支持redis节点高可用的twemproxy
原生twemporxy
twemproxy支持一个proxy实例同时代理多个分布式集群(server pools),每个集群使用不同的网络端口实现数据流的隔离,下图中port1应用于cluster1代理,port2应用于cluster2代理:

今天要介绍的是twemproxy对redis节点高可用的支持,拿上图的其中一个分布式集群进行示例,逻辑结构如下:
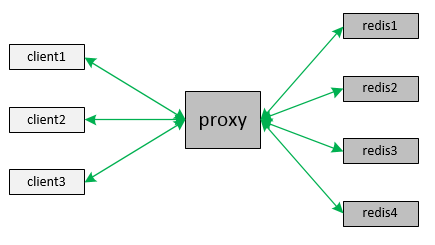
客户端client流入的请求,在proxy上进行路由分片,然后转发到后端的redis节点上存储或者读取。事实上,大家已经注意到后端的redis节点只有一个点,在出现异常情况下,是很容易掉线的。按twemproxy的设计,它可以自动识别失效节点并将其剔除,同时落在原来节点上的请求会分摊到其余的节点上。这是分布式缓存系统的一种通用做法,但需要忍受这个失效节点上的数据丢失,这种情况是否可以接受?
在业内,redis虽然被定位为缓存系统,但事实上,无论哪种业务场景(我们接触过的)都不愿意接受节点掉线带来的数据丢失,因为那样对他们系统的影响实在太大了,更有甚者在压力大的时候引起后端数据库被击穿的风险。所以,我们打算改造twemproxy,前后总共有几个版本,下面分享给各位的是我们目前线上在跑的版本。
定制化改造
在上图的基础上,我们增加了与manager交互的模块、增加了与sentinel(redis-sentinel)交互的模块,修改了redis连接管理模块,图中三个红色虚线框所示:
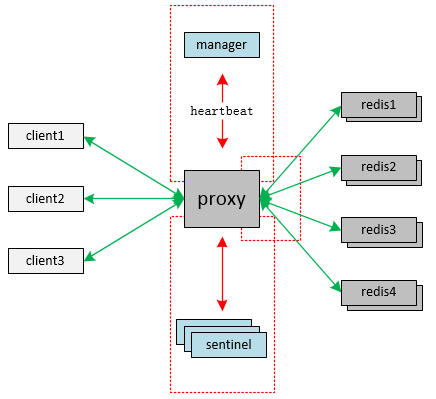
manager交互模块
增加连接manager的客户端交互模块,用于发送心跳消息,从心跳应答包里获取group名称列表和sentinel列表(IP/PORT信息),即整个分布式集群的配置信息,其中心跳消息带有版本信息,发送间隔可配置。
sentinel交互模块
增加与sentinel客户端交互模块(IP/PORT信息来自于manager),发送group名称给sentinel获取redis主节点的IP/PORT信息,一个group对应一个主节点。取到所有主节点后,订阅主从切换频道,获取切换消息用于触发proxy和主节点间的连接切换。这里需要解析sentinel的响应消息,会比较繁琐一些。当proxy开始与sentinel节点的交互过程,需要启动定时器,用以控制交互结果,当定时器超时交互未结束(或者proxy未正常工作),proxy将主动切换到下一个sentinel节点,并启动新的交互过程。考虑到proxy与sentinel之间网络连接的重要性(连接假死,proxy收不到主从切换消息,不能正常切换),增加了定时心跳机制,确保这条TCP链路的可用性。
redis连接管理模块
原先redis节点的IP/PORT信息来自于静态配置文件,是固定的,而改造以后这些信息是从sentinel节点获取。为了确保获取到的IP/PORT信息的准确性,需要向IP/PORT对应的节点验证是否是主节点的逻辑,只有返回确认是主节点,才认为是合法的。整个过程,按官方指导实现,不存在漏洞。
详细消息流
为了清晰的描述proxy的内部处理逻辑,制作了如下消息流图:
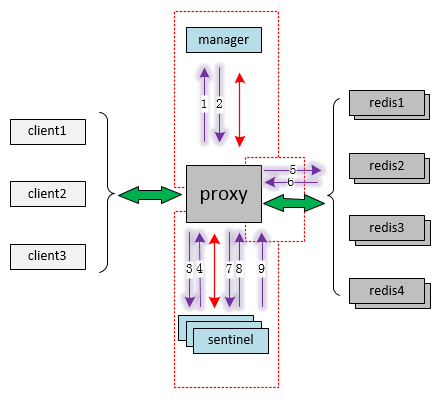
绿色 为业务通道,用于透传业务层数据;
紫色 为命令通道(红线的细化),用于初始化和节点主从切换:
- 箭头1:manager heartbeat req;
- 箭头2:manager heartbeat rsp;
- 箭头3:sentinel get-master-addr-by-name req;
- 箭头4:sentinel get-master-addr-by-name rsp;
- 箭头5:redis auth & role req;
- 箭头6:redis auth & role rsp;
- 箭头7:sentinel psubscribe +switch-master req;
- 箭头8:sentinel psubscribe +switch-master rsp;
- 箭头9:sentinel pmessage;
- 命令通道命令顺序按数字1-8进行,7/8是proxy与sentinel的心跳消息,9是主从切换消息;
高可用影响面分析
- 在sentinel节点切换的过程中,存在proxy正在对外提供业务服务的状态,这时候正在处理的数据将继续处理,不会受到影响,而新接入的客户端连接将会被拒绝,已有的客户端连接上的新的业务请求数据也会被拒绝。sentinel节点切换,对系统的影响是毫秒级别,前面的设计对业务系统来讲会显得比较友好、不那么粗鲁;
- 而redis节点的主从切换对系统的影响,主要集中在proxy发现主节点异常到sentinel集群做出主从切换这个过程,这段时间内落在该节点上的业务都将失败,而该时间段的长度主要依赖在sentinel节点上的down-after-milliseconds配置字段;
经验总结
- 作为代理中间件,支持pipeline的能力有限,容易产生消息积压,导致客户端大量超时,所以慎用pipeline功能;
- 高负荷下容易吃内存,struct msg和struct mbuf对象会被大量缓存在进程内(内存池化);
- zero copy,对于多个连续请求(TCP粘包)进行拆分,拷贝是无法避免的,但是有优化空间;
问卷调查
如果我们精简下程序,删除manager交互模块,group列表和sentinel列表来自静态配置文件,然后开源出来,大家有兴趣么? 有的话请留言哦^_^
上两篇博文:
redis-migration:独创的redis在线数据迁移工具
网易私有云Redis服务
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

