【MySQL】最容易忽略的常识
起因
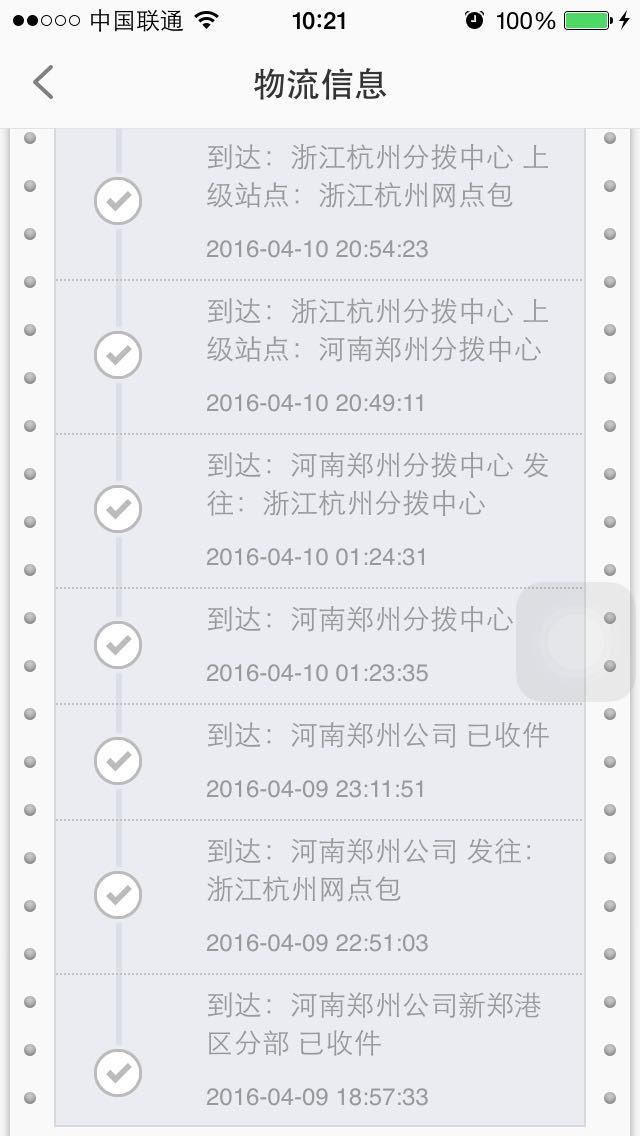
开发反馈一个表的数据大小已经130G,对物理存储空间有影响,且不容易做数据库ddl变更。咨询了开发相关业务逻辑,在电商业务系统中,每笔订单成交之后会有一条对应的订单物流信息,因此需要设计一个物流相关的表用来存储该订单的物流节点信息,该表使用text字段存储物流信息。
大致的表结构:
CREATE TABLE `goods_order_express` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`express_id` int(10) unsigned NOT NULL,
`message` varchar(200) NOT NULL,
`status` varchar(20) NOT NULL,
`state` tinyint(3) unsigned NOT NULL,
`data` text NOT NULL,
`created_time` int(10) unsigned NOT NULL,
PRIMARY KEY (`id`),
KEY `idx_expid` (`express_id`)
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8mb4;
业务分析
当快递每到达一个中转站或者发生揽件,接收等事件,快递公司的api都会生成如下格式的信息(去掉业务相关敏感数据)
[{"time":"2016-03-16 11:16:20","ftime":"2016-03-16 11:16:20","context":"四川省成都市TD客户一公司 已发出,下一站成都转运中心","areaCode":"","areaName":"","status":"在途"},{"time":"2016-03-16 11:11:03","ftime":"2016-03-16 11:11:03","context":"四川省成都市TD客户一公司 已打包","areaCode":"","areaName":"","status":"在途"},{"time":"2016-03-16 11:08:09","ftime":"2016-03-16 11:08:09","context":"四川省成都市TD客户一公司 已揽收","areaCode":"","areaName":"","status":"收件"}]
该json 串 411个字符,开发业务程序去定期轮训调用相关api信息,并把上面的json串数据 insert 或者update 到goods_order_express的data字段。而且该表从开始到现在从未删除,积累了初始到现在的所有数据。随着公司业务爆发式增长,该表未来会更大,而且增长速度会更快。数据库服务器的磁盘空间面临不足,表结构变更难以操作。
如何优化?
1 能否减小数据量写入?
和业务分析,我们不能丢弃新增的数据。但是每一笔物流信息实际上是有生命周期的,从发货到收件完成即可完成其生命周期,也就是该数据可以不再展示了,我们基本不会查看一个已经收到货的物流信息。因此可以针对历史数据进行归档,比如将90天之前的数据备份到hbase中并且从MySQL 数据库中删除,从而维持该表的大小在一个合理的范围。
2 减少data 字段数据大小
a 缩小json串数据,保留有效数据
time 和ftime 是一样的,和开发确认ftime无功能使用,在我们的物流展示系统中 areaCode areaName也没有逻辑意义。
故对json数据做如下精简
[{"time":"2016-03-16 11:16:20","context":"四川省成都市TD客户一公司 已发出,下一站 成都转运中心","status":"在途"},{"time":"2016-03-16 11:11:03","context":"四川省成都市TD客户一公司 已打包","status":"在途"},{"time":"2016-03-16 11:08:09","context":"四川省成都市TD客户一公司 已揽收","status":"收件"}]
精简之后占用的字符数由411个减小为237个,减少47%的数据。
b 评估物流节点数
相信大家都有网购的经验 ,一般情况下快递大约含有15-20个节点信息
{"time":"2016-03-16 11:16:20","context":"四川省成都市TD客户一公司 已发出,下一站 成都转运中心","status":"在途"} 占用85个,我们按照100个字符来评估,物流信息最大20*100=2000个字符,使用varchar(2048) 应该可以满足正常需求。
c 可能有人会说凡事总有例外,那我们从这个例外分析一下 如果一个物流有30或者40个节点信息 怎么办?
从深圳到黑龙江漠河 或者新疆乌鲁木齐到杭州,上海的节点信息估计会比较多。对于20个以上 的节点信息 我们不会去关注其中第10个 11个 14个 15个节点的信息。大家对快递的关注点是什么? 商家是否发货?快递公司是否揽件? 快递是否到达目的地的最后1公里。分析到这里,我们可以针对超过25个/30个以上的节点进行收缩处理,去掉中间非核心节点信息,在不影响用户体验的情况下,满足我们的varchar(2048)的设计。
3 分库分表
这点是迫不得已而为之的方案。现在虽然各种中间件都比较成熟,cobar,oneproxy ,mycat等靠谱的软件,但是对于一个创业公司目前我们还缺少相对应的分布式数据库的管理工具,1024个表如何做变更?这个其实也是一个相对比较困难的问题。
小结
经过一系列的分析和优化,我们最终将text字段转化为varchar(2048),发布到线上目前运行良好。回顾上面的优化过程是建立在对业务逻辑和物流相关知识有深入理解,对用户行为多加分析的基础之上的,该过程不需要高深的数据库知识。但是实际上开发往往简单粗暴的接受pd的功能设计理念,而不顾对底层基础架构的影响。其实只需要向前多走一步,我们可以做的更好,只不过这一步,可能是 优秀的程序员的一小步,是某些人的一大步。
留给大家一个问题:如何看待和解决 开发快速迭代带来的技术债?
开发反馈一个表的数据大小已经130G,对物理存储空间有影响,且不容易做数据库ddl变更。咨询了开发相关业务逻辑,在电商业务系统中,每笔订单成交之后会有一条对应的订单物流信息,因此需要设计一个物流相关的表用来存储该订单的物流节点信息,该表使用text字段存储物流信息。
大致的表结构:
CREATE TABLE `goods_order_express` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`express_id` int(10) unsigned NOT NULL,
`message` varchar(200) NOT NULL,
`status` varchar(20) NOT NULL,
`state` tinyint(3) unsigned NOT NULL,
`data` text NOT NULL,
`created_time` int(10) unsigned NOT NULL,
PRIMARY KEY (`id`),
KEY `idx_expid` (`express_id`)
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8mb4;
业务分析
当快递每到达一个中转站或者发生揽件,接收等事件,快递公司的api都会生成如下格式的信息(去掉业务相关敏感数据)
[{"time":"2016-03-16 11:16:20","ftime":"2016-03-16 11:16:20","context":"四川省成都市TD客户一公司 已发出,下一站成都转运中心","areaCode":"","areaName":"","status":"在途"},{"time":"2016-03-16 11:11:03","ftime":"2016-03-16 11:11:03","context":"四川省成都市TD客户一公司 已打包","areaCode":"","areaName":"","status":"在途"},{"time":"2016-03-16 11:08:09","ftime":"2016-03-16 11:08:09","context":"四川省成都市TD客户一公司 已揽收","areaCode":"","areaName":"","status":"收件"}]
该json 串 411个字符,开发业务程序去定期轮训调用相关api信息,并把上面的json串数据 insert 或者update 到goods_order_express的data字段。而且该表从开始到现在从未删除,积累了初始到现在的所有数据。随着公司业务爆发式增长,该表未来会更大,而且增长速度会更快。数据库服务器的磁盘空间面临不足,表结构变更难以操作。
如何优化?
1 能否减小数据量写入?
和业务分析,我们不能丢弃新增的数据。但是每一笔物流信息实际上是有生命周期的,从发货到收件完成即可完成其生命周期,也就是该数据可以不再展示了,我们基本不会查看一个已经收到货的物流信息。因此可以针对历史数据进行归档,比如将90天之前的数据备份到hbase中并且从MySQL 数据库中删除,从而维持该表的大小在一个合理的范围。
2 减少data 字段数据大小
a 缩小json串数据,保留有效数据
time 和ftime 是一样的,和开发确认ftime无功能使用,在我们的物流展示系统中 areaCode areaName也没有逻辑意义。
故对json数据做如下精简
[{"time":"2016-03-16 11:16:20","context":"四川省成都市TD客户一公司 已发出,下一站 成都转运中心","status":"在途"},{"time":"2016-03-16 11:11:03","context":"四川省成都市TD客户一公司 已打包","status":"在途"},{"time":"2016-03-16 11:08:09","context":"四川省成都市TD客户一公司 已揽收","status":"收件"}]
精简之后占用的字符数由411个减小为237个,减少47%的数据。
b 评估物流节点数
相信大家都有网购的经验 ,一般情况下快递大约含有15-20个节点信息
{"time":"2016-03-16 11:16:20","context":"四川省成都市TD客户一公司 已发出,下一站 成都转运中心","status":"在途"} 占用85个,我们按照100个字符来评估,物流信息最大20*100=2000个字符,使用varchar(2048) 应该可以满足正常需求。
c 可能有人会说凡事总有例外,那我们从这个例外分析一下 如果一个物流有30或者40个节点信息 怎么办?
从深圳到黑龙江漠河 或者新疆乌鲁木齐到杭州,上海的节点信息估计会比较多。对于20个以上 的节点信息 我们不会去关注其中第10个 11个 14个 15个节点的信息。大家对快递的关注点是什么? 商家是否发货?快递公司是否揽件? 快递是否到达目的地的最后1公里。分析到这里,我们可以针对超过25个/30个以上的节点进行收缩处理,去掉中间非核心节点信息,在不影响用户体验的情况下,满足我们的varchar(2048)的设计。
3 分库分表
这点是迫不得已而为之的方案。现在虽然各种中间件都比较成熟,cobar,oneproxy ,mycat等靠谱的软件,但是对于一个创业公司目前我们还缺少相对应的分布式数据库的管理工具,1024个表如何做变更?这个其实也是一个相对比较困难的问题。
小结
经过一系列的分析和优化,我们最终将text字段转化为varchar(2048),发布到线上目前运行良好。回顾上面的优化过程是建立在对业务逻辑和物流相关知识有深入理解,对用户行为多加分析的基础之上的,该过程不需要高深的数据库知识。但是实际上开发往往简单粗暴的接受pd的功能设计理念,而不顾对底层基础架构的影响。其实只需要向前多走一步,我们可以做的更好,只不过这一步,可能是 优秀的程序员的一小步,是某些人的一大步。
留给大家一个问题:如何看待和解决 开发快速迭代带来的技术债?
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

