深入JDK源码之ThreadLocal类
ThreadLocal概述
学习JDK中的类,首先看下JDK API对此类的描述,描述如下:
该类提供了线程局部 (thread-local) 变量。这些变量不同于它们的普通对应物,因为访问某个变量(通过其 get 或 set 方法)的每个线程都有自己的局部变量,它独立于变量的初始化副本。 ThreadLocal其实就是一个工具类,用来操作线程局部变量,ThreadLocal 实例通常是类中的 private static 字段。它们希望将状态与某一个线程(例如,用户 ID 或事务 ID)相关联。 例如,以下类生成对每个线程唯一的局部标识符。线程 ID 是在第一次调用
UniqueThreadIdGenerator.getCurrentThreadId() 时分配的,在后续调用中不会更改。
其实ThreadLocal并非是一个线程的本地实现版本,它并不是一个Thread,而是threadlocalvariable(线程局部变量)。也许把它命名为ThreadLocalVar更加合适。线程局部变量(ThreadLocal)其实的功用非常简单,就是为每一个使用该变量的线程都提供一个变量值的副本,是Java中一种较为特殊的线程绑定机制,是每一个线程都可以独立地改变自己的副本,而不会和其它线程的副本冲突。
import java.util.concurrent.atomic.AtomicInteger; public class UniqueThreadIdGenerator { private static final AtomicInteger uniqueId = new AtomicInteger(0); private static final ThreadLocal < Integer > uniqueNum = new ThreadLocal < Integer > () { @Override protected Integer initialValue() { return uniqueId.getAndIncrement(); } }; public static int getCurrentThreadId() { return uniqueId.get(); } } 从线程的角度看,每个线程都保持对其线程局部变量副本的隐式引用,只要线程是活动的并且 ThreadLocal 实例是可访问的;在线程消失之后,其线程局部实例的所有副本都会被垃圾回收(除非存在对这些副本的其他引用)。
API表达了下面几种观点:
- ThreadLocal不是线程,是线程的一个变量,你可以先简单理解为线程类的属性变量。
- ThreadLocal 在类中通常定义为静态类变量。
- 每个线程有自己的一个ThreadLocal,它是变量的一个‘拷贝’,修改它不影响其他线程。
既然定义为类变量,为何为每个线程维护一个副本(姑且成为‘拷贝’容易理解),让每个线程独立访问?多线程编程的经验告诉我们,对于线程共享资源(你可以理解为属性),资源是否被所有线程共享,也就是说这个资源被一个线程修改是否影响另一个线程的运行,如果影响我们需要使用synchronized同步,让线程顺序访问。
ThreadLocal适用于资源共享但不需要维护状态的情况,也就是一个线程对资源的修改,不影响另一个线程的运行;这种设计是 空间换时间 ,synchronized顺序执行是 时间换取空间 。
ThreadLocal介绍
从字面上来理解ThreadLocal,感觉就是相当于线程本地的。我们都知道,每个线程在jvm的虚拟机里都分配有自己独立的空间,线程之间对于本地的空间是相互隔离的。那么ThreadLocal就应该是该线程空间里本地可以访问的数据了。ThreadLocal变量高效地为每个使用它的线程提供单独的线程局部变量值的副本。每个线程只能看到与自己相联系的值,而不知道别的线程可能正在使用或修改它们自己的副本。
很多人看到这里会容易产生一种错误的印象,感觉是不是这个ThreadLocal对象建立了一个类似于全局的map,然后每个线程作为map的key来存取对应线程本地的value。你看,每个线程不一样,所以他们映射到map中的key应该也不一样。实际上,如果我们后面详细分析ThreadLocal的代码时,会发现不是这样的。它具体是怎么实现的呢?

ThreadLocal源码
ThreadLocal类本身定义了有get(), set()和initialValue()三个方法。前面两个方法是public的,initialValue()是protected的,主要用于我们在定义ThreadLocal对象的时候根据需要来重写。这样我们初始化这么一个对象在里面设置它的初始值时就用到这个方法。 ThreadLocal变量因为本身定位为要被多个线程来访问,它通常被定义为static变量 。
ThreadLocal有一个ThreadLocalMap静态内部类,你可以简单理解为一个MAP,这个Map为每个线程复制一个变量的‘拷贝’存储其中。
当线程调用ThreadLocal.get()方法获取变量时,首先获取当前线程引用,以此为key去获取响应的ThreadLocalMap,如果此‘Map’不存在则初始化一个,否则返回其中的变量,代码如下:
public T get() { Thread t = Thread.currentThread(); ThreadLocalMap map = getMap(t); if (map != null) { ThreadLocalMap.Entry e = map.getEntry(this); if (e != null) return (T)e.value; } return setInitialValue(); } 调用get方法如果此Map不存在首先初始化,创建此map,将线程为key,初始化的vlaue存入其中,注意此处的initialValue,我们可以覆盖此方法,在首次调用时初始化一个适当的值。setInitialValue代码如下:
private T setInitialValue() { T value = initialValue(); Thread t = Thread.currentThread(); ThreadLocalMap map = getMap(t); if (map != null) map.set(this, value); else createMap(t, value); return value; } set方法相对比较简单如果理解以上俩个方法,获取当前线程的引用,从map中获取该线程对应的map,如果map存在更新缓存值,否则创建并存储,代码如下:
public void set(T value) { Thread t = Thread.currentThread(); ThreadLocalMap map = getMap(t); if (map != null) map.set(this, value); else createMap(t, value); } 对于ThreadLocal在何处存储变量副本,我们看getMap方法:获取的是当前线程的ThreadLocal类型的threadLocals属性。显然变量副本存储在每一个线程中。
/** * 获取线程的ThreadLocalMap 属性实例 */ ThreadLocalMap getMap(Thread t) { return t.threadLocals; } 上面我们知道变量副本存放于何处,这里我们简单说下如何被java的垃圾收集机制收集,当我们不在使用时调用set(null),此时不在将引用指向该‘map’,而线程退出时会执行资源回收操作,将申请的资源进行回收,其实就是将属性的引用设置为null。这时已经不在有任何引用指向该map,故而会被垃圾收集。
注意:如果ThreadLocal.set()进去的东西本来就是多个线程共享的同一个对象,那么多个线程的ThreadLocal.get()取得的还是这个共享对象本身,还是有并发访问问题。
看到ThreadLocal类中的变量只有这3个int型:
/** * ThreadLocals rely on per-thread linear-probe hash maps attached * to each thread (Thread.threadLocals and * inheritableThreadLocals). The ThreadLocal objects act as keys, * searched via threadLocalHashCode. This is a custom hash code * (useful only within ThreadLocalMaps) that eliminates collisions * in the common case where consecutively constructed ThreadLocals * are used by the same threads, while remaining well-behaved in * less common cases. */ private final int threadLocalHashCode = nextHashCode(); /** * The next hash code to be given out. Updated atomically. Starts at * zero. */ private static AtomicInteger nextHashCode = new AtomicInteger(); /** * The difference between successively generated hash codes - turns * implicit sequential thread-local IDs into near-optimally spread * multiplicative hash values for power-of-two-sized tables. */ private static final int HASH_INCREMENT = 0x61c88647;
而作为ThreadLocal实例的变量只有 threadLocalHashCode 这一个,nextHashCode 和HASH_INCREMENT 是ThreadLocal类的静态变量,实际上HASH_INCREMENT是一个常量,表示了连续分配的两个ThreadLocal实例的threadLocalHashCode值的增量,而nextHashCode 的表示了即将分配的下一个ThreadLocal实例的threadLocalHashCode 的值。
现在来看看它的哈希策略。所有ThreadLocal对象共享一个AtomicInteger对象nextHashCode用于计算hashcode,一个新对象产生时它的hashcode就确定了,算法是从0开始,以 HASH_INCREMENT = 0x61c88647 为间隔递增,这是ThreadLocal唯一需要同步的地方。根据hashcode定位桶的算法是将其与数组长度-1进行与操作: key.threadLocalHashCode & (table.length - 1) 。
0x61c88647这个魔数是怎么确定的呢?
ThreadLocalMap的初始长度为16,每次扩容都增长为原来的2倍,即它的长度始终是2的n次方,上述算法中使用
0x61c88647 可以让hash的结果在2的n次方内尽可能均匀分布,减少冲突的概率。
可以来看一下创建一个ThreadLocal实例即new ThreadLocal()时做了哪些操作,从上面看到构造函数ThreadLocal()里什么操作都没有,唯一的操作是这句:
private final int threadLocalHashCode = nextHashCode();
那么nextHashCode()做了什么呢:
private static synchronized int nextHashCode() { int h = nextHashCode; nextHashCode = h + HASH_INCREMENT; return h; } 就是将ThreadLocal类的下一个hashCode值即nextHashCode的值赋给实例的threadLocalHashCode,然后nextHashCode的值增加HASH_INCREMENT这个值。
因此ThreadLocal实例的变量只有这个threadLocalHashCode,而且是final的,用来区分不同的ThreadLocal实例,ThreadLocal类主要是作为工具类来使用,那么ThreadLocal.set()进去的对象是放在哪儿的呢?
看一下上面的set()方法,两句合并一下成为:
ThreadLocalMap map = Thread.currentThread().threadLocals;
这个ThreadLocalMap 类是ThreadLocal中定义的内部类,但是它的实例却用在Thread类中:
public class Thread implements Runnable { ...... /* ThreadLocal values pertaining to this thread. This map is maintained * by the ThreadLocal class. */ ThreadLocal.ThreadLocalMap threadLocals = null; /* * InheritableThreadLocal values pertaining to this thread. This map is * maintained by the InheritableThreadLocal class. */ ThreadLocal.ThreadLocalMap inheritableThreadLocals = null; ...... } 这就说明了其实每个Thread本身就包含了两个ThreadLocalMap对象的引用。这一点非常重要。以后每个thread要访问他们的local对象时,就是访问存在这个ThreadLocalMap里的value。
ThreadLocalMap是定义在ThreadLocal类内部的私有类,它是采用“开放定址法”解决冲突的hashmap。key是ThreadLocal对象。当调用某个ThreadLocal对象的get或put方法时,首先会从当前线程中取出ThreadLocalMap,然后查找对应的value:
public T get() { Thread t = Thread.currentThread(); ThreadLocalMap map = getMap(t); //拿到当前线程的ThreadLocalMap if (map != null) { ThreadLocalMap.Entry e = map.getEntry(this); // 以该ThreadLocal对象为key取value if (e != null) return (T)e.value; } return setInitialValue(); } ThreadLocalMap getMap(Thread t) { return t.threadLocals; } 再看这句:
if (map != null) map.set(this, value);
也就是将该ThreadLocal实例作为key,要保持的对象作为值,设置到当前线程的ThreadLocalMap 中,get()方法同样大家看了代码也就明白了,ThreadLocalMap 类的代码太多了,我就不帖了,自己去看源码吧。
自然想法实现
一个非常自然想法是用一个线程安全的 Map<Thread,Object> 实现:
class ThreadLocal { private Map values = Collections.synchronizedMap(new HashMap()); public Object get() { Thread curThread = Thread.currentThread(); Object o = values.get(curThread); if (o == null && !values.containsKey(curThread)) { o = initialValue(); values.put(curThread, o); } return o; } public void set(Object newValue) { values.put(Thread.currentThread(), newValue); } } 但这是非常naive的:
- ThreadLocal本意是避免并发,用一个全局Map显然违背了这一初衷;
- 用Thread当key,除非手动调用remove,否则即使线程退出了会导致:1)该Thread对象无法回收;2)该线程在所有ThreadLocal中对应的value也无法回收。
JDK 的实现刚好是反过来的:
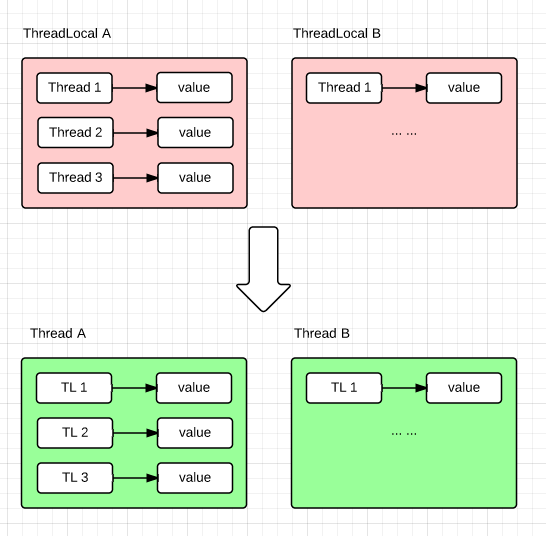
碰撞解决与神奇的0x61c88647
既然ThreadLocal用map就避免不了冲突的产生。
碰撞避免和解决
这里碰撞其实有两种类型:
(1)只有一个ThreadLocal实例的时候(上面推荐的做法),当向thread-local变量中设置多个值的时产生的碰撞,碰撞解决是通过开放定址法, 且是线性探测(linear-probe)。
(2)多个ThreadLocal实例的时候,最极端的是每个线程都new一个ThreadLocal实例,此时利用特殊的哈希码0x61c88647大大降低碰撞的几率, 同时利用开放定址法处理碰撞。
神奇的0x61c88647
注意 0x61c88647 的利用主要是为了多个ThreadLocal实例的情况下用的。从ThreadLocal源码中找出这个哈希码所在的地方:
/** * ThreadLocals rely on per-thread linear-probe hash maps attached * to each thread (Thread.threadLocals and inheritableThreadLocals). * The ThreadLocal objects act as keys, searched via threadLocalHashCode. * This is a custom hash code (useful only within ThreadLocalMaps) that * eliminates collisions in the common case where consecutively * constructed ThreadLocals are used by the same threads, * while remaining well-behaved in less common cases. */ private final int threadLocalHashCode = nextHashCode(); /** * The next hash code to be given out. Updated atomically. * Starts at zero. */ private static AtomicInteger nextHashCode = new AtomicInteger(); /** * The difference between successively generated hash codes - turns * implicit sequential thread-local IDs into near-optimally spread * multiplicative hash values for power-of-two-sized tables. */ private static final int HASH_INCREMENT = 0x61c88647; /** * Returns the next hash code. */ private static int nextHashCode() { return nextHashCode.getAndAdd(HASH_INCREMENT); } 注意实例变量threadLocalHashCode, 每当创建ThreadLocal实例时这个值都会累加 0x61c88647, 目的在上面的注释中已经写的很清楚了:为了让哈希码能均匀的分布在2的N次方的数组里, 即 Entry[] table 。
下面来看一下ThreadLocal怎么使用的这个 threadLocalHashCode 哈希码的,下面是ThreadLocalMap静态内部类中的set方法的部分代码:
// Set the value associated with key. private void set(ThreadLocal key, Object value) { Entry[] tab = table; int len = tab.length; int i = key.threadLocalHashCode & (len-1); for (Entry e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) {...} ... key.threadLocalHashCode & (len-1) 这么用是什么意思? 先看一下table数组的长度吧:
/** * The table, resized as necessary. * table.length MUST always be a power of two. */ private Entry[] table;
哇,ThreadLocalMap 中 Entry[] table 的大小必须是2的N次方呀(len = 2^N),那 len-1 的二进制表示就是低位连续的N个1, 那 key.threadLocalHashCode & (len-1) 的值就是 threadLocalHashCode 的低N位, 这样就能均匀的产生均匀的分布? 我用python做个实验吧:
>>> HASH_INCREMENT = 0x61c88647 >>> def magic_hash(n): ... for i in range(n): ... nextHashCode = i * HASH_INCREMENT + HASH_INCREMENT ... print nextHashCode & (n - 1), ... print ... >>> magic_hash(16) 7 14 5 12 3 10 1 8 15 6 13 4 11 2 9 0 >>> magic_hash(32) 7 14 21 28 3 10 17 24 31 6 13 20 27 2 9 16 23 30 5 12 19 26 1 8 15 22 29 4 11 18 25 0
产生的哈希码分布真的是很均匀,而且没有任何冲突啊, 太神奇了。
ThreadLocal内存泄漏
很多人认为:threadlocal里面使用了一个存在弱引用的map,当释放掉threadlocal的强引用以后,map里面的value却没有被回收.而这块value永远不会被访问到了. 所以存在着内存泄露. 最好的做法是将调用threadlocal的remove方法。
说的也比较正确,当value不再使用的时候,调用remove的确是很好的做法.但内存泄露一说却不正确. 这是threadlocal的设计的不得已而为之的问题. 首先,让我们看看在threadlocal的生命周期中,都存在哪些引用吧. 看下图: 实线代表强引用,虚线代表弱引用。
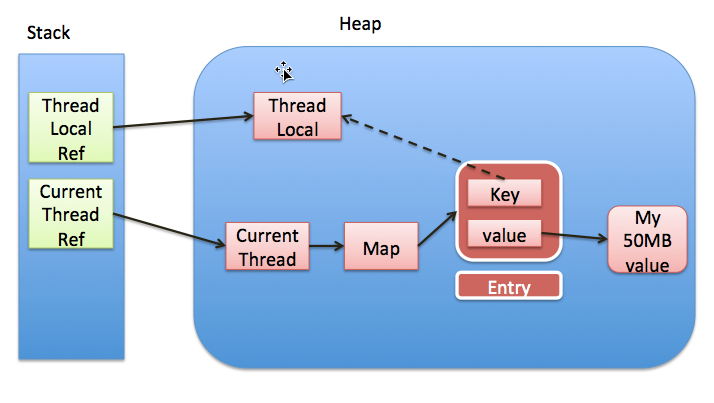
每个thread中都存在一个map, map的类型是ThreadLocal.ThreadLocalMap. Map中的key为一个threadlocal实例. 这个Map的确使用了弱引用,不过弱引用只是针对key. 每个key都弱引用指向threadlocal. 当把threadlocal实例tl置为null以后,没有任何强引用指向threadlocal实例,所以threadlocal将会被gc回收. 但是,我们的value却不能回收,因为存在一条从current thread连接过来的强引用. 只有当前thread结束以后, current thread就不会存在栈中,强引用断开, Current Thread, Map, value将全部被GC回收。通过源码看下此处的实现,如下:
public void set(T value) { Thread t = Thread.currentThread(); ThreadLocalMap map = getMap(t); if (map != null) map.set(this, value); // 将当前threadLocal实例作为key else createMap(t, value); } private void set(ThreadLocal key, Object value) { // We don't use a fast path as with get() because it is at // least as common to use set() to create new entries as // it is to replace existing ones, in which case, a fast // path would fail more often than not. Entry[] tab = table; int len = tab.length; int i = key.threadLocalHashCode & (len-1); for (Entry e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) { ThreadLocal k = e.get(); if (k == key) { e.value = value; return; } if (k == null) { replaceStaleEntry(key, value, i); return; } } tab[i] = new Entry(key, value); // 构造key-value实例 int sz = ++size; if (!cleanSomeSlots(i, sz) && sz >= threshold) rehash(); } static class Entry extends WeakReference<ThreadLocal> { /** The value associated with this ThreadLocal. */ Object value; Entry(ThreadLocal k, Object v) { super(k); // 构造key弱引用 value = v; } } public T get() { Thread t = Thread.currentThread(); ThreadLocalMap map = getMap(t); if (map != null) { ThreadLocalMap.Entry e = map.getEntry(this); if (e != null) return (T)e.value; } return setInitialValue(); } ThreadLocalMap getMap(Thread t) { return t.threadLocals; } 从中可以看出,弱引用只存在于key上,所以key会被回收. 而value还存在着强引用.只有thead退出以后,value的强引用链条才会断掉。一旦某个ThreadLocal对象没有强引用了,它在所有线程内部的ThreadLocalMap中的key都将被GC掉(此时value还未回收),在map后续的get/set中会探测到key被回收的entry,将其 value 设置为 null 以帮助GC,因此 value 在 key 被 GC 后可能还会存活一段时间,但最终也会被回收。这个过程和java.util.WeakHashMap的实现几乎是一样的。
因此ThreadLocal本身是没有内存泄露问题的,通常由它引发的内存泄露问题都是线程只 put 而忘了 remove 导致的,从上面分析可知,即使线程退出了,只要 ThreadLocal 还有强引用,该线程曾经 put 过的东西是不会被回收掉的。
ThreadLocal有何用
很多时候我们会创建一些静态域来保存全局对象,那么这个对象就可能被任意线程访问到,如果它是线程安全的,这当然没什么说的。然而大部分情况下它不是线程安全的(或者无法保证它是线程安全的),尤其是当这个对象的类是由我们自己(或身边的同事)创建的(很多开发人员对线程的知识都是一知半解,更何况线程安全)。
这时候我们就需要为每个线程都创建一个对象的副本。我们当然可以用ConcurrentMap 来保存这些对象,但问题是当一个线程结束的时候我们如何删除这个线程的对象副本呢?
ThreadLocal为我们做了一切。首先我们声明一个全局的ThreadLocal对象(final static,没错,我很喜欢final),当我们创建一个新线程并调用threadLocal.get时,threadLocal会调用initialValue方法初始化一个对象并返回,以后无论何时我们在这个线程中调用get方法,都将得到同一个对象(除非期间set过)。而如果我们在另一个线程中调用get,将的到另一个对象,而且始终会得到这个对象。
当一个线程结束了,ThreadLocal就会释放跟这个线程关联的对象,这不需要我们关心,反正一切都悄悄地发生了。
(以上叙述只关乎线程,而不关乎get和set是在哪个方法中调用的。以前有很多不理解线程的同学总是问我这个方法是哪个线程,那个方法是哪个线程,我不知如何回答。)
所以,保存”线程局部变量”的map并非是ThreadLocal的成员变量, 而是java.lang.Thread的成员变量。也就是说,线程结束的时候,该map的资源也同时被回收。通过如下代码:
ThreadLocal的set,get方法中均通过如下方式获取Map: ThreadLocalMap map = getMap(t); 而getMap方法的代码如下: ThreadLocalMap getMap(Thread t) { return t.threadLocals; } 可见:ThreadLocalMap实例是作为java.lang.Thread的成员变量存储的,每个线程有唯一的一个threadLocalMap。这个map以ThreadLocal对象为key,”线程局部变量”为值,所以一个线程下可以保存多个”线程局部变量”。对ThreadLocal的操作,实际委托给当前Thread,每个Thread都会有自己独立的ThreadLocalMap实例,存储的仓库是Entry[] table;Entry的key为ThreadLocal,value为存储内容;因此在并发环境下,对ThreadLocal的set或get,不会有任何问题。以下为”线程局部变量”的存储图:
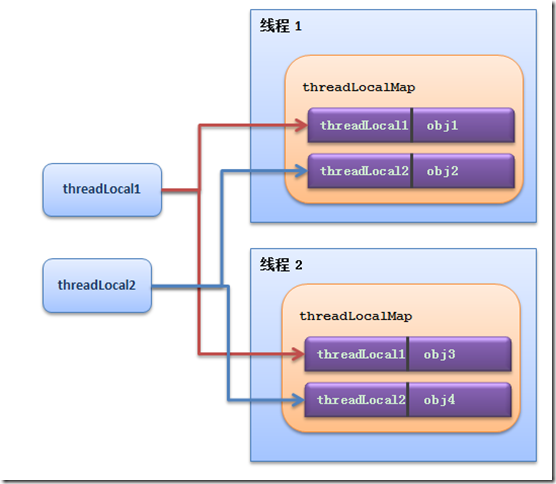
由于treadLocalMap是java.util.Thread的成员变量,threadLocal作为threadLocalMap中的key值,在一个线程中只能保存一个”线程局部变量”。将ThreadLocalMap作为Thread类的成员变量的好处是:
a. 当线程死亡时,threadLocalMap被回收的同时,保存的”线程局部变量”如果不存在其它引用也可以同时被回收。
b. 同一个线程下,可以有多个treadLocal实例,保存多个”线程局部变量”。
c. 同一个threadLocal实例,可以有多个线程使用,保存多个线程的“线程局部变量”。
ThreadLocal的应用
我们在多线程的开发中,经常会考虑到的策略是对一些需要公开访问的属性通过设置同步的方式来访问。这样每次能保证只有一个线程访问它,不会有冲突。但是这样做的结果会使得性能和对高并发的支持不够。在某些情况下,如果我们不一定非要对一个变量共享不可,而是给每个线程一个这样的资源副本,让他们可以独立都各自跑各自的,这样不是可以大幅度的提高并行度和性能了吗?
还有的情况是有的数据本身不是线程安全的,或者说它只能被一个线程使用,不能被其他线程同时使用。如果等一个线程使用完了再给另外一个线程使用就根本不现实。这样的情况下,我们也可以考虑用ThreadLocal。一个典型的情况就是我们连接数据库的时候通常会用到连接池。而对数据库的连接不能有多个线程共享访问。这个时候就需要使用ThreadLocal了。在比较熟悉的两个框架中,Struts2和Hibernate均有采用ThreadLocal变量,而且对整个框架来说是非常核心的一部分。
Struts2和Struts1的一个重要升级就是对request,response两个对象的解耦,Struts2的Action方法中不再需要传递request,response参数。但是Struts2不通过方法直接传入request,response对象,那么这两个值是如何传递的呢?
Struts2采用的正是ThreadLocal变量。在每次接收到请求时,Struts2在调用拦截器和action前,通过将request,response对象放入ActionContext实例中,而ActionContext实例是作为”线程局部变量”存入ThreadLocal actionContext中。
public class ActionContext implements Serializable { static ThreadLocal actionContext = new ThreadLocal(); . . . 由于actionContext是”线程局部变量”,这样我们通过ServletActionContext.getRequest()即可获得本线程的request对象,而且在本地线程的任意类中,均可通过该方法获取”线程局部变量”,而无需值传递,这样Action类既可以成为一个simple类,无需继承struts2的任意父类。
在利用Hibernate开发DAO模块时,我们和Session打的交道最多,所以如何合理的管理Session,避免Session的频繁创建和销毁,对于提高系统的性能来说是非常重要的。一般常用的Hibernate工厂类,都会通过ThreadLocal来保存线程的session,这样我们在同一个线程中的处理,工厂类的getSession()方法,即可以多次获取同一个Session进行操作,closeSession方法可在不传入参数的情况下,正确关闭session。
Hiberante的Session 工具类HibernateUtil,这个类是Hibernate官方文档中HibernateUtil类,用于session管理。如下:
public class HibernateUtil { private static Log log = LogFactory.getLog(HibernateUtil.class); private static final SessionFactory sessionFactory; //定义SessionFactory static { try { // 通过默认配置文件hibernate.cfg.xml创建SessionFactory sessionFactory = new Configuration().configure().buildSessionFactory(); } catch (Throwable ex) { log.error("初始化SessionFactory失败!", ex); throw new ExceptionInInitializerError(ex); } } //创建线程局部变量session,用来保存Hibernate的Session public static final ThreadLocal session = new ThreadLocal(); /** * 获取当前线程中的Session * @return Session * @throws HibernateException */ public static Session currentSession() throws HibernateException { Session s = (Session) session.get(); // 如果Session还没有打开,则新开一个Session if (s == null) { s = sessionFactory.openSession(); session.set(s); //将新开的Session保存到线程局部变量中 } return s; } public static void closeSession() throws HibernateException { //获取线程局部变量,并强制转换为Session类型 Session s = (Session) session.get(); session.set(null); if (s != null) s.close(); } } 在这个类中,由于没有重写ThreadLocal的initialValue()方法,则首次创建线程局部变量session其初始值为null,第一次调用currentSession()的时候,线程局部变量的get()方法也为null。因此,对session做了判断,如果为null,则新开一个Session,并保存到线程局部变量session中,这一步非常的关键,这也是“public static final ThreadLocal session = new ThreadLocal()”所创建对象session能强制转换为Hibernate Session对象的原因。
可以看到在getSession()方法中,首先判断当前线程中有没有放进去session,如果还没有,那么通过sessionFactory().openSession()来创建一个session,再将session set到线程中,实际是放到当前线程的ThreadLocalMap这个map中,这时,对于这个session的唯一引用就是当前线程中的那个ThreadLocalMap,而threadSession作为这个值的key,要取得这个session可以通过threadSession.get()来得到,里面执行的操作实际是先取得当前线程中的ThreadLocalMap,然后将threadSession作为key将对应的值取出。这个session相当于线程的私有变量,而不是public的。
显然,其他线程中是取不到这个session的,他们也只能取到自己的ThreadLocalMap中的东西。要是session是多个线程共享使用的,那还不乱套了。
试想如果不用ThreadLocal怎么来实现呢?可能就要在action中创建session,然后把session一个个传到service和dao中,这可够麻烦的。或者可以自己定义一个静态的map,将当前thread作为key,创建的session作为值,put到map中,应该也行,这也是一般人的想法,但事实上,ThreadLocal的实现刚好相反,它是在每个线程中有一个map,而将ThreadLocal实例作为key,这样每个map中的项数很少,而且当线程销毁时相应的东西也一起销毁了,不知道除了这些还有什么其他的好处。
典型使用方式
// 摘自 j.u.c.ThreadLocalRandom private static final ThreadLocal<ThreadLocalRandom> localRandom = // ThreadLocal对象都是static的,全局共享 new ThreadLocal<ThreadLocalRandom>() { // 初始值 protected ThreadLocalRandom initialValue() { return new ThreadLocalRandom(); } }; localRandom.get(); // 拿当前线程对应的对象 localRandom.put(...); // put ThreadLocal产生的问题
在WEB服务器环境下,由于Tomcat,weblogic等服务器有一个线程池的概念,即接收到一个请求后,直接从线程池中取得线程处理请求;请求响应完成后,这个线程本身是不会结束,而是进入线程池,这样可以减少创建线程、启动线程的系统开销。
由于Tomcat线程池的原因,我最初使用的”线程局部变量”保存的值,在下一次请求依然存在(同一个线程处理),这样每次请求都是在本线程中取值而不是去memCache中取值,如果memCache中的数据发生变化,也无法及时更新。
解决方案:处理完成后主动调用该业务treadLocal的remove()方法,将”线程局部变量”清空,避免本线程下次处理的时候依然存在旧数据。
Sturts2是如何解决线程池的问题呢?由于web服务器的线程是多次使用的,很显然Struts2在响应完成后,会主动的清除“线程局部变量”中的ActionContext值,在struts2的org.apache.struts2.dispatcher.ng.filter.StrutsPrepareAndExecuteFilter类中,有这样的代码片段:
finally { prepare.cleanupRequest(request); } 而cleanupRequest方法中有如下代码:
public void cleanupRequest(HttpServletRequest request) { ……//省略部分代码 ActionContext.setContext(null); Dispatcher.setInstance(null); } 由此可见,Sturts2在处理完成后,会主动清空”线程局部变量”ActionContext,来达到释放系统资源的目的。
ThreadLocal总结
ThreadLocal使用场合主要解决多线程中数据数据因并发产生不一致问题。ThreadLocal为每个线程的中并发访问的数据提供一个副本,通过访问副本来运行业务,这样的结果是耗费了内存,单大大减少了线程同步所带来性能消耗,也减少了线程并发控制的复杂度。
ThreadLocal不能使用原子类型,只能使用Object类型。ThreadLocal的使用比synchronized要简单得多。
ThreadLocal和Synchonized都用于解决多线程并发访问。但是ThreadLocal与synchronized有本质的区别。synchronized是利用锁的机制,使变量或代码块在某一时该只能被一个线程访问。而ThreadLocal为每一个线程都提供了变量的副本,使得每个线程在某一时间访问到的并不是同一个对象,这样就隔离了多个线程对数据的数据共享。而Synchronized却正好相反,它用于在多个线程间通信时能够获得数据共享。
Synchronized用于线程间的数据共享,而ThreadLocal则用于线程间的数据隔离。
当然ThreadLocal并不能替代synchronized,它们处理不同的问题域。Synchronized用于实现同步机制,比ThreadLocal更加复杂。
总之,ThreadLocal不是用来解决对象共享访问问题的,而主要是提供了保持对象的方法和避免参数传递的方便的对象访问方式。归纳了两点:
- 每个线程中都有一个自己的ThreadLocalMap类对象,可以将线程自己的对象保持到其中,各管各的,线程可以正确的访问到自己的对象。
- 将一个共用的ThreadLocal静态实例作为key,将不同对象的引用保存到不同线程的ThreadLocalMap中,然后在线程执行的各处通过这个静态ThreadLocal实例的get()方法取得自己线程保存的那个对象,避免了将这个对象作为参数传递的麻烦。
ThreadLocal建议
- ThreadLocal应定义为静态成员变量。
- 能通过传值传递的参数,不要通过ThreadLocal存储,以免造成ThreadLocal的滥用。
- 在线程池的情况下,在ThreadLocal业务周期处理完成时,最好显式的调用remove()方法,清空”线程局部变量”中的值。
- 正常情况下使用ThreadLocal不会造成内存溢出,弱引用的只是threadLocal,保存的值依然是强引用的,如果threadLocal依然被其他对象强引用,”线程局部变量”是无法回收的。
正文到此结束
- 本文标签: 数据 空间 value build Atom tab tar UI 注释 key 详细分析 线程池 源码 配置 时间 XML 同步 python 服务器 https map 代码 Collections 总结 ACE web struct 多线程 实例 final 生命 apache ip 安全 API DOM 锁 删除 update tomcat cat 管理 HTML 开发 http java servlet 线程 IDE CTO 参数 src mina 数据库
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

