Akka在Flink中的使用剖析
Akka与Actor 模型
Akka是一个用来开发支持 并发 、 容错 、 扩展性 的应用程序框架。它是 actor model 的实现,因此跟Erlang的并发模型很像。在actor模型的上下文中,所有的活动实体都被认为是互不依赖的actor。actor之间的互相通信是通过彼此之间发送异步消息来实现的。每个actor都有一个邮箱来存储接收到的消息。因此每个actor都维护着自己独立的状态。
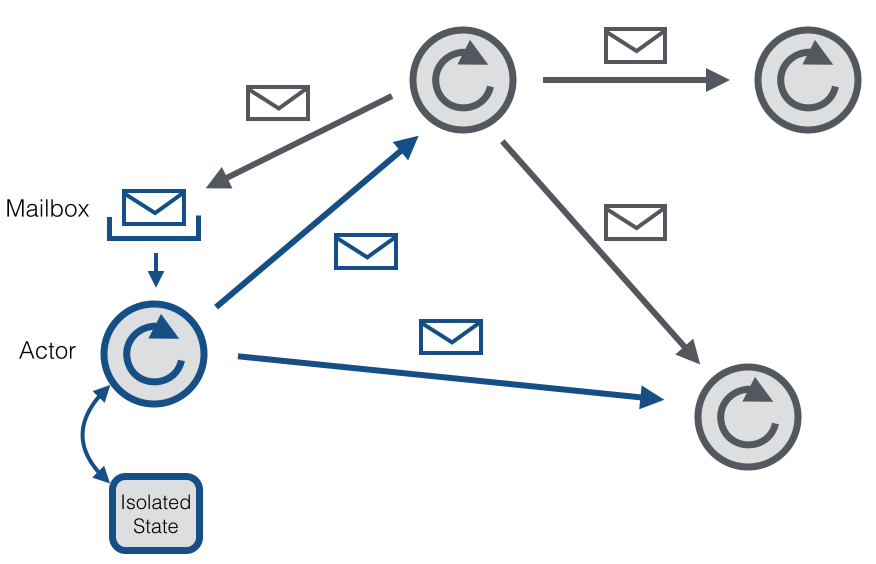
每个actor是一个单一的线程,它不断地从其邮箱中poll(拉取)消息,并且连续不断地处理。对于已经处理过的消息的结果,actor可以改变它自身的内部状态或者发送一个新消息或者孵化一个新的actor。尽管单个的actor是自然有序的,但一个包含若干个actor的系统却是高度并发的并且极具扩展性的。因为那些处理线程是所有actor之间共享的。这也是我们为什么不该在actor线程里调用可能导致阻塞的“调用”。因为这样的调用可能会阻塞该线程使得他们无法替其他actor处理消息。
Actor系统
一个actor系统是所有actor存活的容器。它也提供一些共享的服务,比如 调度 , 配置 , 日志记录 等。一个actor系统也同时维护着一个为所有actor服务的线程池。多个actor系统可以在一台主机上共存。如果一个actor系统以 RemoteActorRefProvider 的身份启动,那么它可以被某个远程主机上的另一个actor系统访问。actor系统会自动得识别actor消息被路由到处于同一个actor系统内的某个actor还是处于一个远程actor系统内的actor。如果是本地通信的情况(同一个actor系统),那么消息的传输可以有效得利用共享内存的方式;如果是远程通信,那么消息将通过网络栈来传输。
actor基于层次化的组织形式(也就是说它基于树形结构)。每个新创建的actor都将以创建它的actor作为父节点。层次结构有利于监督、管理(父actor管理其子actor)。如果某个actor的子actor产生错误,该actor将会得到通知,如果它有能力处理这个错误,那么它会尝试处理否则它会负责重启该子actor。系统创建的首个actor将托管于系统提供的guardian actor /user 。
Flink为什么要用Akka来代替RPC
原先的RPC服务存在的问题:
- 没有带回调的异步调用功能,这也是为什么Flink的多个运行时组件需要poll状态的原因,这导致了不必要的延时。
- 没有
exception forwarding,产生的异常都只能简单地 吞噬 掉,这使得在运行时产生一些非常难调试的古怪问题 - 处理器的线程数受到限制,RPC只能处理一定量的并发请求,这迫使你不得不隔离线程池
- 参数不支持原始数据类型(或者原始数据类型的装箱类型),所有的一切都必须有一个特殊的序列化类
- 棘手的线程模型,RPC会持续的产生或终止线程
采用Akka的actor模型带来的好处:
- Akka解决上述的所有问题,并对外透明
-
supervisor模型允许你对actor做失效检测,它提供一个统一的方式来检测与处理失败(比如心跳丢失、调用失败…) - Akka有工具来持久化有状态的actor,一旦失败可以在其他机器上重启他们。这个机制在 master fail-over 的场景下将会变得非常有用并且很重要。
- 你可以定义许多 call target (actor),在TaskManager上的任务可以直接在JobManager上调用它们的
ExecutionVertex,而不是调用JobManager,让其产生一个线程来查看执行状态。 - actor模型接近于在actor上采用队列模型一个接一个的运行,这使得状态机的并发模型变得简单而又健壮
Akka在Flink中的使用
Akka在Flink中用于三个分布式技术组件之间的通信,他们是 JobClient , JobManager , TaskManager 。Akka在Flink中主要的作用是用来充当一个 coordinator 的角色。
JobClient 获取用户提交的job,然后将其提交给 JobManager 。 JobManager 随后对提交的job进行执行的环境准备。首先,它会分配job的执行需要的大量资源,这些资源主要是在 TaskManager 上的 execution slots 。在资源分配完成之后, JobManager 会部署不同的task到特定的 TaskManager 上。在接收到task之后, TaskManager 会创建线程来执行。所有的状态改变,比如开始计算或者完成计算都将给发回给 JobManager 。基于这些状态的改变, JobManager 将引导task的执行直到其完成。一旦job完成执行,其执行结果将会返回给 JobClient ,进而告知用户
它们之间的一些通信流程如下图所示:
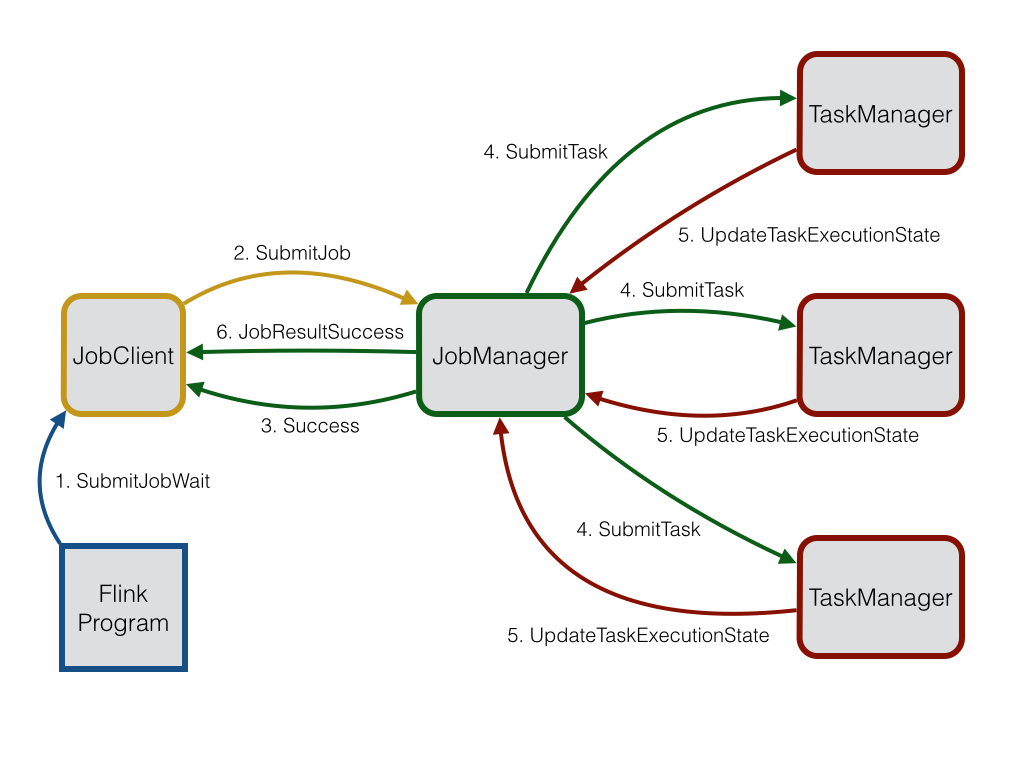
上图中三个使用Akka通信的分布式组件都具有自己的actor系统。
代码分析
当前关于Akka相关的代码,都在 runtime module下,但实现的代码是 Java 跟 Scala 混合的(也许这块的逻辑Flink正在过渡阶段,后续会有更多的逻辑改为用Scala实现)。
其中,只有 JobClient 的Akka代码是用Java实现的。 JobManager 以及 TaskManager 跟Akka相关的逻辑以Scala实现。
消息定义
- Messages : 三个分布式组件都会用到的消息定义
- JobClientMessages :
JobClient相关的message,将会被org.apache.flink.runtime.client.JobClientActor使用 - JobManagerMessages :
JobManager相关的message - TaskManagerMessages :
TaskManager相关的message定义
当然不止这么多消息,还有垂直划分的几种定义,比如: RegistrationMessages 用于定义 TaskManager 和 JobManager 相关的register消息。
下面我们看看在Java和Scala中,Flink实现的actor的基类。
基类FlinkUntypedActor
在Akka提供的Java lib中,实现一个actor通常是靠继承 UntypedActor 来实现。 FlinkUntypedActor 也不例外。继承自 UntypedActor 的类,通常要覆盖 onReceive 方法,该方法的完整签名如下:
public final void onReceive(Object message) throws Exception {}
然后,通常在这个方法里会判断具体的消息类型,根据不同的消息类型来实现不同的处理逻辑。而在 FlinkUntypedActor 类中,它先对消息进行一轮验证,过滤掉非法的消息后,再处理各种消息的类型。验证主要是比对sessionID是否合法(即是否等同于leader session id),然后才会调用核心处理逻辑方法 handleMessage 。该方法是抽象方法,有待子类具体实现,目前只有涉及到 JobClient 处理的 JobClientActor 类继承了该类。
由scala实现的 FlinkActor 几乎具有相同的语义,这里不再啰嗦。
总结
本篇主要介绍了Akka,并对Akka在Flink中的使用进行了大致的介绍。其实,就源码而言倒没有太多值得关注的地方,主要还是三个分布式组件之间的通信/协同逻辑,下篇我们会谈这方面的话题。
本文参考文档: https://cwiki.apache.org/confluence/display/FLINK/Akka+and+Actors

正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

