JVM GC调优一则–增大Eden Space提高性能
缘起
线上有Tomcat升级到7.0.52版,然后有应用的JVM FullGC变频繁,在高峰期socket连接数,Cpu使用率都暴增。
思路是Tomcat本身的代码应该是没有问题的,有问题的可能是应用代码升级,或者环境改变了,总之Tomcat的优先级排在最后。
先把应用的heap dump下来分析下:
jmap -dump:format=b,file=path pid
用IBM的Heap Analyser分析,发现dubbo rpc调用的RpcInvocation对象和taglibs的SimpleForEachIterator对象占用了很大部分内存。

正常来说,这两种类型的对象都应该可以很快被回收掉,怎么会占用了那么大的内存空间?是不是有别的对象引用了它们,导致不能释放?
再仔细分析,发现RpcInvocation对象都是root refer的,也就是根对象,正常来说根对象应该可以很快就被回收掉的,为什么在内存中会有那么多对象?
再查看应用的JVM参数:
-Xms2g -Xmx2g -Xmn256m -XX:SurvivorRatio=8 -XX:ParallelGCThreads=8 -XX:PermSize=512m -XX:MaxPermSize=512m -Xss256k -XX:-DisableExplicitGC -XX:+UseCompressedOops -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled
首先发现应用的新生代,即-Xmn256m 设置得太小了。对照上面RpcInvocation对象占用了226M,SimpleForEachIterator占用了267M内存。
显然在新生代里,没办法放下那么多的对象,这些对象必然是被放到老生代(old space)里去了。
既然RpcInvocation对象和SimpleForEachIterator对象应该都是可以很快被回收了,那么思路变成,触发一下线上的FullGC,看下对象有没有被回收。
在触发之前,先用jmap -histo pid统计下对象的数量:
34: 136762 4376384 com.alibaba.dubbo.rpc.RpcInvocation
129: 16345 392280 org.apache.taglibs.standard.tag.common.core.ForEachSupport$SimpleForEachIterator
用 jmap -histo:live <pid> 触发Full GC之后:
294: 625 20000 com.alibaba.dubbo.rpc.RpcInvocation
495: 292 7008 org.apache.taglibs.standard.tag.common.core.ForEachSupport$SimpleForEachIterator
果然数量大大的减少了。
所以结论比较明显了, 新生代(Young generation)的空间太小,导致有一些本应该可以很快就被回收的对象被放到了老生代(Old generation)里,导致老生代上涨很快,频繁Full GC。
于是想办法增加新生代的大小,把JVM参数改为:
-Xms2g -Xmx2g -XX:ParallelGCThreads=8 -XX:PermSize=256m -XX:MaxPermSize=512m -Xss256k -XX:-DisableExplicitGC -XX:+UseCompressedOops -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled
因为观察到PermSize实际上只用了不到200M,没有必要设置为512M,浪费内存,所以改为 -XX:PermSize=256m -XX:MaxPermSize=512m 。
另外,把新生代最大限制-Xmn256m 去掉。因为默认的NewRatio = 2,即除了PermSize,新生代大约占内存的1/3,即约(2048 – 256) /3 = 597M。和原来相比增大了一倍不止。
修改上线之后,观察发现Old Space增长缓慢,FullGC次数大大减少,时间在50ms下,Yong GC都在10ms下,达到了想要的效果。
简单的GC过程分析
首先来看一张GC的模型图,很形象:
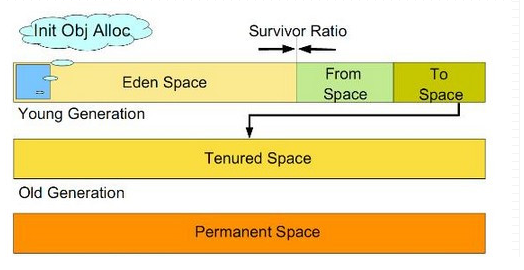
简单来说,对于GC,我们了解到这些信息就足够了。
大部分新对象在Eden Space上分配,当Eden Space满了,则要用到Survivor Space来回收。YGC的算法是很快的。
多次YGC之后,还存活的对象就会被移到Old Generation(old space)上,当Old Generation满了的时候,就会FGC,FGC有通常比较慢。
Permanent Space只要你在开始时分配了足够大的空间,那它可以不用管。
我们可以得出一些结论:
- 合理减少对象进入老生代;
- Old Space可能会一直增长,有时没有办法避免不让对象进入Old Space,当然也有一些程序是从来都不执行FGC的;
- 是不是尽全力防止对象进入老生代?显然不是,有些对象如果长久存在在新生代里,显然加重了YGC的负担,多次YGC之后仍然存活的对象显然应该放到Old Space里。
理想的GC/内存使用情况
总结下来,可以发现,理想的GC情况应该是这样的:
Old Space增长缓慢,FullGC次数少,FullGC的时间短(大部情况应该要在1秒内)。
尽量少加上一些默认参数。这点我很赞同RednaxelaFX的看法,配置了默认参数除了让后面调优的人蛋疼之外,没有太多的帮助。
GC调优就是一个取舍权衡的过程,有得必有失,最好可以在多个不同的实例里,配置不同的参数,然后进行比较。
有很多命令行工具或者图形工具可以使用,好的工具事半功倍。
http://www.alphaworks.ibm.com/tech/heapanalyzer IBM Heap Analyser
http://hllvm.group.iteye.com/group/topic/27945 JVM调优的”标准参数”的各种陷阱, RednaxelaFX 出品,强列推荐
http://www.taobaotesting.com/blogs/2392 Java 性能剖析1——JVM内存管理与垃圾回收
http://www.oschina.net/translate/using-headless-mode-in-java-se 在 Java SE 平台上使用 Headless 模式
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

