DeepID算法实践
作者CSDN张雨石 原文链接: http://blog.csdn.net/stdcoutzyx/article/details/45570221
好久没有写博客了,I have failed my blog. 目前人脸验证算法可以说是DeepID最强,本文使用theano对DeepID进行实现。关于deepid的介绍,可以参见我这一片博文 DeepID之三代 。
当然DeepID最强指的是DeepID和联合贝叶斯两个算法,本文中只实现了DeepID神经网络,并用它作为特征提取器来应用在其他任务上。
本文所用到的代码工程在github上: DeepID_FaceClassify ,如果这篇博客帮到了你,求star。咳咳,为了github工程的star数我觉得我太无耻了,哈哈。
实践流程
环境配置
本工程使用theano库,所以在实验之前,theano环境是必须要配的,theano环境配置可以参见 theano document 。文档已经较为全面,本文不再赘述,在下文中,均假设读者已经装好了theano。
代码概览
本文所用到的代码结构如下:
src/ ├── conv_net │ ├── deepid_class.py │ ├── deepid_generate.py │ ├── layers.py │ ├── load_data.py │ └── sample_optimization.py └── data_prepare ├── vectorize_img.py ├── youtube_data_split.py └── youtube_img_crop.py
正如文件名命名所指出的,代码共分为两个模块,即数据准备模块( data_prepare )和卷积神经网络模块( conv_net )。
数据准备
我觉得DeepID的强大得益于两个因素,卷积神经网络的结构和数据,数据对于DeepID或者说对任何的卷积神经网络都非常重要。
可惜的是,我去找过论文作者要过数据,可是被婉拒。所以在本文的实验中,我使用的数据并非论文中的数据。经过下面的描述你可以知道,如果你还有其他的数据,可以很轻松的用 Python 将其处理为本文DeepID网络的输入数据。
以youtube face数据为例。它的文件夹结构如下所示,包含三级结构,第一是以人为单位,然后每个人有不同的视频,每个视频中采集出多张人脸图像。
youtube_data/ ├── people_folderA │ ├── video_folderA │ │ ├── img1.jpg │ │ ├── img2.jpg │ │ └── imgN.jpg │ └── video_folderB └── people_folderB
拿到youtube face数据以后,需要做如下两件事:
- 对图像进行预处理,原来的youtube face图像中,人脸只占中间很小的一部分,我们对其进行裁剪,使人脸的比例变大。同时,将图像缩放为(47,55)大小。
- 将数据集合划分为训练集和验证集。本文中划分训练集和验证集的方式如下:
- 对于每一个人,将其不同视频下的图像混合在一起
- 随机化
- 选择前5张作为验证集,第6-25张作为训练集。
经过划分后,得到7975张验证集和31900训练集。显然,根据这两个数字你可以算出一共有1595个类(人)。
数据准备的代码使用
注意:数据准备模块中以youtube为前缀的的程序是专门用来处理youtube数据,因为其他数据可能图像属性和文件夹的结构不一样。如果你使用了其他数据,请阅读 youtube_img_crop.py 和 youtube_data_split.py 代码,然后重新写出适合自己数据的代码。数据预处理代码都很简单,相信在我代码的基础上,不需要改太多,就能适应另一种数据了。
youtube_img_crop.py
被用来裁剪图片,youtube face数据中图像上人脸的比例都相当小,本程序用于将图像的边缘裁减掉,然后将图像缩放为47×55(DeepID的输入图像大小)。
Usage: pythonyoutube_img_crop.pyaligned_db_foldernew_folder
- aligned_db_folder: 原始文件夹
- new_folder: 结果文件夹,与原始文件夹的文件夹结构一样,只不过图像是被处理后的图像。
youtube_data_split.py
用来切分数据,将数据分为训练集和验证集。
Usage: pythonyoutube_data_split.pysrc_foldertest_set_filetrain_set_file
- src_folder: 原始文件夹,此处应该为上一步得到的新文件夹
- test_set_file: 验证集图片路径集合文件
- train_set_file: 训练集图片路径集合文件
test_set_file 和 train_set_file 的格式如下,每一行分为两部分,第一部分是图像路径,第二部分是图像的类别标记。
youtube_47_55/Alan_Ball/2/aligned_detect_2.405.jpg,0 youtube_47_55/Alan_Ball/2/aligned_detect_2.844.jpg,0 youtube_47_55/Xiang_Liu/5/aligned_detect_5.1352.jpg,1 youtube_47_55/Xiang_Liu/1/aligned_detect_1.482.jpg,1
vectorize_img.py
用来将图像向量化,每张图像都是47×55的,所以每张图片变成一个47×55×3的向量。
为了避免超大文件的出现,本程序自动将数据切分为小文件,每个小文件中只有1000张图片,即1000×(47×55×3)的矩阵。当然,最后一个小文件不一定是1000张。
Usage: pythonvectorize_img.pytest_set_filetrain_set_filetest_vector_foldertrain_vector_folder
- test_set_file:
*_data_split.py生成的 - train_set_file:
*_ata_split.py生成的 - test_vector_folder: 存储验证集向量文件的文件夹名称
- train_vector_folder: 存储训练集向量文件的文件夹名称
Conv_Net
走完了漫漫前路,终于可以直捣黄龙了。现在是DeepID时间。吼吼哈嘿。
在conv_net模块中,有五个程序文件
- layers.py: 卷积神经网络相关的各种层次的定义,包括逻辑斯底回归层、隐含层、卷积层、max_pooling层等
- load_data.py: 为DeepID载入数据。
- sample_optimization.py: 针对各种层次的一些测试实验。
- deepid_class.py: DeepID主程序
- deepid_generate.py: 根据DeepID训练好的参数,来将隐含层抽取出来
Conv_Net代码使用
deepid_class.py
Usage: pythondeepid_class.pyvec_validvec_trainparams_file
- vec_valid:
vectorize_img.py生成的 - vec_train:
vectorize_img.py生成的 - params_file: 用来存储训练时每次迭代的参数,可以被用来断点续跑,由于CNN程序一般需要较长时间,万一遇到停电啥的,就可以用得上了。自然,更大的用途是保存参数后用来抽取特征。
注意:
DeepID训练过程有太多的参数需要调整,为了程序使用简便,我并没有把这些参数都使用命令行传参。如果你想要改变迭代次数、学习速率、批大小等参数,请在程序的最后一行调用函数里改。
deepid_generate.py
可以使用下面的命令来抽取DeepID的隐含层,即160-d的那一层。
Usage: pythondeepid_generate.pydataset_folderparams_fileresult_folder
- dataset_folder: 可以是训练集向量文件夹或者验证集向量文件夹。
- params_file:
deepid_class.py训练得到 - result_folder: 结果文件夹,其下的文件与dataset_folder中文件的文件名一一对应,但是结果文件夹中的向量的长度变为160而不是原来的7755。
效果展示
DeepID 效果
跑完 deepid_class.py 以后,你可以得到输出如下。输出可以分为两部分,第一部分是每次迭代以及每个小batch的训练集误差,验证集误差等。第二部分是一个汇总,将 epoch train error valid error . 按照统一格式打印了出来。
epoch 15, train_score 0.000444, valid_score 0.066000 epoch 16, minibatch_index 62/63, error 0.000000 epoch 16, train_score 0.000413, valid_score 0.065733 epoch 17, minibatch_index 62/63, error 0.000000 epoch 17, train_score 0.000508, valid_score 0.065333 epoch 18, minibatch_index 62/63, error 0.000000 epoch 18, train_score 0.000413, valid_score 0.070267 epoch 19, minibatch_index 62/63, error 0.000000 epoch 19, train_score 0.000413, valid_score 0.064533 0 0.974349206349 0.962933333333 1 0.890095238095 0.897466666667 2 0.70126984127 0.666666666667 3 0.392031746032 0.520133333333 4 0.187619047619 0.360666666667 5 0.20526984127 0.22 6 0.054380952381 0.171066666667 7 0.0154920634921 0.128 8 0.00650793650794 0.100133333333 9 0.00377777777778 0.0909333333333 10 0.00292063492063 0.086 11 0.0015873015873 0.0792 12 0.00133333333333 0.0754666666667 13 0.00111111111111 0.0714666666667 14 0.000761904761905 0.068 15 0.000444444444444 0.066 16 0.000412698412698 0.0657333333333 17 0.000507936507937 0.0653333333333 18 0.000412698412698 0.0702666666667 19 0.000412698412698 0.0645333333333
上述数据画成折线图如下:
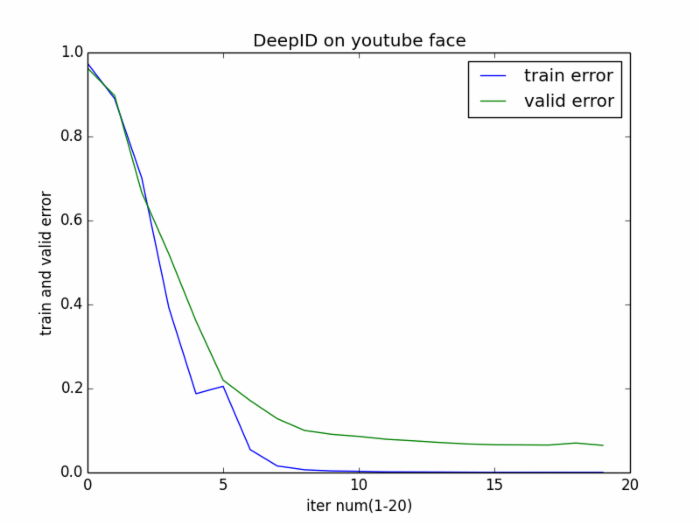
向量抽取效果展示
运行 deepid_generate.py 之后, 可以得到输出如下:
loadingdataofvec_test/0.pkl buildingthemodel ... generating ... writingdatato deepid_test/0.pkl loadingdataofvec_test/3.pkl buildingthemodel ... generating ... writingdatato deepid_test/3.pkl loadingdataofvec_test/1.pkl buildingthemodel ... generating ... writingdatato deepid_test/1.pkl loadingdataofvec_test/7.pkl buildingthemodel ... generating ... writingdatato deepid_test/7.pkl
程序会对向量化文件夹内的每一个文件进行抽取操作,得到对应的160-d向量化文件。
将隐含层抽取出来后,我们可以在一些其他领域上验证该特征的有效性,比如图像检索。可以使用我的另一个github工程进行测试, 这是链接 .使用验证集做查询集,训练集做被查询集,来看一下检索效果如何。
为了做对比,本文在youtube face数据上做了两个人脸检索实验。
- PCA exp. 在
vectorized_img.py生成的数据上,使用PCA将特征降到160-d,然后进行人脸检索实验。 - DeepID exp. 在
deepid_generate.py生成的160-d数据上直接进行人脸检索实验。
注意:在两个实验中,我都使用cosine相似度计算距离,之前做过很多实验,cosine距离比欧式距离要好。
人脸检索结果如下:
- 正确率如下:
| Precision | Top-1 | Top-5 | Top-10 |
|---|---|---|---|
| PCA | 95.20% | 96.75% | 97.22% |
| DeepID | 97.27% | 97.93% | 98.25% |
- 平均正确率如下:
| AP | Top-1 | Top-5 | Top-10 |
|---|---|---|---|
| PCA | 95.20% | 84.19% | 70.66% |
| DeepID | 97.27% | 89.22% | 76.64% |
Precision意味着在top-N结果中只要出现相同类别的人,就算这次查询成功,否则失败。而AP则意味着,在top-N结果中需要统计与查询图片相同类别的图片有多少张,然后除以N,是这次查询的准确率,然后再求平均。
从结果中可以看到,在相同维度下,DeepID在信息的表达上还是要强于PCA的。
参考文献
[1]. Sun Y, Wang X, Tang X. Deep learning face representation from predicting 10,000 classes[C]//Computer Vision and Pattern Recognition (CVPR), 2014 IEEE Conference on. IEEE, 2014: 1891-1898.
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

