkR)API。
对于之前熟悉其他语言中data frames的新用户来说,这个新的API可以让Spark的初体验变得更加友好。而对于那些已经在使用的用户来说,这个API会让基于Spark的编程更加容易,同时其智能优化和代码生成也 能 帮助用户获得更好的性能。
初识DataFrames
在Spark中,DataFrame是一个 以命名列 方式 组织的分布式数据集 ,等同于关系型数据库中的一个表,也相当于R/Python中的data frames(但是进行了更多的优化)。DataFrames可以由结构化数据文件转换而来, 也 可以从Hive中的表得来, 以及 可以转换自外部数据库或现有的RDD。
下面代码演示了如何使用Python构造DataFrames,而在Scala和Java中也有类似的API可以调用。
# Constructs a DataFrame from the users table in Hive. users = context.table("users") # from JSON files in S3 logs = context.load("s3n://path/to/data.json", "json") 一经构建,DataFrames就会为分布式数据处理提供一个指定的DSL(domain-specific language )。
# Create a new DataFrame that contains “young users” only young = users.filter(users.age < 21) # Alternatively, using Pandas-like syntax young = users[users.age < 21] # Increment everybody’s age by 1 young.select(young.name, young.age + 1) # Count the number of young users by gender young.groupBy("gender").count() # Join young users with another DataFrame called logs young.join(logs, logs.userId == users.userId, "left_outer") 通过Spark SQL,你还可以用SQL的方式操作DataFrames。下面这个例子统计了“young” DataFrame中的用户数量。
young.registerTempTable("young") context.sql("SELECT count(*) FROM young") 在Python中,Pandas DataFrame和Spark DataFrame还可以自由转换。
# Convert Spark DataFrame to Pandas pandas_df = young.toPandas() # Create a Spark DataFrame from Pandas spark_df = context.createDataFrame(pandas_df)
类似于RDD,DataFrame同样使用了lazy的方式。也就是说,只有动作真正发生时(如显示结果,保存输出),计算才会进行。从而,通过一些技术,比如predicate push-downs和bytecode generation,执行过程可以进行适当的优化(详情见下文)。同时,所有的DataFrames也会自动的在集群上并行和分布执行。
数据格式和来源
现代的应用程序通常需要收集和分析来自各种不同数据源的数据,而DataFrame与生俱来就支持读取最流行的格式,包括JSON文件、Parquet文件和Hive表格。DataFrame还支持从多种类型的文件系统中读取,比如本地文件系统、分布式文件系统(HDFS)以及云存储(S3)。同时,配合JDBC,它还可以读取外部关系型数据库系统。此外,通过Spark SQL的 外部数据源 (external data sources) API,DataFrames可以更广泛地支持任何第三方数据格式和数据源。值得一提的是,当下的第三方扩展已经包含Avro、CSV、ElasticSearch和Cassandra。

DataFrames对数据源的支持能力允许应用程序可以轻松地组合来自不同数据源的数据。下面的代码片段则展示了存储在S3上网站的一个文本流量日志(textual traffic log)与一个PostgreSQL数据库的join操作,目的是计算网站用户访问该网站的次数。
users = context.jdbc("jdbc:postgresql:production", "users") logs = context.load("/path/to/traffic.log") logs.join(users, logs.userId == users.userId, "left_outer") / .groupBy("userId").agg({"*": "count"}) 高级分析和机器学习
当下,数据科学家们使用的技术已日益复杂,超越了joins和aggregations。为了更好地支持他们的使用,DateFrames可以直接在MLlib的 machine learning pipeline API 中使用。此外,在DataFrames中,程序还可以运行任意复杂的用户函数。
通过Spark,用户可以使用MLlib中新的pipelineAPI来指定高级分析任务。例如,下面的代码创建了一个简单的文本分类(text classification)管道。该管道由一个tokenizer,一个hashing term frequency feature extractor和logistic regression组成。
tokenizer = Tokenizer(inputCol="text", outputCol="words") hashingTF = HashingTF(inputCol="words", outputCol="features") lr = LogisticRegression(maxIter=10, regParam=0.01) pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])
一旦管道设置好,我们可以直接使用它在DataFrame上进行训练。
df = context.load("/path/to/data") model = pipeline.fit(df) 对于那些复杂程度超出了machine learning pipeline API能力的任务,应用程序也可以通过DataFrames提供任意复杂的函数,当然这也可以通过Spark已有的RDD API来实现。下面代码段实现的是一个DataFrame“bio”列上的word count(大数据时代的Hello World)。
df = context.load("/path/to/people.json") # RDD-style methods such as map, flatMap are available on DataFrames # Split the bio text into multiple words. words = df.select("bio").flatMap(lambda row: row.bio.split(" ")) # Create a new DataFrame to count the number of words words_df = words.map(lambda w: Row(word=w, cnt=1)).toDF() word_counts = words_df.groupBy("word").sum() 智能优化和代码生成
与R/Python中data frame使用的eager方式不同,Spark中的DataFrames执行会被查询优化器自动优化。在DataFrame上的计算开始之前, Catalyst优化器 会编译操作,这将把DataFrame构建成物理计划来执行。因为优化器清楚操作的语义和数据的结构,所以它可以为计算加速制定智能的决策。
在高等级上,这里存在两种类型的优化。首先,Catalyst提供了逻辑优化,比如谓词下推(predicate pushdown)。优化器可以将谓词过滤下推到数据源,从而使物理执行跳过无关数据。在使用Parquet的情况下,更可能存在文件被整块跳过的情况,同时系统还通过字典编码把字符串对比转换为开销更小的整数对比。在关系型数据库中,谓词则被下推到外部数据库用以减少数据传输。
第二,为了更好地执行,Catalyst将操作编译为物理计划,并生成 JVM bytecode ,这些通常会比人工编码更加优化。例如,它可以智能地选择broadcast joins和shuffle joins来减少网络传输。其次,同样存在一些较为低级的优化,如消除代价昂贵的对象分配及减少虚拟函数调用。因此,我们认为现有的Spark项目迁移到DataFrames后,性能会有所改观。
同时,鉴于优化器为执行生成了JVM bytecode,Python用户将拥有与Scala和Java用户一样的高性能体验。
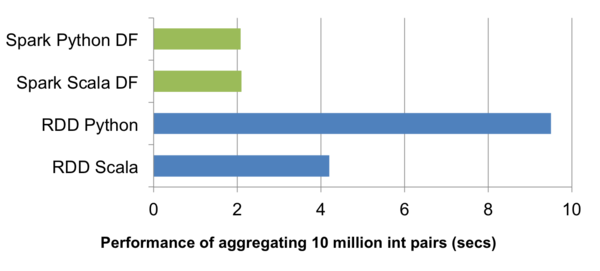
上图是在 单个机器 上对1000万个整数进行分组聚合(group-by-aggregation)的运行时性能对比。在绿色部分,为了更好地执行,Scala和Python的DataFrame操作都被编译成了JVM bytecode,导致这两种语言在性能上基本有着同样的表现。同时,两者性能均优于普通Python RDD实现的4倍,也达到了Scala RDD实现的两倍。
不管选择了哪种语言,Catalyst优化器都实现了DataFrame程序的优化执行。同时,随着Catalyst优化器的不断改善,引擎也会变得更智能,从而对比已有版本,Spark的每一个新版本都会有性能上的提升。
在Databricks,数据科学家团队已经将DataFrame API搭载在内部的数据管道上。Spark程序性能的改进已经在我们内部得到证实,而程序也更加的简洁易懂。毫无疑问,这将大幅度 地 降低大数据使用门槛,让大数据技术为更多人使用。
这个API将在3月初作为Spark1.3版本的一部分发布。如果你迫不及待,可以关注Spark在 GitHub 上的进展。如果你在加州湾区参加 Strata conference ,2月17日圣何塞有一个关于这个主题的 M eetup。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

