Flume 实时收集 Nginx 日志
在分布式系统中,各个机器都有程序运行的本地日志,有时为了分析需求,不得不这些分散的日志汇总需求,相信很多人会选择 Rsync,Scp 之类, 但它们的实时性不强,而且也会带来名字冲突的问题。扩展性差强人意,一点也不优雅。
现实中,我们就碰到了这样的需求:实时汇总线上多台服务器的 Nginx 日志。Flume 立功了。
Flume 简介
F lume 是一个分布式,可靠高效的日志收集系统,它允许用户自定义数据传输模型,因此可扩展性也强。也有较强的容错和恢复机制. 以下是几个重要的概念
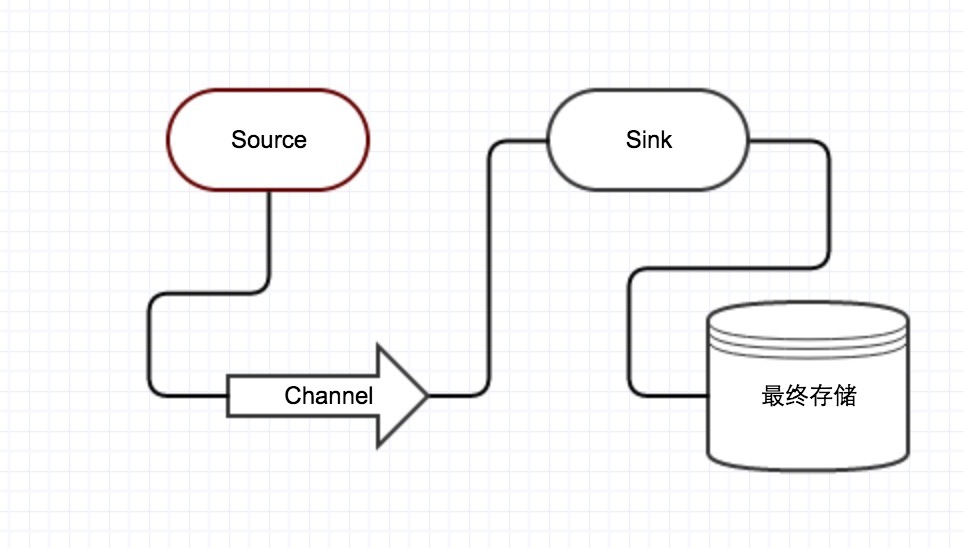
- Event:Event 是 Flume 数据传输的基本单元。flume 以事件的形式将数据从源头传送到最终的目的。
- Agent:Agent包含 Sources, Channels, Sinks 和其他组件,它利用这些组件将events从一个节点传输到另一个节点或最终目的。
- Source:Source负责接收events,并将events批量的放到一个或多个Channels。
- Channel:Channel位于 Source 和 Sink 之间,用于缓存进来的events,当Sink成功的将events发送到下一跳的channel或最终目的,events从Channel移除。
- Sink:Sink 负责将 events 传输到下一跳或最终目的,成功完成后将events从channel移除。
- Source 就有 Syslog Source, Kafka Source,HTTP Source, Exec Source Avro Source 等。
- Sink 有 Kafka Sink, Avro Sink, File Roll Sink, HDFS Sink 等。
- Channel 有 Memory Channel,File Channel 等
它提供了一个骨架,以及多种 Source, Sink, Channel, 让你设计合适的数据模型。事实上也可以多个 Flume 联动完成,就像地铁的车厢一样。
定义数据流模型
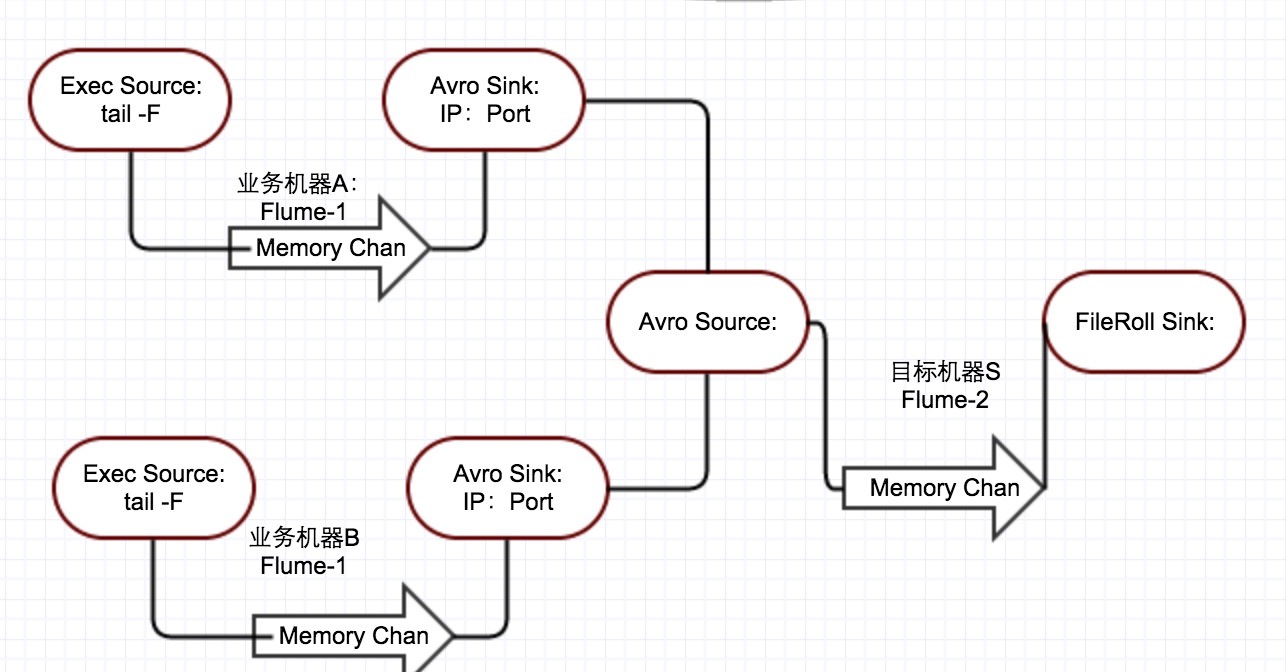
回到我们开头的场景,我们要将多台服务器的 Nginx 日志进行汇总分析,
分成两个 flume 来实现
- Flume1 数据流是 Exec Source -> Memory Channel -> Avro Sink,部署在业务机器上
- Flume2 数据流是 Avro Source -> Memory Channel -> FileRoll Sink
需要的准备
你需要安装
- 下载 Flume
- 安装 JavaSDk,并在下载解压之后的 conf/flume-env.sh,配置
# 我用的是oracle-java-8 export JAVA_HOME=/usr/lib/jvm/java-8-oracle/jre/
- 思考你的数据流动模型,编写配置,如上文所说的Flume1, tail2avro.conf :
agent.sources = s1 agent.channels = c1 agent.sinks = k1 agent.sources.s1.type=exec agent.sources.s1.command=tail -F <Your File Path> agent.sources.s1.channels=c1 agent.channels.c1.type=memory agent.channels.c1.capacity=10000 agent.channels.c1.transactionCapacity=10000 agent.sinks.k1.type = avro agent.sinks.k1.hostname = <Your Target Address> agent.sinks.k1.port = <Your Target Port> agent.sinks.k1.channel=c1
Flume2 中的 avro2file.conf
agent.sources = s1 agent.channels = c1 agent.sinks = k1 agent.sources.s1.type = avro agent.sources.s1.bind = <Your Address> agent.sources.s1.port = <Your Port> agent.sources.s1.channels = c1 agent.sinks.k1.type = file_roll agent.sinks.k1.sink.directory = /data/log/ngxlog # 滚动间隔 agent.sinks.k1.sink.rollInterval = 86400 agent.sinks.k1.channel = c1 agent.channels.c1.type = memory # 队列里 Event 的容量 agent.channels.c1.capacity = 10000 agent.channels.c1.transactionCapacity = 10000 agent.channels.c1.keep-alive = 60
- 启动运行
# 启动flume1 bin/flume-ng agent -n agent -c conf -f conf/tail2avro.conf / -Dflume.root.logger=WARN # 启动flume2 in/flume-ng agent -n agent -c conf -f conf/avro2file.conf / -Dflume.root.logger=INFO
参考
- FlumeUserGuide 官方的 FlumeUserGuide
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

