QCon北京:构建大数据生态需要哪些核心技术?
2016年QCon全球软件开发大会北京站 于4.21-4.23在北京国际会议中心举办,参会者对整体内容设置及安排反馈良好。这里我们梳理出了22号“大数据生态构建”厂商共建专场的重点演讲内容,为没能到现场聆听的小伙伴们奉上饱满的干货内容。 ( 进入 QCon北京2016 大会官网,免费下载三天的讲师演讲PPT。 )
参与大数据技术实践分享的厂商有:通联数据、明略数据、FreeWheel、七牛云、百度开放云、易观和链家网。演讲话题点包含机器学习、数据存储、用户画像、数据查询、数据迁移和数据分析等关键技术点,完整的诠释了构建大数据生态必备的技能和构建生态最终的目的。具体内容往下看!
机器学习 & 金融投资
作为金融投资领域的实践者,通联数据在投研管理业务场景中有较多的经验可以分享,尤其是在信息搜集、分析判断、投资决策和后续跟踪方面,将大数据吸收并用于投资活动的“小数据”。
而完成这一系列动作就需要一个分析能力特别强的平台,平台架构底层聚合多行业的数据,包括财务数据和社交数据等等,但是我们更为关注的是这个投研平台的机器学习技术框架,因为这样一个框架基本上展现出了其技术的组成部分和核心技术点。(如下图)
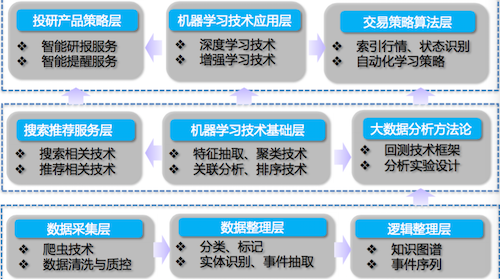
从图上可以简单的看出,平台底层有海量的数据不断积累、不断增长,包括宏观数据、行业的数据、场合数据,官方数据,也包括各种通过爬虫爬来的各种数据。接下来会通过数据生产、数据清洗、数据上线等过程,将这些表面上看似没什么关联的数据通过自然语言处理和算法建立起一个知识图谱和关系。通过设定某些规则来检测不断流动的数据流或者文本流信息,关注不断出现的事件,对带有关键词或带监控的主题进行监控,可以实时监控大事件。通过包括神经网络在内的算法方式,对数据进行建模和归类,把大量的信息进行过滤,过滤成有用的“小数据”。
除此之外,蔡弘博士还提到了通过机器学习向用户推荐准确的新闻资讯;通过智能搜索,对关键词的分词、同义词、精密度和重要度进行数据清洗和建模,完成用户的精准信息搜索需求。
社会化数据 & 混合存储
在讲到社会化数据这一块内容的时候,来自明略数据的任鑫琦解释说,社会化数据的特点就是:收集更困难,质量难保证,数据非结构化,数据处理性能差。所以说,要把这样的社会化数据存储起来是有难度的。接下来看看社会化关系网络的存储架构,基于Hadoop分析框架和流式计算框架形成一整套数据处理框架,主要用于数据查询。
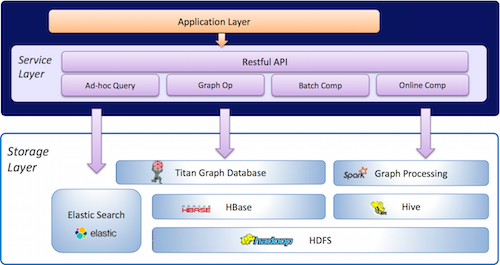
查询完数据该如何存储下来呢?当然是用混合存储体系,(如上图)这个存储实现框架的底层都是基于一些开源的技术,最底层是基于HDFS,数据库存储用的是HBase,数据仓库用的是Hive,图形数据库用的是开源的Titan。之所以用开源的Titan,原因在于其索引分析系统是Elastic Search,除了需要较多的业务应用之外,还有一些批量或者是离线、在线任务的计算,还要提供上层应用的服务层,能提供整体的一个接口。
此外,任老师还讲了一些他所遇到的坑,包括边爆炸问题,Super Node问题,多点查询效率,索引性能和灵活度,导入数据性能等问题。
用户画像 & 标注噪声处理
说起用户画像,这是计算广告领域一个非常经典的问题。FreeWheel的童有军老师在开讲时介绍了用户画像在广告投放平台的重要地位。广告的受众定向和测量都会涉及到用户画像的相关工作。而受众定向则是根据用户画像生成的用户兴趣细分标签对广告进行精准定向。
但是童老师也说到,在用户画像上,缺乏质量较高的标注来源,而FreeWheel选择了一种基于贝叶斯的方法来近似的标注用户。这种方法的基本思路就是通过用户观看过的视频在各个分类上的分布来推测这个用户的类别。对标注集合的噪声处理方法主要是Boosting方法、Bagging方法和半监督方法。Bagging方法中又分别尝试了CV方法和有放回的Bagging方法。
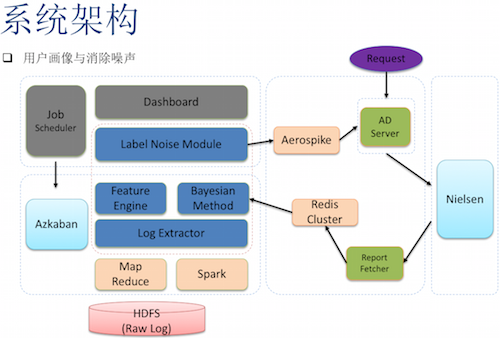
最后,童老师也介绍了用户画像和标注噪声的系统架构,(如上图)从HDFS开始,到MR,SPARK,然后同时做特征工程,和贝叶斯算法。将算出后的数据,dump到server上,做Lable Noise,然后把数据插入到Aerospike中,用来做测试和使用。
百度 & 即席查询
在大数据即席查询技术的演讲中,百度大数据架构师孙垚光分别讲了BigSQL的定位和特点,BigSQL的架构和关键技术、以及在百度内部应用的案例。
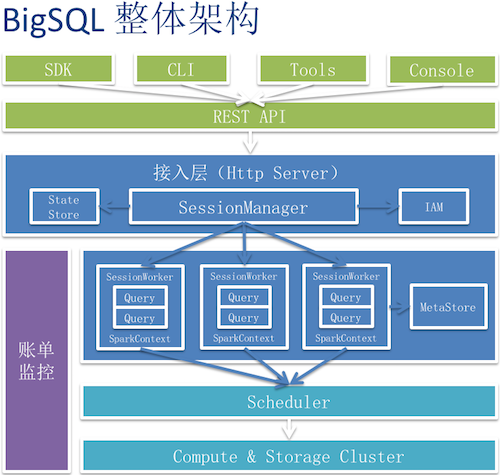
首先BigSQL的定位是一个即席查询服务平台,是PaaS形态的产品,它的特点是支持半结构化数据格式,使用多样化接口,兼容开源SparkSQL/HQL语法集,同时还有灵活的权限管理,支持不同用户之间共享、协同工作。
下图是BigSQL的整体架构图,分成接入层和引擎层两部分,最上面是用户可以接触到的各种API,中间是提供RestAPI的server,还有负责session管理和调度的master,监控job运行的worker等,下面是真正的计算引擎和存储引擎。
接下来简单说一下BigSQL的关键技术:高性能Shuffle。关键技术:高性能Shuffle。(如下图)
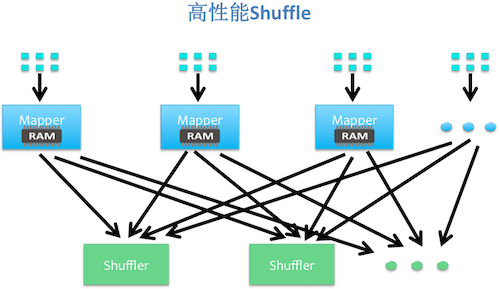
将基于磁盘的pull模式,改变成基于内存的push模式,因为很多复杂的项目对工程质量要求很高,所以这个改变并不容易。它的好处就是数据在map端全内存,到一个专用的Shuffle模块上去聚合,聚合多个map的Shuffle模块,产出的数据极大减少了磁盘IO和随机读,并且对于只需要分组不需要排序的Query,甚至可以做到流式处理,提高了时效性。
在最后的BigSQL后续规划上,孙老师说到,在性能方面还会持续提升,包括存储、计算、Query翻译优化等各个层面的工作,比如更智能/细粒度的数据缓存层,数据的实时更新,向量执行,有效的提高CPU cache命中率,还有利用一些统计信息做cost based Optimizer等等。
大数据分析技术 & 房产领域
最后的一场演讲是来自房产领域的链家网,其大数据架构师蔡白银为大家分享了链家网是如何使用分析技术来价值最大化海量用户数据的。蔡白银在开头就讲到了,现在房产O2O领域存在很多痛点,包括精准数据收集以及辨别虚假信息等方面。
那么链家网是怎么解决这些痛点的呢?结合(下图)大数据方面的技术架构图一起来看一下。
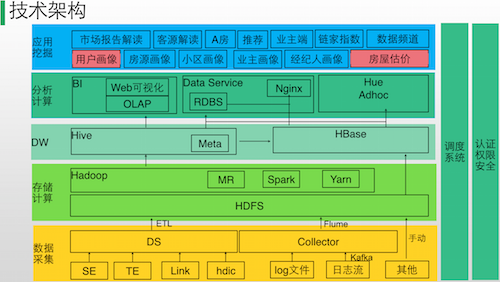
从下往上看,其黄色部分是数据采集层,HDFS是链家网内部业务数据存储层,采集到的数据通过ETL传输到HDFS。同样日志流经过Kafka进入HDFS,基于Yam提供计算的服务,计算完之后放入Hive进行分析,分析结果再存储到Hbase,供其他业务方获取。最上面的一层是应用挖掘层,链家网目前基于这些数据做了比如市场解读报告,后续的市场情况,客源解读等方面的服务提供。
在应用挖掘层,蔡老师挑出两个案例做了进一步解释。用户画像应用主要是对用户画像进行选型,HBase和Spark是整个选型过程中最关键的技术。放入Elastic Search的热数据会被放入磁盘,HBase可以存储线上所有用户数据。在技术选型上,从左到右基于Hive、HDFS,到了Spark,将数据处理完之后会把结果批量放到Elastic Search。另外,通过Kafka传过来的日志流在进入到Spark之后会建立索引,这些索引会全量放入Elastic Search,数据最终会放在HBase。但是为了应对与日剧增的庞大日志量,会把热数据放在Elastic Search,将冷数据移出。
说在最后
大数据之所以能引领一场革命,原因并不在于“大”,而在于“有用”,它能够将数据与现实社会有机融合,能真正意义上产生对社会有价值的变革。这也正应了 业界流传的那句话:三分技术,七分数据,得数据者得天下。大数据公司在争抢数据源的同时,对数据处理的技术也在不断的升级和多功能化。
从全天的演讲内容来看,几乎涵盖了所有对大数据生态构建起作用的关键技术,以技术加实践经验的方式来输出技术干货,确实是一件对大数据技术交流有帮助的事情,整体的将数据分布式处理技术、存储技术、感知技术、数据挖掘等技术统一到一起,建设良性增益的大数据闭环生态,也是所有开发者或架构师等技术人员所关心的问题。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

