用Golang写一个搜索引擎(0x03)
前面已经说了倒排索引的基本原理了,原理非常简单,也很好理解,关键是如何设计第二个倒排表,倒排表的第二列也很好设计,第一列就是关键了,为了满足快速查找的性能,设计第一列的结构,我们需要满足以下两个条件。
-
查找非常快,能在极短的时间内找到我们需要的关键词所在的位置。
-
添加关键词也需要比较快,能保证输入文档的时候尽可能的快。
除了上面两个条件以外,还有一些加分项:
-
如果能尽可能少的使用内存,那肯定是好的
-
如果能顺序的遍历整个列,也肯定比较好
为了满足能查找,能添加,我们首先想到的是顺序表,也就是链表了,链表的话,添加不成问题,关键是查找的复杂度是 O(n) ,这还能忍?所以链表第一个不考虑了。不过有一个链表的变种,我们是可以考虑一下,那就是 跳跃表 。
跳跃表(SkipList)
什么是跳跃表呢?跳跃表也叫跳表,我们可以把它看成是链表的一个变种,是一个 多层顺序链表的并联结构的表 ,维基百科的定义是
是一种随机化数据结构,基于并联的链表,其效率可比拟于二叉查找树(对于大多数操作需要O(log n)平均时间)
我们通过一个图来看一下跳跃表( 图片来源 )
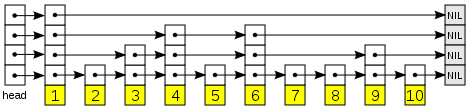
很明显,最底层是一个顺序表,然后在1,3,4,6,9节点上出现了第二层的链表,然后继续在1,4,6节点上面出现了第三层链表,这样构建出来的三层链表查询效率比一层的就高了,一般情况下,跳表的构建方式是按照概率来决定是否需要为这个节点增加一层,这里在层 i 中的元素按某个固定的概率 p (通常为0.5或0.25)出现在层 i +1 中。平均起来,每个元素都在 1/(1- p ) 个列表中出现,而最高层的元素(通常是在跳跃列表前端的一个特殊的头元素)在 O(log1/ p n ) 个列表中出现。
查找元素的时候,起步于头元素和顶层列表,并沿着每个链表搜索,直到到达小于或着等于目标的最后一个元素。通过跟踪起自目标直到到达在更高列表中出现的元素的反向查找路径,在每个链表中预期的步数显而易见是 1/ p 。所以查找的总体代价是 O((log1/ p n) / p),当 p 是常数时是 O(log n )。通过选择不同 p 值,就可以在查找代价和存储代价之间作出权衡。
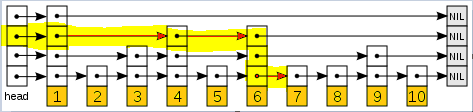
比如还是上面那个图,我们要查找7这个元素,需要遍历1—>4—>6—>7,比一层链表效率高不少吧
在实现跳表的时候,虽然一般是用概率来决定是否需要增加当前节点的层级,但是实际中可以具体问题具体分析,比如我们知道底层链表大概有多长,那么我们每格10个元素增加一个层级,那么这样的跳表的存储空间我们大概也能估算出来,平均查询时间我们也能估算出来。
跳跃表是一个非常有用的数据结构,并且实现起来也比较容易,链表大家都知道实现,那么跳跃表就是一组链表啦,只是增加和删除的时候需要操作多个链表而已。
我的项目中暂时没有使用跳跃表,后续有需求的时候再加上吧,所以大家看不到代码了。让你失望了。呵呵。
一般跳跃表可以和hash配合起来使用,因为hash有桶,占用的内存较大,如果将hash值存在跳跃表中,用mmap把跳跃表加载到内存中,那么既节省了内存,又有一个较好的查询速度,而且实现起来还挺简单。
跳跃表用来实现搜索引擎的自增长类型的主键也比较合适,首先在搜索引擎中,主键的查找并不是那么频繁,一般查询都是通过关键字查询的,对主键来说,对查询速度要求并不是特别高,只有在修改主键的时候需要进行查询,其次自增长的主键一般情况下插入操作直接在链表后面append就可以了,不用进行查询,所以插入的时候也比较快。
哈希表
处理跳跃表,哈希表也是一个实现方式,哈希表是根据关键字(Key value)而直接访问在内存存储位置的数据结构。也就是说,它通过计算一个关于键值的函数,将所需查询的数据映射到表中一个位置来访问记录,这加快了查找速度。这个映射函数称做散列函数,存放记录的数组称做哈希表,也叫散列表。
哈希是大数据技术的基础,大家应该都有了解了,这里就不深度展开了,算法导论有一章已经讲得非常清楚了,这里说说我觉得比较有意思的一个哈希的东西。
哈希表的核心是哈希算法,一个好的哈希算法可以让碰撞产生得更少,查找速度越接近于O(1),所以一个好的哈希算法非常重要。
哈希算法很多,说都说不完,不同的算法适应不同的场景,我知道的,传说中有一个哈希算法,来自 魔兽世界(!!!!为了部落!!!!) ,号称 暴雪哈希 ,该算法产生的哈希值完全无法预测,被称为 "One-Way Hash"( A one-way hash is a an algorithm that is constructed in such a way that deriving the original string (set of strings, actually) is virtually impossible)。
以下是这个算法的Go语言实现,在我的项目中也有,不过后来我没有用hash表,所以删掉了,号称有这个算法,所有字符串都不在话下,碰撞概率很低。
// 初始化hash计算需要的基础map table func initCryptTable() { var seed, index1, index2 uint64 = 0x00100001, 0, 0 i := 0 for index1 = 0; index1 < 0x100; index1 += 1 { for index2, i = index1, 0; i < 5; index2 += 0x100 { seed = (seed*125 + 3) % 0x2aaaab temp1 := (seed & 0xffff) << 0x10 seed = (seed*125 + 3) % 0x2aaaab temp2 := seed & 0xffff cryptTable[index2] = temp1 | temp2 i += 1 } } } // hash, 以及相关校验hash值 func HashKey(lpszString string, dwHashType int) uint64 { i, ch := 0, 0 var seed1, seed2 uint64 = 0x7FED7FED, 0xEEEEEEEE var key uint8 strLen := len(lpszString) for i < strLen { key = lpszString[i] ch = int(toUpper(rune(key))) i += 1 seed1 = cryptTable[(dwHashType<<8)+ch] ^ (seed1 + seed2) seed2 = uint64(ch) + seed1 + seed2 + (seed2 << 5) + 3 } return uint64(seed1) }哈希表的实现方式有很多中,最最基础的就是 数组+链表 的形式了,也叫开链哈希,数组长度就是哈希的桶的长度,链表用来解决冲突,插入数据的时候如果哈希碰撞了,把具体节点挂在该节点后面的链表上,查询数据时候有冲突,就继续线性查询这个节点下的链表。
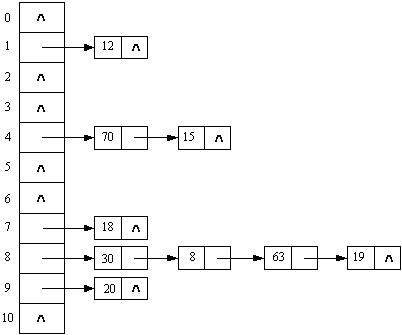
还有一种叫闭链哈希,闭链哈希实际是一个循环数组,数组长度就是桶的长度,插入数据的时候有冲突的话,移动到该节点的下一个,直到没有冲突为止,如果移动到了末尾的话,转到数组的头部,查找数据的时候类似。
这里又出现一个小问题,如果碰撞了的话,不管是开链还是闭链哈希,都需要进行线性匹配,而且比较的是两个数据的实际值,所以不管是那种哈希实现,都需要在节点中保存原始的数据信息,不然碰撞的时候没办法匹配了,这样就衍生出来两个问题:
-
如果Key是一个比较长的字符串,那么哈希表的存储空间相应就要变得比较大,才能存储住这个字符串用来比较。
-
如果是字符串比较,那么速度比较慢,当碰撞较多的时候,会影响性能,虽然现在的机器这些个比较都不在话下了。
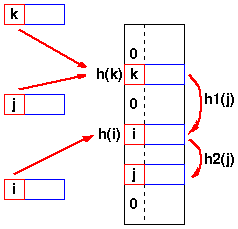
然而, 雷霆崖 的程序员想了一个更好的办法,用上面那个哈希函数,通过不同的 dwHashType ,哈希了三次,得到三个整数,第一个整数用来确定位置,第二和第三个整数用来代替原始字符串,存储在哈希表的节点中用于解决冲突,当要查询时,先计算待查询的Key的三个哈希值,然后用第一个去定位,如果第一个值没冲突,返回节点,如果冲突了,那么不管是开链实现方式还是闭链实现方式,查找下一个节点,然后比较这两个节点的第二和第三哈希值,如果一样的话,返回节点,不一样的话继续查找下一个,通过这么倒腾,首先,存储空间的问题解决了,每个哈希节点只需要存3个整数,空间固定了,第二个问题也解决了,比较两个整数总比比较字符串快多了吧。
好了,跳跃表和哈希表就是这些了,在我的代码中没有跳跃表,后续才会加上,哈希表本来有,后来为了节省内存空间,用了B+树来替代哈希表了,所以哈希表的代码暂时看不到,不过我已经把 暴雪哈希 写上面了哈。
下面一章会详细将一下B+树了,我代码里面也是用的B+树,而且几乎所有的数据库的索引也是用的B+树。
最后,打一广告,我的微信公众号,目前没什么订阅者 T_T。文章的更新频率会在一周3到5篇左右吧,欢迎大家扫描一下下面的微信公众号订阅,首先会在这里发出来:)

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

