数据库的设计:深入理解 Realm 的多线程处理机制
你已经阅读过 Realm 关于线程的基础知识 。你已经知道了在处理多线程的时候你不需要关心太多东西了,因为强大的 Realm 会帮你处理好这些,但是你还是很想知道更多细节……
你想知道在 Realm 的引擎盖下它到底是怎么工作的。你想学习些相关的理论、机制和背后的原因。好吧,你来到正确的地方了。 我们马上会讲到相关的所有有趣的细节。在这篇博文里,我们会解释 Realm 是如何还有为什么是这样构建的,以及它重要的原因。
让我们开始吧:
“复杂性是你的敌人。任何傻瓜都可以做出复杂的东西。简化才是最困难的。”- Richard Branson 先生
这句名言非常重要,它展示了我们全力想传达的福音。我们处理好了许多非常复杂的任务,然后让开发者感到容易起来 - 线程,并发,数据一致性,还有更多,所有这一切想做好都是非常困难的。我们不是怪人,没有成千上百次的尝试和错误,我们也想不出解决并发的方法,那时我们常常也犯下非常低级的错误。Realm 的目标就是要为你解决这些问题。
Realm 的基石
Realm 是一个 MVCC 数据库 ,开始是用 C++ 编写的。MVCC 指的是多版本并发控制。
这没有它听起来那么复杂,相信我们。先停一下,你马上就会豁然开朗的。 :bulb:
MVCC 解决了一个重要的并发问题:在所有的数据库中都有这样的时候,当有人正在写数据库的时候有人又想读取数据库了(例如,不同的线程可以同时读取或者写入同一个数据库)。这会导致数据的不一致性 - 可能当你读取记录的时候一个写操作才部分结束。如果数据库允许这种事情发生,你就会得到和最终数据库里的数据不一致的数据。
这太糟糕了。
这个时候,你的视图中的数据和你的数据库里的数据是不一样的。哎呀,数据不一致了,而且不可靠。
你希望你的数据库是 ACID 的:
- 原子性
- 一致性
- 隔离性
- 持久性
有很多的办法可以解决读、写并发的问题,最常见的就是给数据库加锁。在之前的情况下,我们在写数据的时候就会加上一个锁。在写操作完成之前,所有的读操作都会被阻塞。这就是众所周知的读-写锁。这常常都会很慢。
这是 Realm 的 MVCC 设计决定能大显身手的地方。
Realm 是一个 MVCC 数据库
类似 Realm 的 MVCC 的数据库采用了另外的一个方法:每一个连接的线程都会有数据在一个特定时刻的快照。
这到底意味着什么?
MVCC 在设计上采用了和 Git 一样的源文件管理算法。你可以把 Realm 的内部想象成一个 Git,它也有分支和原子化的提交操作。这意味着你可能工作在许多分支上(数据库的版本),但是你却没有一个完整的数据拷贝。Realm 和真正的 MVCC 数据库还是有些不同的。一个像 Git 的真正的 MVCC 数据库,你可以有成为版本树上 HEAD 的多个候选者。而 Realm 在某个时刻只有一个写操作,而且总是操作最新的版本 - 它不可以在老的版本上工作。
更进一步,Realm 更像一个庞大的树形数据结构(准确的说是一个 B 树),任何时候,你都有最上层的节点,如下 R 节点(和 Git 的 HEAD 提交类似)。
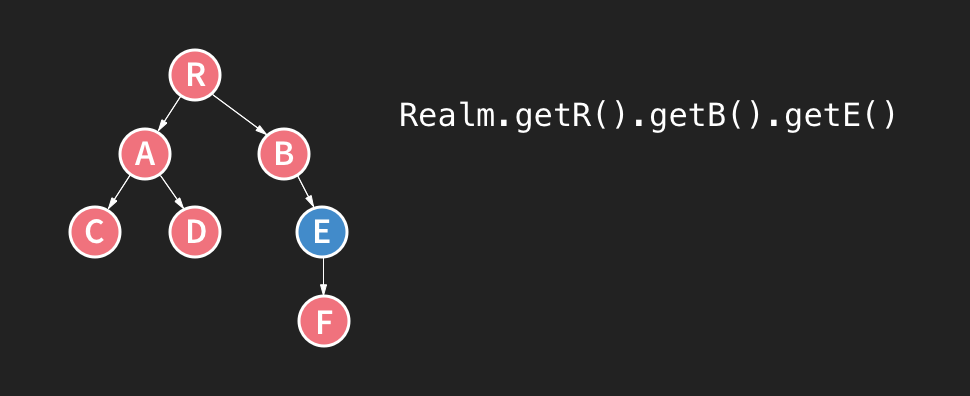
一旦你要提交改变,copy-on-write 才会发生。Copy-on-write 意味着你重新创建了树的另一个分支,然后在不改变现有数据的情况下完成写操作。
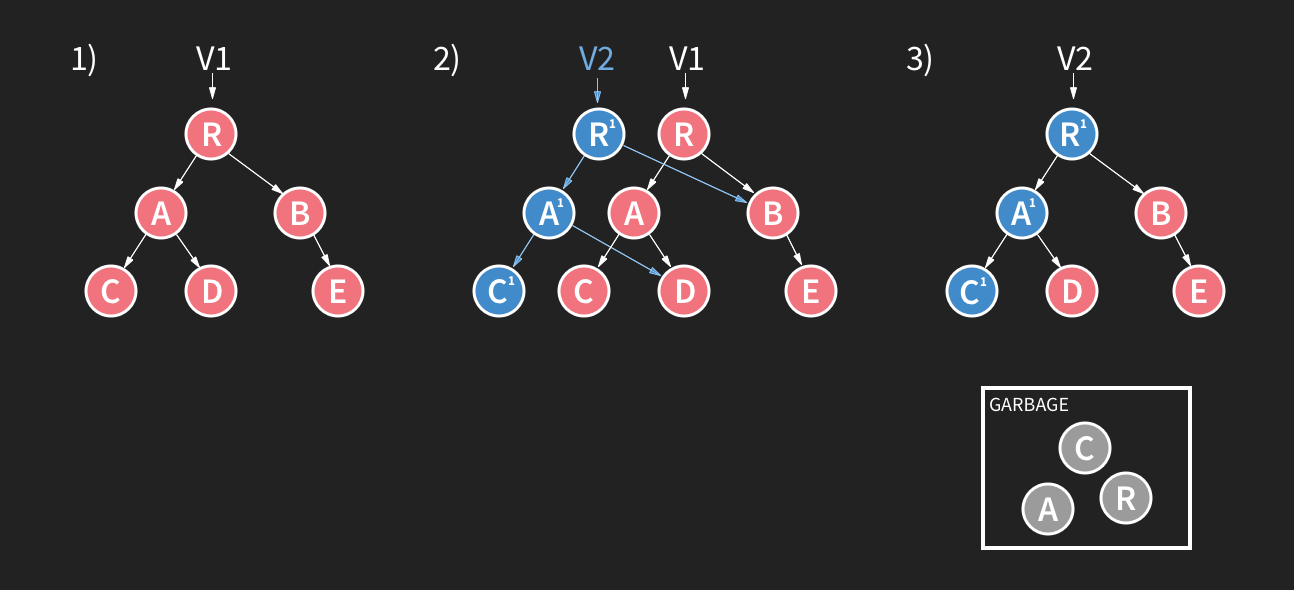
采用这种方法,如果在写事务过程中发生了错误的话,原始数据是不受影响的,顶指针依旧指向没有被损坏的数据,因为你是在别处做的写操作。Realm 采用了两阶段提交来验证写操作,Realm 会验证所有写到磁盘中的内容,这样数据才是安全的。只有在这个时候,Realm 的指针才会移动而且说,“好的,这是新的官方的版本。” 这意味着在一次写事件中最坏的情况是你仅仅失去你更新的数据,而不是整个 Realm 数据库。
Realm 对象和对象关系
另一个关于 Realm 有趣的事情是对象间的关系是本地引用,而且因为 Realm 采用了 zero-copy 架构,这样几乎就没有内存开销。这是因为每一个 Realm 对象直接通过一个本地 long 指针和底层数据库对应,这个指针是数据库中数据的钩子。
Realm 避免了大部分不必要的缓慢的位交换和内存拷贝,这些在传统数据库访问技术中是必要的。
为什么这很重要?
原因就是这样最简单。没有必要为获得引用的对象而作额外的工作。引用的对象是第一等的公民。这对性能影响很大:不需要进行额外的查询或者开销很大的连接操作。
而且,所有的移动设备都是内存受限的。Realm 内存消耗小,这会帮助你的应用避免内存不够的情况和其他内存受限的问题。
解释零拷贝,和为什么它会这么快
Realm 采用了 零拷贝 架构。为了理解零拷贝的威力和它的重要性,让我们快速回顾一下传统数据库的 ORM(关系型对象映射)中数据是如何获取的。
从 ORM、Core Data 中获取对象的传统方法
大部分的时候,你都把数据存在磁盘上的数据库文件中。开发者发起一个从持久化机制(比如 ORM 或者 Core Data)中获取数据的请求,数据格式会是和本地平台密切相关的(比如 安卓或者苹果)。这个时候,持久化机制会把请求转换成一系列的 SQL 语句,创建一个数据库连接(如果没有创建的话),发送到磁盘上,执行查询,读取命中查询的每一行的数据,然后存到内存里(这里有内存消耗)。之后你需要把数据序列化成可在内存里面存储的格式,这意味着比特对齐,这样 CPU 才能处理它们。最后,数据需要转换成语言层面的类型,然后它会以对象的形式返回,这样平台才能用(POJO, NSManagedObject 等等)来处理它。如果你在你的持续化机制中有子引用或者列表引用的话,这个过程会更复杂。这个过程会一遍一遍的执行(取决于你的持续化机制和配置)。如果你使用自产自销的机制,情况也大致相同。
正如你能了解的那样, 有许多事情需要做 是为了把数据变成你的应用中能够使用的数据结构。
Realm 对象获取
Realm 的方法不一样。这就是我们零拷贝架构起作用的地方。
Realm 跳过了整个拷贝过程,因为数据库文件是 memory-mapped。Realm 在访问文件偏移的时候就好像文件已经在内存中一样,实际上不是 - 是虚拟内存。这是个 Realm 核心文件格式的重要设计决定。它允许文件能在没有做任何反序列化的情况下可以在内存中读取。Realm 跳过了所有这些开销很大的步骤,而这些步骤在传统的持久化机制中必须执行。Realm 只需要简单地计算偏移来找到文件中的数据,然后从原始访问点返回数据结构(POJO/ NSManagedObject /等等)的值 。这更有效而且更快。
Realm 中的对象关系也特别的快,因为它们是相关对象的一个类 B 树的数据结构的索引。这比查询快多了。正因为如此,没有必要再进行一次像 ORM 做的全查询了。它是个简单的指向相关对象的本地指针。这就是所有要做的事情了。
自动更新对象和查询
零拷贝架构不仅仅提供了速度。Realm 对象和 Realm 查询对象是活着的,底层数据改变了视图会自动更新,这意味着永远不需要重取数据。对象的改变会立马改变查询的结果。
假设如下的代码:
Java
RealmResults<Dog> puppies = realm.where(Dog.class).lessThan("age", 2).findAll(); puppies.size(); // => 0 realm.beginTransaction(); Dog dog = realm.createObject(Dog.class); dog.setAge(1); realm.commitTransaction(); puppies.size(); // => 1 // Change the dog from another query realm.beginTransaction(); Dog theDog = realm.where(Dog.class).equals("age", 1).findFirst(); theDog.setAge(3); realm.commitTransaction(); // Original dog is auto-updated dog.getAge(); // => 3 puppies.size(); // => 0Swift
let puppies = realm.objects(Dog).filter("age < 2") puppies.count // => 0 because no dogs have been added to the Realm yet let myDog = Dog() myDog.name = "Rex" myDog.age = 1 try! realm.write { realm.add(myDog) } puppies.count // => 1 updated in real-time // Access the Dog in a separate query let puppy = realm.objects(Dog).filter("age == 1").first try! realm.write { puppy.age = 3 } // Original Dog object is auto-updated myDog.age // => 3 puppies.count // => 0 一旦 Dog 对象创建了而且提交给了 Realm, puppies 查询结果会自动的用新值更新。如果通过另一个查询改变 dog,原来的 dog 实例也会自动更新。
同样的自动更新的特性在别的线程更新 Realm 数据的时候也会起作用。当对象在别的线程中更新的时候,线程本地对象会几乎实时更新(这意味着如果它们在正在运行的进程中,更新会在下次循环迭代中发生)。而且,你可以通过 Realm#refresh() 操作强制一次数据更新。
所有的 Realm 对象和查询结果实例都是这样。
在运行循环的下次迭代发生时(或者 Realm 的 refresh 方法调用时),Realm 实例会关闭最近的顶指针的访问(最近的 Realm 数据的版本)。
Realm 对象和查询结果的这个属性不仅仅使 Realm 更快,更有效,而且它使得你的代码更简单而且更加具备响应性。例如,如果你的 UI 依赖于一个查询的结果,你可以在一个领域里存储你的 Realm 对象或者 Realm 查询结果,然后你就不需要在每次访问的时候都去确定数据更新了没有了。
你可以订阅 Realm 通知机制来了解 Realm 数据发生改变的时机,意味着你的应用的 UI 需要更新了,但这并不需要重新获取一次你的 Realm 查询结果。这个功能在大部分的 Realm 产品中已实现,包括Java,Objective-C,和Swift, React Native 正在开发中。
当 Realm 数据变化时获取通知
自动更新对象是个非常棒的特性,除非你知道它何时发生并且响应它,否则它就没有那么有用了。谢谢 Realm 已经实现了一个通知机制允许你能在 Realm 数据发生变化的时候做出响应。
假设以下的情况:有一个 UI 线程使用对象来显示一些 UI 值。一个后台线程通过写操作改变了这个对象。几乎是即时的(在运行循环的下个迭代),UI 线程的数据对象被更新了(记住对象可以直接脱离核心数据库工作,因为有零拷贝架构)。
后台线程通过 Realm 的改变监听者发送给 UI 线程一个通知消息说,有一个改变发生了。(这个特性在大部分的 Realm 产品中都已实现,包括Java,Objective-C,和Swift, React Native 正在开发中。)这个时候,UI 线程可以更新视图来显示新的数据了,如下图。

单线程保证安全
常常有人问:
“为什么 Realm 对象不能在线程间传递?”
这是个好问题,而且一个回答是:这是因为隔离性和数据一致性。
因为 Realm 是基于,所有对象是鲜活的而且自动更新。如果 Realm 允许对象可在线程间共享,Realm 会无法确保数据的一致性,因为不同的线程会在不确定的什么时间点同时改变对象的数据。这样数据很快就不一致了。一个线程可能需要写入一个数据而另一个线程也打算读取它,反过来也可能。这很快就会变得有问题了,而且你不能够在相信哪个线程能有正确的数据了。
是的,这可以通过许多方法来解决,一个常用的方法就是锁住对象,存储器和访问器。虽然这能工作,但是锁会变成一个头疼的性能瓶颈。除了性能,锁的其他问题也很明显,因为锁 —— 一个长时间的后台写事务会阻塞 UI 的读事务。如果我们采用锁机制,我们会失去太多的 Realm 可提供的速度优势和数据一致性的保证。
因此,唯一的限制就是 Realm 对象在不同的线程间是不能共享的。如果你需要在另外一个线程中获取同样的数据,你只需要在该线程里面重新查询。或者,更好的方法是,用 Realm 的响应式架构监听变化!记住 - 各个线程的所有对象都是自动更新的 - Realm 会在数据变化时通知你。你只需要对这些变化做出响应就可以了。 :+1:
Realm 和 安卓
因为 Realm 是线程限制的,你需要理解 Realm 是如何和安卓线程环境框架一起工作的。
Realm 和 安卓线程框架
当处理 Realm 和安卓后台线程的时候,你需要确保你在这些线程里打开和关闭了 Realm。请看文档的安卓 Realm 编程 部分来了解最佳实践。
当 Realm 和安卓主线程一起工作的时候,我们建议你使用Async API 来保证你不会遇到 ANR(应用不响应)的错误。
如果我在主线程里使用了 Realm?它会正常工作吗?
一些操作在主线程里工作得很好,一些不行。现在问题变成……
什么时候在主线程里运行 Realm 工作不正常?
这里事情变得有些模糊了。有很多因素。避免去理解什么时候主线程里面的操作能成功什么时候不能成功,你需要遵循一些在安卓主线程里使用 Realm 的常见的规则:
使用 Realm 的异步 API。
使用 Realm 的异步 API 来查询和提交事务
最近 支持异步查询和事务的版本已发布。它采用一个非常简单的模式,你能够非常容易地实现异步操作。
Realm 的异步查询
你已经理解了内部的线程模型,异步查询就非常容易理解了。
Realms 查询方法会有前缀 Async() (例如, findAllAsync() ),然后你会立马得到 RealmResults 或者一个 RealmObject 。这些方法保证(和 Java Future 的概念很像)在一个后台线程里执行。当查询结束的时候,返回的对象会用查询的结果更新。
下面是一个异步查询的例子:
private Dog firstDog; private RealmChangeListener dogListener = new RealmChangeListener() { @Override public void onChange() { // called once the query complete and on every update // you can use the result now! Log.d("Realm", "Woohoo! Found the dog or it got updated!"); } }; 你的应用的其他地方还有如下的代码(这个例子是 onCreate )。
firstDog = realm.where(Dog.class).equalTo("age", 1).findFirstAsync(); firstDog.addChangeListener(dogListener); 你也需要在 onPause() 方法里加入如下代码:
firstDog.removeChangeListener(dogListener); 在 onCreate() 里, findFirstAsync() 方法会被调用。
调用 findFirstAsync() 会首先在 RealmResults 里返回一个 RealmObject。这个方法立即返回; firstDog 不会有任何数据直到查询完成为止。我给 firstDog RealmObject 增加了一个监听者,来获得操作完成的通知。这个监听者和其他的监听者没有什么不同 - 我需要维护一个它的引用,然后晚点我会删除它,我在 onPause() 方法里这样做了。
任何时候你想看看你的 RealmObject 或者 RealmResults 更新了没有,你可以使用 isLoaded() 方法,例如 firstDog.isLoaded() 。
非安卓循环线程警告:异步查询需要使用 Realm 的 Handler 来保证结果的一致性。尝试使用没有循环的线程内的 Realm 对象来调用异步查询会抛出 IllegalStateException 。
用异步事务给 Realm 写数据
异步写 Realm 是新的异步事务带来的特性。异步事务支持和当前 executeTransaction 一样的方法,但是它使得你能在后台线程里打开 Realm 而不是在同一个线程里打开它。你可以注册一个回调函数,如果你需要在事务结束或者失败的时候收到通知的话。
实现异步事务非常简单:
realm.executeTransactionAsync(new Realm.Transaction() { @Override public void execute(Realm realm) { Dog dog = realm.where(Dog.class).equalTo("age", 1).findFirst(); dog.setName("Fido"); } }, new Realm.Transaction.OnSuccess() { @Override public void onSuccess() { Log.d("REALM", "All done updating."); Log.d("BG", t.getName()); } }, new Realm.Transaction.OnError() { @Override public void onError(Throwable error) { // transaction is automatically rolled-back, do any cleanup here } }); 上面代码的最后两个参数, new Realm.Transaction.OnSuccess 和 new Realm.Transaction.OnError 是可选的。回调函数在这里使得开发者能够在事务结束或者出错的时候得到通知。 executeTransactionAsync 方法接收了一个 Realm.Transaction 对象,并且在后台线程中执行。
重载 execute 函数然后在这个线程里面执行你的事务性工作 - 这是在后台线程里面执行的代码。 execute 函数提供了一个可工作的 Realm。这个 Realm 对象是通过 executeTranscationAsync 方法创建的而且是后台线程的 Realm。简单使用这个 Realm 对象就可以找到或者更新你感兴趣的条目(这个例子里是 dog),然后就这样了! executeTransactionAsync 方法在后台线程调用 beginTransaction 和 commitTransaction ,这样你就不需要自己再做一次了。
一旦操作完成了, Transaction.OnSuccess 方法的 onSuccess 方法会被执行。如果有错误发生,异常会被传到 onError 方法,然后你再处理。你需要注意的是如果 onError 方法被调用了,Realm 事务会因为错误而回滚。
最后,Realm 持有一个对 Transaction 的强引用。如果你因为某种原因要取消事务(Activity 或者 Fragment 的停止),简单地分配一个结果给事务实例,然后在别处取消它。
RealmAsyncTask transaction = realm.executeTransactionAsync(...); ... // cancel this transaction. eg - in onStop(), etc if (transaction != null) { transaction.cancel(); }Realm 的 异步事务支持也需要 Realm 的 Handler 来处理回调(如果你用的话)。如果你在一个非循环的线程里通过打开的 Realm 启动了一个异步写操作的话,你不会得到通知的。
* 每件事情都有例外。你可以用 System.nanotime 来标的你的代码,如果你感到你需要加速的话。请注意,给 Java 找基准是件非常复杂的话题,因为你的 VM 会随机地停顿来做垃圾回收,所以请使用 System.nanotime 作为基本的标准。
易磨合。轻上层。优点多多。
Realm 是用来帮助你日常开发的。
我们开发 Realm 是为了是你的持续化层开发更容易,更有趣。我们力求解决数据一致性,性能和多线程上的一些非常困难的问题。你唯一需要注意的事情就是不要在线程间传递对象。这就是全部!
如果这就是你所需要做的所有的事情,来保证数据一致性,而且还可以获得性能好处和 Realm 响应式编程架构……那么……这不再是个糟糕的博弈了 :relaxed:
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

