DHT爬虫:18.4GB种子分析小记
0×00 前言
曾经有种子帝说过:如果你有一个无聊的想法,那么就在无聊的时候去实现它吧。
起初是想拿网上流传海盗湾那批种子作分析,后来想来点“新鲜的”看看周末大家都在下些啥;开始只是单纯的想抓点信息,发现announce_peer请求过来的name并不全,又开始整下载种子,后来干脆把种子信息导进数据库(基本可以做一个简单的BT搜索了)。
因为具有时效性,3天收集的信息并不完全具有代表性。
0×01 相关术语
1.1 P2P网络
对等计算(Peer to Peer,简称p2p)可以简单的定义成通过直接交换来共享计算机资源和服务,而对等计算模型应用层形成的网络通常称为对等网络。相信大家都用过迅雷,就不多说了。
1.2 DHT网络
DHT(Distributed Hash Table,分布式哈希表),DHT由节点组成,它存储peer的位置,是一种分布式存储方法。在不需要服务器的情况下,每个客户端负责一个小范围的路由,并负责存储一小部分数据,从而实现整个DHT网络的寻址和存储,其中BT客户端包含一个DHT节点,用来联系DHT中其他节点,从而得到peer的位置,进而通过BitTorrent协议下载。
简单来说DHT就是负责管理提供信息和服务节点的管理与路由功能,两个需要区分的概念:
“peer” 是在一个 TCP 端口上监听的客户端/服务器,它实现了 BitTorrent 协议。
“节点” 是在一个 UDP 端口上监听的客户端/服务器,它实现了 DHT(分布式哈希表) 协议。
1.3 Kademlia算法
Kademlia是DHT网络的一种实现。在Kademlia网络中,距离是通过异或(XOR)计算的,结果为无符号整数。distance(A, B) = |A xor B|,值越小表示越近。
1.4 KRPC协议
KRPC 是节点之间的交互协议,是由 bencode 编码组成的一个简单的 RPC 结构,他使用 UDP 报文发送。一个独立的请求包被发出去然后一个独立的包被回复。这个协议没有重发。它包含 3 种消息:请求,回复和错误。对DHT协议而言,这里有 4 种请求:
ping 检查一个节点是否有效
find_node 向一个节点发送查找节点的请求,在初始路由表或验证桶是否存活时使用
get_peers 向一个节点发送查找资源的请求
announce_peer 向一个节点发送自己已经开始下载某个资源的通知
一条KRPC消息由一个独立的字典组成,其中 t 和 y 关键字是每条信息都包含的
1.5 MagNet协议
MagNet协议,也就是磁力链接。是一个通过sha1算法生成一个20字节长的字符串,P2P客户端使用磁力链接,下载资源的种子文件,然后根据种子文件下载资源。
因已有现成的脚本实现,只需要对相关协议有个大概了解就可以动手了。
0×02 DHT爬虫
2.1 实现原理
伪装成DHT节点加入DHT网络中收集信息,DHT中node(加入网络的时候随机生成)与infohash都是使用160bit的表示方式,也就是40位的16进制,意味着数量级有2^160,爬虫主要收集 get_peer 、 announce_peer 这两个请求的信息
2.2 get_peer
get_peers 与torrent文件的infohash有关,找到待查资源是否有 peer 。这时KPRC中的 q=get_peers ,其中包含节点 id 和 info_hash 两个参数,如果被请求的节点有对应info_hash的 peers ,将返回一个关键字 values ,如果无则返回关键字 nodes ,同时也返回一个 token , token 在 annouce_peer 中需要携带。
参数:
{"id" : "<querying nodes id>", "info_hash" : "<20-byte infohash of target torrent>"}
回复:
{"id" : "<queried nodes id>", "token" :"<opaque write token>", "values" : ["<peer 1 info string>", "<peer 2 info string>"]}
或者
{"id" : "<queried nodes id>", "token" :"<opaque write token>", "nodes" : "<compact node info>"}
这里过来的info_hash不一定是有真实存在的
2.3 announce_peer
这个请求用来表明发出 announce_peer 请求的节点,正在某个端口下载torrent文件。包含四个参数 请求节点id 、 info_hash 、 整型端口port 和 tonken ,收到请求的节点检查这个 token ,如果相同,则返回节点的 IP 和 port 等联系信息。爬虫中不能直接用 announce_peer ,否则很容易从上下文中判断是通报虚假资源而被禁掉。
参数:
{"id" : "<querying nodes id>", "implied_port": <0 or 1>, "info_hash" : "<20-byte infohash of target torrent>", "port" : <port number>, "token" : "<opaque token>"}
回复:
{"id" : "<queried nodes id>"}
这里过来的info_hash表明已经有在下载了,大部分是存在的,这里主要收集这个请求的信息 info_hash 、 ip 、 port 、 name (name不一定有)
ping 和 find_node 和报文案例看一下官方文档或文章后的参考翻译文章,文档已经写得很详细了;了解了这两个请求,基本解决信息收集的问题了。
2.4 Python实现
现在网络上出现的有:
dhtfck
simDHT
DHTCrawler
DHT-woodworm
……
以上是基于Python 2.x版本的,其中DHTCrawler是基于libtorrent库实现,因为短时间内需要收集大量种子,我的做法是先收集大量info_hash,然后直接从种子库下载,这里要用到一个基于异步(Python 3.5)的DHT爬虫 Maga
Maga - A DHT crawler framework using asyncio.可以使用以下方法安装
pip3 install maga
如果使用git下载,源码里面的bencoder库需要修改一下,比如改成bcoding,使用
from maga import Maga
import logging
logging.basicConfig(level=logging.INFO)
class Crawler(Maga):
async def handler(self, infohash):
logging.info(infohash)
crawler = Crawler()
crawler.run(6881)
传过来的info_hash是 get_peers 和 announce_peer 的,收集 announce_peer 的需要修改源码过滤一下区分
注:这里需要公网IP(能让其他DHT节点访问到本地监听的端口就行)
2.5 数据存储
数据库使用MySQL,连接使用aiomysql( 文档 ),考虑到数据表多,按hash首字母分16张表存储内容,类似如下
announce_peer_0
announce_peer_1
......
announce_peer_e
announce_peer_f
2.6 收集结果
丢在阿里云ECS(1核、1G、100M/s)上跑了66小时(一个周末),收集信息如下
get_peers 请求的info_hash 21,313,390 条记录(不重复)
announce_peer 请求的info_hash 849,355 条记录(不重复)
get_peers 和 announce_peer 请求的info_hash 76,411,582 条记录(含重复)
数量少有可能是脚本没写好造成的,也可能被某些DHT节点pass掉了
0×03 magnet & torrent
有了种子的HASH还得将其“转成”种子才行,大致有两种形式,使用协议收集和直接到目前网上公开的缓存种子库下载
3.1 magnet转torrent
协议实现
可以使用libtorrent库实现,libtorrent库是p2p下载的客户端库,有丰富的接口,具体可以参考 DHTCrawler 或 Magnet2Torrent
种子库下载
也就是写web爬虫下载现成的种子,多线程或使用异步,这个看个人爱好整
写了个脚本去抓 http://bt.box.n0808.com 上的缓存种子,为了提高效率,仅使用 announce_peer 中的info_hash( 849,355 ),得到 509,146 个种子,大小 19,327,952 ( 18.4GB )
使用异步,爬去的时候不免会出现连接断掉的情况,16张表为了保持100%地处理所有信息,使用一个列表和一个循环,每当一个表已处理完就移除,直到空退出循环,采集过程中看网络资源调整同时处理任务的数量max_tasks
table = list('0123456789abcdef') while len(table)>0: for t in table: sql = 'select distinct info_hash from announce_peer_{} where status=0;'.format(t) hash_list = await self.find(sql) if len(hash_list)>0: await asyncio.wait([self.hash_queue.put(i[0].upper()) for i in hash_list]) tasks = [asyncio.ensure_future(self.fetch_worker()) for _ in range(self.max_tasks)] await self.hash_queue.join() for task in tasks: task.cancel() else: table.remove(t)
由于大量的请求,爬去过程中有可能会出现僵尸连接,一直连着又不下载,使用超时把它扔掉,下一次循环再进行抓取;在获取结果的过程中只认200、403、404这几种状态,直接扔掉,下一次循环再进行抓取
try: with aiohttp.Timeout(300): async with aiohttp.get(url) as response: try: assert response.status == 200 print('[+][{}]{}'.format(response.status, response.url)) return await response.read() except: if response.status==404: await self.update(info_hash, 2) elif response.status==403: await self.update(info_hash, 3) print('[-][{}]{}'.format(response.status, response.url)) except: print('[!][000]{}'.format(url))
保存种子,直接写入返回的数据就可以了
with open('./torrent/{}.torrent'.format(info_hash), 'wb') as f: f.write(torrent)
协议解析收集相对比较慢,种子库下载比较有局限性
3.2 torrent解析
使用libtorrent库,安装
apt -y install python3-libtorrent
直接传入种子,可以解析得到种子名称、哈希值、包含的文件及大小等信息
import libtorrent as lt
info = lt.torrent_info('test.torrent')
name = info.name() # 种子名称
info_hash = str(info.info_hash()) # 种子hash值
num_files = info.num_files() # 种子包含的文件数量
total_size = info.total_size() # 种子大小
除以上之外,还可以获取种子的 注释 、 trackers 等信息
获取种子下的文件列表信息,path是相对种子的路径,size是该文件的大小(单位比特)
for i in info.files(): print(i.path.strip(),i.size)
获取种子文件中的tracker信息,有些会含有诡异的字符无法正常获取,加个try忽略
for i in info.trackers(): try: url = print(i.url.strip()) except: continue
为了方便分离和防止中断,脚本直接列出torrent目录下的所有种子文件放入集合,数据库抽出所有已解析的种子HASH放入集合,每次启动取两集合的差
torr_set = set([t for t in os.listdir(TORRENT_DIR) if t.endswith('.torrent')]) task_list = list(torr_set - hash_set) # hash_set 为数据库取出已经解析的种子名称集合
3.3 数据存储
种子信息一张表,文件列表按HASH首字母分16张表,trackers一张(刚开始以为一个种子也就3~5条不会很多一张表够用,后来发现有将近400W -_-!)
torrent_info
torrent_trackers
torrent_files_0
torrent_files_1
......
torrent_files_e
torrent_files_f
然后用脚本解析种子把信息导进数据库,最后发现其中有75个名称与hash不对应,7个无效种子
0×04 内容分析
说了那么多,是时候看看有多少葫芦娃大战钢铁侠了,以下图表使用D3.js生成。
4.1 总容量
全部种子总容量:1.20PB,解析处理的大小单位是直接,直接求和转换单位即可
select concat(round(sum(total_size)/1024/1024/1024/1024/1024,2),"PB") as "total_size" from torrent_info;

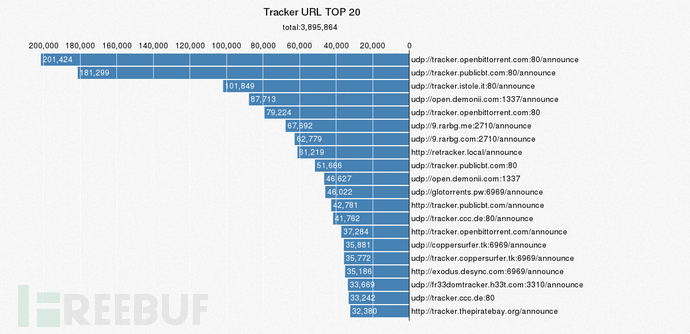
4.2 Tracker URL TOP 20
Tracker服务器主要是收集下载者的信息,并将此信息提供给其他下载者,使下载者们相互连接起来,传输数据。
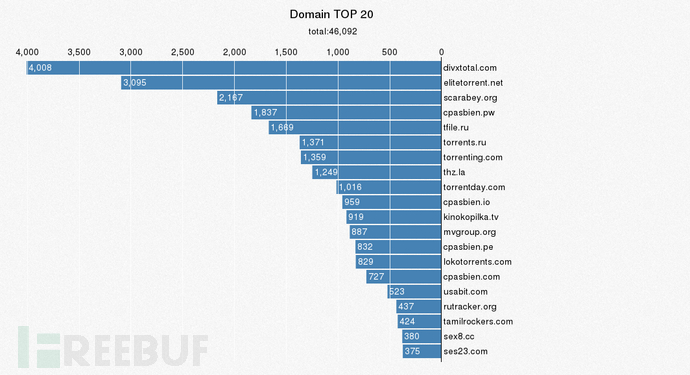
4.3 种子名称中域名 TOP 20
xxx.mp4与xxx.com都符合同样的规则,下载顶级域名后缀进行正则匹配,mysql的正则不好使,用python匹配以域名为key用字典保存,然后用sorted()排序
sorted(domain.items(),key=lambda d:d[1],reverse=True)[:20]
4.4 种子包含文件扩展名与数量关系
libtorrent没有现成的扩展名属性,主要通过.来取最后几个字符串保存到数据库,直接sql分组统计

4.5 种子包含文件个数与数量关系
种子有单文件种子和多文件种子之分,数量多的大部分是歌曲等信息

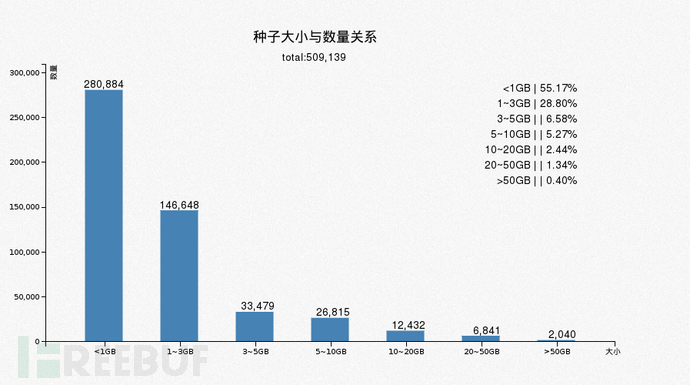
4.6 种子大小与数量关系
单个种子的大小,小于1GB的大多数是视频
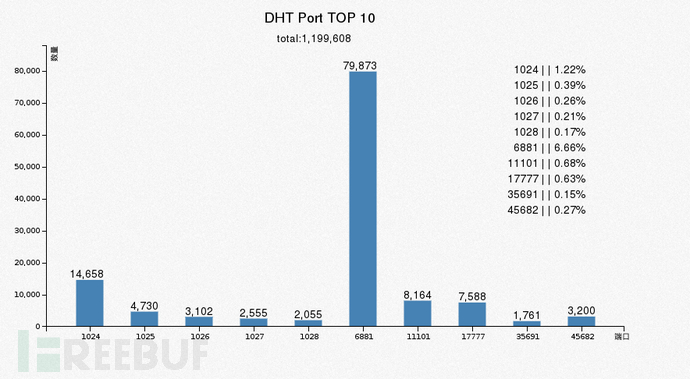
4.7 DHT端口 TOP 10
announce_peer 过来的端口,基本都是随机的,分析这个没啥意
4.8 DHT节点分布图
announce_peer 过来的IP,都是相邻的多,分析意义也不大,只是想看看大致分布,ip地址信息调用 http://ip.taobao.com/service/getIpInfo.php?ip=1.1.1.1 接口,注意保存返回中的country_id这个参数,使用的是ISO 3166-1 Alpha-2的国家编码,有时候生成图表要用ISO 3166-1 Alpha-3的时候方便转换

4.9 名称中关键词 TOP 500
最后,来点毁三观的,据说一眼能定位某词的都是大神。。。。
将所有种子名称导出到一个文本文件,使用“结巴”中文分词(安装 pip3 install jieba )提取统计,直接调用官方demo脚本extract_tags_with_weight.py即可,-k是输出数量,9999999+是为了输出全部,-w是计算权重,然后直接用shell过滤掉非中文字符
python3 extract_tags_with_weight.py -k 9999999999 -w 1 torrent_name.txt | awk '{print $2}' | LANG=C grep -v '^[[:graph:]]*$' | head -n 500 | xargs

很多名字被拆分了,载入定制字典(比如演员名单等)效果可能好点, jieba 分词还支持TextRank算法抽词等功能,了解更多请移步项目Github: https://github.com/fxsjy/jieba/tree/jieba3k
可视化展示效果

正文到此结束
- 本文标签: js cat 时间 Select src python update tab https 文案 GitHub DOM lib 关键词 目录 源码 git 线程 多线程 解析 dist http 云 定制 awk 数据库 管理 HTML 参数 公网IP mysql 翻译 grep 数据 域名 阿里云 ECS queue 协议 ip find UI UDP list ask Logging 服务器 shell tar 安装 TCP value 统计 下载 PHP node sql 注释 key 中文分词 文章 web 端口
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

