元数据驱动设计:创建用户友好的企业级DSL
IT部门与其软件的用户之间已经在不知不觉中形成了一种互惠互利的共生关系,他们的共同努力可以结合在一起,成为一种集体性的工作。在最理想的场景中,软件开发者与架构师能够充分理解,甚至是预测出项目干系人的需求。最终为用户创建出各种实用的应用,通过各种工具发挥客户的价值,并让人们的生活充满了活力。
我们通常会将这些工具设想为某种简单的应用程序,它将帮助我们完成每日的数据维护工作,例如某个提供各种CRUD功能的GUI,或是可以完成某种不相关任务的简单脚本(面向高级用户)。不过,如果我们能够稍微拓展一下想象力的话,其实完全可以为客户创建某些即强大而又不同寻常的东西。
有些时候,我们甚至不需要去想象出某种全新的东西,而只需将一些已经存在多年的东西进行一些简单的转变即可。例如某个业务规则引擎这样常见的技术。
对于那些无法被传统的IT数据管道所理解的内容来说,通常需要经过一系列的步骤,才能够从外部导入生产系统中:
(点击放大图像)

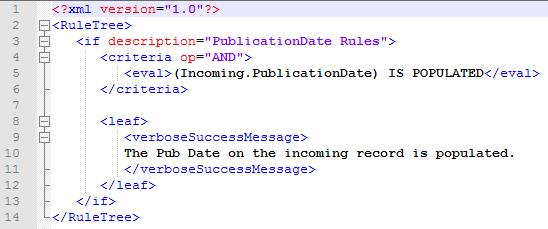
这些具体步骤可以分解为多个流程或是合并为一个流程,不过我们现在只需专注于Record Processor这个模块即可。该模块将对当前记录进行一系列步骤操作,在将其提交给持久化的存储引擎(例如数据库表)之前对其进行校验,或是对数据进行操作。具体来说,我们最感兴趣的是那些将以特定的业务规则处理这部分数据的步骤。举例来说,我们的业务只会保存某种特定类型的产品记录,因此如果某个产品的类型为“Death Star”,就直接拒绝该记录。
对于File Parser这样的模块来说,我们可以创建一个GUI应用,让它将数据文件加载到某个电子表格中,用户可以将某些表格列映射为某个数据结构中的属性。如此一来,用户对于整个管道就有了一定的控制权。但对于其他模块(例如Record Processor)来说,用户对于后端架构的直接控制权非常少,乃至于完全没有。为了对Record Processor进行必要的调整,用户必须像更传统的方式一样为开发者提供规格说明,让开发者直接将调整的内容写在代码中。在这种场景中,强制实施这种业务规则(例如对业务数据进行校验或调整的规则)的功能包的开发过程往往都是痛苦的。
当然,这几十年来,也有一些老派的公司,例如ILLOG和Pegasus Software在规则引擎方面推出了一些实用的、有价值的工具。但是,通过这种方式实现的产品对于那些掌握公司独有数据的实际业务知识的人来说是无法直接使用的,这些工具无法让他们直接操作那些业务规则。
我们能否创建一种语言,让非技术专家也能够轻松掌握,同时又能够保证那些规则在业务领域中的应用?我们能否将一些明显而必要的处理过程进行抽象,让他们能够隐式地应用于语言的表达式中,使该语言只需要对最重要的内容进行明确地表达?我们能否在运行时对该语言的某个片段进行解释与执行,而无需对系统进行重新编译或重新部署?我们能否真的能够为非技术背景的业务人员创建一个可维护的领域特定语言(DSL)吗?正如以下这个简单的示例所表现的一样,对这些问题的回答都是Yes。
(点击放大图像)
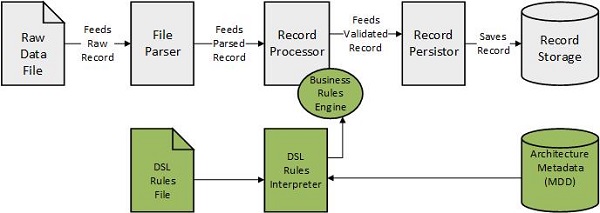
虽然有人认为一般来说不应当将如此重要的一部分功能授权给用户,但每家公司总有一小部分人具有较高的权限(例如超级用户),因为他们掌握了较多的业务知识。如果这些人能够自行维护业务规则,而无需开发者的参与,则他们的生产力将得到提高。为了上他们具备这样的能力,我们可以尝试着为他们传授一些更基础的编程知识,甚至为他们介绍某种流行的脚本语言。
如果你日常的工作平台是基于Java语言的,则可以选择为这些超级用户教授JavaScript,因为Nashorn JavaScript Interpreter已经出现在Java 8 1 上,并将逐渐加深与JDK的集成。因此,让我们暂时确定为超级用户们传授JavaScript的方案,使他们能够自行编写一些业务规则。最终编写的业务规则可能是与以下片段相类似的代码:
function ExecuteBusinessRules(IncomingBookData, CurrentBookData) { var Result = true; var IncPublishedDateString = IncomingBookData.GetData('PublicationDate'); var CurrPublishedDateString = CurrentBookData.GetData('PublicationDate'); if (IncPublishedDateString.length > 0) { var IncPublishedDate = ConvertToJSDate(IncPublishedDateString); if (CurrPublishedDateString.length > 0) { var CurrPublishedDate = ConvertToJSDate(CurrPublishedDateString); if (CurrPublishedDate.getTime() < IncPublishedDate.getTime()) { var tmpDate = new Date(IncPublishedDate); tmpDate.setDate(tmpDate.getDate() - 4); var NewPublishedDateString = CovertToJsString(tmpDate); IncomingBookData.data['PublicationDate'] = NewPublishedDateString; } } } return Result; } 首先,假设上文的图示中所表示的Record Process模块是用Java与Nashorn包所编写的,它即将执行某个特定JavaScript文件中的ExecuteBusinessRules方法。这段JavaScript代码只是对日期进行了简单的调整。ExecuteBusinessRules函数接收两个包含登记数据的JavaScript对象,并比较两者的PublicationDate属性(业务规则引擎本身将负责为该脚本提供IncomingBookData和CurrentBookData数据)。如果输入的日期晚于当前日期,则首先将输入的日期减去4天,再提交至Record Persistor模块。
即便只是为了完成这个简单的任务,我们也必须编写近100行JavaScript代码,包括以上代码段中没有显示的对象(例如IncomingBookData)与函数(例如ConvertToJSDate)的定义。为了进行适当的错误检查,可能还要加入更多的代码。除了需要开发者帮助实现这些通用的库之外,为了实现ExecuteBusinessRules方法体,超级用户还必须熟练掌握JavaScript。
除了代码量过多之外,开发者也没有什么简便的方法能够自动检验超级用户的代码。因此,为了对代码进行调试,他们不得不熟练掌握Firebug等工具。即便如此,也没有什么方法可以检查与系统相关的其他类型的错误(例如把“PublicationDate”这个关键的名称写错了)。而不幸的是,这种方式还可能成为滋生错误的温床,因为超级用户们可能会无意(或有意)创建一些对系统造成灾难性后果的JavaScript代码。总的来说,在干系人选择的这条不寻常的路上,可能会有各种陷阱与苦难等待着他们。
如果我们愿意为超级用户提供真正的主动权,为他们创建一个模拟沙箱,那么我们应当设法创建一种简单而强大的领域特定语言,让它成为业务规则语言的基本语法。因此,我会为该项目选择元数据驱动设计的开发方式。那么,什么是元数据驱动设计(MDD)呢?正如在一篇关于构建MDD架构的文章 2 所描述的一样,MDD是一种基于领域驱动设计方法所构建的设计方法。通过这种设计方法,用户在创建系统(或子系统)时将通过元数据决定数据模型与功能。通过使用无固定形式的数据结构,我们可以创建一个具有可塑性的基础,并在这个基础上构建其他软件层。只需在元数据中加入新的行,就能够对系统进行培训,使其能够理解新的数据以及处理这些数据的方式。
(点击放大图像)
这种类型系统的实现需要在内部包含一个词典,以提供某个领域中的实用术语。在某些情况下,元数据所隐含的功能还可作为某种语法的基元。虽然这种语法非常有趣,但请让我们暂时忽略它。我们现在主要的关注点在于之前所说的词典,它是我们自定义DSL解决方案的基础。
当MDD成为核心的设计方法后,我们就能够克服超级用户在使用JavaScript等脚本语言时所遇到的多种障碍了。由于MDD只是领域驱动设计(DDD)方法的一个渐进的版本,因此我们已经有一个现成的术语表以描述目标系统中的各种数据属性,并且能够利用他们为自定义规则引擎创建一种DSL(在这个特定的用例中,我们并不打算考虑使用这种引擎的某个特定实现细节,例如它是否应当使用Rete算法。而仅仅关注于输入引擎的语言文件,以及对其执行过程的期望)。
如果你还不熟悉DSL背后的思想,建议你去看一看Martin Fowler所做的报告 3 ,他将DSL描述为“为了解决某种特定类型问题的计算机语言的有限的形式”。在这篇影响深远的演讲中,Fowler描述了如何使用XML配置数据作为一种用于Java程序与框架的简单DSL(当然,这种使用XML的方法如今已经广泛用于各种Java框架了,例如Sprint和Struts)。Fowler在演讲中提到了使用这种DSL的多个优点,包括在许多场合下无需重新编译代码,以及对普通的业务用户也具备可用性。
而这些优点正是我们所需要的。由于这种方式不需要进行重新编译,因此非常适合用于MDD的实现,因为MDD的主要目标之一就是尽量少改动代码。其次,我们对于可用性有着强烈的渴望,因为我们的预期目标就是能够方便地编写业务规则(尤其是通过某种简单而对用户友好的工具帮助实现这一点)。如果现代化的Java编程已经大量地使用了这种方法,我们为什么不通过这种策略,为那些掌握了业务知识,却缺乏技术背景的干系人创建一个健壮的解决方案呢?
因此,让我们简单地回顾一下在我的第一篇MDD文章中所提到的内容,尤其是用于描述某个特定系统的数据属性的电子表格:
(点击放大图像)
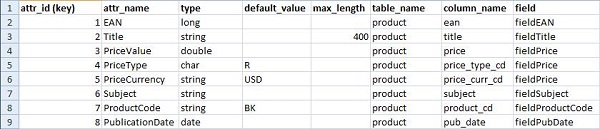
我们可以看到,这段元数据描述了我们的数据属性的各种重要特质。由于这一格式使我们能够通过简单地调整元数据,或是在元数据中加入新的行的方式为系统提供动态功能,因此超级用户们可以通过创建一种简单的DSL的方式暴露这些元数据的强大功能。正如Fowler在他的演讲中讲解的一样,我们可以充分利用XML的内在结构以及多种能够解析这一格式的可用工具。现在,我们已经在元数据中准备好了以XML形式表现的基元词典以及语法,可以尝试实现新语言基础功能的第1个迭代了。我们选择了将上文所述的包含了PublicationDate的JavaScript代码进行移植,作为原型的基础:
(点击放大图像)
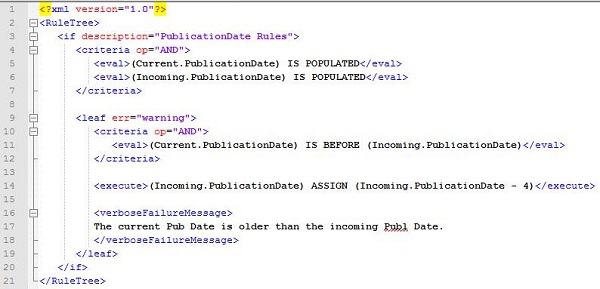
与JavaScript版本的实现相比,这一个XML片段更简短并且更直观,它忽略了在多数语言中所必须包含的各种细节(例如对数据格式进行校验)。当然,这些细节以及RuleTree的执行过程必须在其他部分实现,事实上,他们将作为引擎本身的代码而实现(尽管这个规则引擎及其解释器的实现已不在本文的范围内,但我们稍后仍将对此进简单的介绍)。
与JavaScript版本的示例相似,Business Rules Engine需要暴露一个Java接口,其中定义了一个ExecuteBusinessRules方法。该方法将由Record Process模块进行调用,并提供具体的Current与Imcoming对象。这部分代码将对业务超级用户隐藏,因为他们无需了解(很可能也不关心)这些特性。
除了代码的尺寸减小之外,更重要的一点在于,对那些必须维护与改进这个架构的开发者来说,这种架构也带来了大量的优点。首先,通过使用XML对业务规则进行结构设计,使语法的验证得到了简化,让我们能够放心地交给超级用户进行编辑。如果他们需要帮忙修正某些错误,有许多现成的应用(包括免费与具有专利的应用)可以对XML的结构进行调试,并且修复大多数语法方面的错误。其次,通过使用电子表格中所展示的属性名称,我们就可以将实现的规则引擎与上文所描述的MDD架构进行整合,在对业务规则进行校验与执行时使用其中的元数据。
当然,我们仍然需要创建某种基础的语法分析器以理解各种标记中的表达式,例如<eval>等等,而这些基础表达式(例如“IS BEFORE”)是十分实用的工具,其调用与开发都非常简便。不过,这种方式真正的价值来自于可访问的元数据。正如我们通过XML校验规则的结构一样,我们现在可以通过对上述属性在它的应用上下文中进行检测,以校验及评估各种表达式。
首先,一旦创建了DSL文件之后,我们就可以为进行编辑工作的超级用户创建一些简单的校验工具,以确保某些值以他们特定的类型存在。举例来说,“PublicationDate”属性可以结合使用“IS BEFORE”这个操作符,但如果对“PriceValue”属性使用了相同的操作符,我们的校验工具就会向超级用户发出一条警告信息,表示某个无效操作被应用在“double”类型的属性上。其次,在Business Rules Engine的Java代码中,“IS BEFORE”表达式的代码可适用于对日期进行比较,只需为该操作添加所必须的辅助性代码(例如错误检查)。
以上示例展现了MDD怎样针对实际数据执行简单的业务规则,而如果我们能够将元数据中的更多维度带到DSL中,就能够创建更多的功能。以2015年2月发表的文章中所描述的MDD架构为例,它的设计包含了一个audit层,这一层是由名为Fields的元数据结构所组成的,在Fields中描述了权限与锁的信息。我们可以在项目中加入一些经过认真计划的功能,从而在DSL中编写其他类型的表达式,以对产品数据进行更进一步的评估:
(点击放大图像)
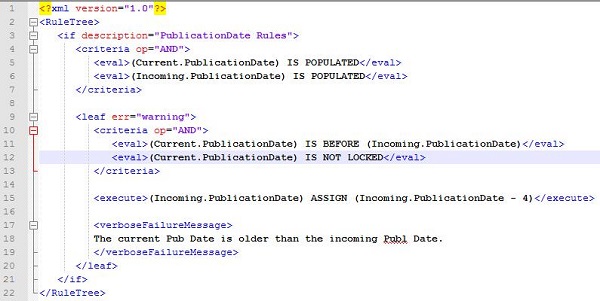
现在,除了对数据本身进行修饰以及操作之外,我们还可以利用附加信息对记录进行操作。正如以上示例所述,我们现在可以评估某个产品的当前PublicationDate是否已锁定(即不允许进行修改)。在这个MDD架构的后续迭代中可以向它的格式元数据中引入更多的维度,而每个新引入的维度都可以包含在DSL中。
那么,我们如何创建这个Business Rules Engine呢?我们必须为此付出巨大的精力吗?其实上,这可能没有你想象的那么糟糕。在这一点上,我们同样不打算过度深入探讨某种现有的实现,但我们将展示它的基本思想。首先,正如本文开头的图中所展示,DSL Rules Interpreter模块需要读取规则文件,并为其内容创建一个有效的表现。在这个示例中,我们需要将所有信息加载到某个RuleTree类中。这个RuleTree将由一系列名为RuleSet的逻辑块所组成,以下代码展示了一个RuleTree的基本定义:
(点击放大图像)

在上述DSL示例中,以该XML片段所生成的RuleTree将包含某个RuleSet的两个实例:其中一个示例的Description对应“PublicationDate Rules”(即<if>标记),而另一个示例对对应其子标记(即<leaf>标记)。如果我们需要一些更复杂的应用,可以以嵌套RuleSet的方式创建层次性的RuleTree。当RuleTree生成之后,需要将其传递至Business Rules Engine,并且对两个业务对象(或是这个用例中的产品记录)应用该RuleTree。Business Rules Engine模块随后将生成一个RuleTreeReport对象,其中包括了执行RuleTree所生成结果的详细信息(其中包括一个状态码,以表示执行成功或是出现了严重错误)。虽然这些简短的步骤只是对必要的工作进行了简单的小结,但重点在于:只需最多几千行Java代码,就可以设计出一个可运行的规则引擎了。
当然,对XML及一些基本的自定义表达式(例如“IS BEFORE”)的结合使用或许只是基于MDD进行DSL设计的第1个迭代的内容。虽然这个主题已经超出了本文的范围,但我们确实能够进一步改进这一架构,为表达式提供标准的实用特性(例如操作符)。要实现这种功能,可以选择一种流行的语言作为我们的基础(JavaScript、Perl、Python等等),为其实现一层额外的功能以结合元数据的使用。我们甚至可以将“IS BEFORE”等操作符进行移植,以元数据的方式将它的执行过程绑定在某个特定的库或是JIT代码块中,让操作符也变成动态的!请尽情发挥你的想象力,只要保证将MDD作为设计的基础,你可以找到各种方式去改进你的DSL。
关于作者
Aaron Kendall是一位居住在纽约的软件工程师,他在企业数据系统的设计与实现方面具有近20年的经验。在Aaron刚刚成为开发者时,他负责设备驱动与专业软件的开发,在那之后,他对于软件设计与架构产生了强烈的兴趣。他在各种平台上以不同语言实现了大量创新业务解决方案,并且参与了多个自由职业软件项目的开发过程,其范围涵盖开源软件、游戏设计以及移动应用。如果你有兴趣了解他的更多工作内容,欢迎你访问他的 LinkedIn 账号,并阅读他的 博客 。
1 Zeigermann, Oliver (2014年4月15日) Nashorn——在JDK 8中融合Java与JavaScript之力 InfoQ
2 Kendall, Aaron (2015年2月19日) 元数据驱动设计——连接设计与开发的敏捷桥梁 InfoQ
3 Fowler, Martin (2006年10月31日)介绍领域特定语言 InfoQ
查看英文原文: Metadata-Driven Design: Creating an User-Friendly Enterprise DSL
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

