Read-Copy Update,向无锁编程进发!
在无锁编程的世界里,ABA问题是一个没有办法回避的实现问题。就看看实现一个最简单的 基于单链表的stack都有这么多的坑 ,就知道无锁编程有多难。 难道我们追求高性能的道路就被这个拦路虎挡住了? No,我们有Read-Copy Update(RCU)这个法宝,帮助我们方便的实现很多的无锁算法数据结构。
本文会首先简略介绍RCU的基本概念,然后通过例子来详细阐述RCU的读写概念,最后简单介绍RCU目前的实现方案。
什么是RCU?
引用一下这篇 著名的RCU科普文 的开头:
Read-copy update (RCU) is a synchronization mechanism that was added to the Linux kernel in October of 2002. RCU achieves scalability improvements by allowing reads to occur concurrently with updates.
首先,RCU是一种同步机制;其次RCU实现了读写的并行;最后,2002开始被Linux kernel所使用。 RCU利用一种Publish-Subscribe的机制,在Writer端增加一定负担,使得Reader端几乎可以 Zero-overhead 。
RCU适合用于同步基于指针实现的数据结构(例如链表,哈希表等),同时由于他的Reader 0 overhead的特性,特别适用用读操作远远大与写操作的场景。例如在Linux内核中的routing模块(与DNS非常相关)则用到来RCU来实现高性能。
一个链表的例子
假设我们有下面这个结构定义:
struct foo { int a; int b; int c; }; struct foo *gp = NULL; 那么在不考虑 gp 这个指针会被改变的情况下,我们可以这样的去进行读操作:
struct foo* p = gp; if (p != NULL) { do_something_with(p->a, p->b, p->c); } 一切看起来都很简单。如果我们现在有一个Writer是像下面这样去改变 gp 呢?
struct foo* p = kmalloc(sizeof(*p), GFP_KERNEL); struct foo* tmp_gp = gp; p->a = 1; p->b = 2; p->c = 3; gp = p; free(tmp_gp); 读者们知道会发生什么吗?
如果在有几个Reader在获取了旧的gp之后,被context switch,然后Writer就把这个旧的 gp (这Writer端是 tmp_gp )删除了。那么后面当Reader再次被调度,就会造成segfault。就也是我们在学习多线程编程里面最基本的race condition,一般来说我们就会对 gp 指针加上mutex或者是rwlock,这样就可以达到互斥的效果。
那么如果是RCU的话,怎么解决呢?
RCU的读写锁
RCU里面,通过一种类似于读写锁的方式来实现互斥,在Reader端,可以用 rcu_read_lock/unlock 来保护:
rcu_read_lock(); p = rcu_dereference(gp); if (p != NULL) { do_something_with(p->a, p->b, p->c); } rcu_read_unlock(); 这里,需要保护的代码会在 read_lock/unlock 之间,和读写锁的读锁用法一致。
而在Writer端,我们会用一个 synchronize_rcu 来等待所有的使用旧的 gp 都结束之后再删除。
q = kmalloc(sizeof(*p), GFP_KERNEL); q->a = 1; q->b = 2; q->c = 3; gp = q; synchronize_rcu(); kfree(p); 因为在 synchronize_rcu 之后,RCU可以保证所有持有旧的gp的读锁都已经结束,所以我们可以放心的删除旧的 gp 。
注意上面的Writer例子里面,只允许同一时间有一个Writer的存在。如果有多个Writer的话,需要修改一下,在这出于简单的考虑,暂不考虑多Writer的情况。
这里最关键的就是 synchronize_rcu 这个函数了,正是它使得RCU能正确的工作。
Grace Period
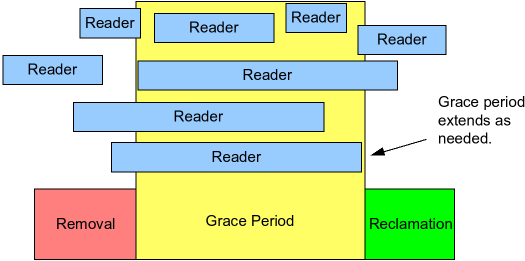
在RCU里面,有两个关键的时间区间,一个就是Reader Lock时间,一个是Grace Period。上面的图可以大概的了解一下这两者之间的关系。
Reader Lock时间顾名思义就是然后Reader在 rcu_read_lock/unlock 之间的时间。而Grace Period的意思是,从Writer开始修改受保护的数据结构开始,到所有的Reader Lock都结束了至少一次的时间段。
假设我们称Grace Period开始的时间点是T:
- 如果一个Reader Lock时间横跨T,则Grace Period必然结束于这个Reader Lock结束之后。
- 如果一个Reader Lock开始于T之后,则Grace Period可能于这个Reader Lock的任意时间结束。也就是可能在Reader Lock开始之前结束,也可能在Reader Lock中间结束,也可能在Reader Lock结束之后才结束。
了解了上面这两个概念之后,我们可以通过简单的证明知道,在Grace Period之后,所有的Reader都不可能获取到在T时间之前的旧数据。所以在Grace Period之后,作为Writer是可以放心的删除旧数据的。
所以上面例子里面Writer的 synchronize_rcu ,实际上就是等待Grace Period的结束。
RCU的实现
目前RCU的实现主要是在Linux kernel里面,但是kernel里面的实现非常依赖于其实现,对于进程调度这块有非常多的假设。 如果我们想要在userspace去用RCU的话,则需要对RCU进行一些拓展。 liburcu就是把RCU搬到了用户态,使得用户态的程序也可以利用上RCU。
我会在下一篇文件详细讲URCU的实现。

本 作品 由airekans创作,采用 知识共享署名-相同方式共享 4.0 国际许可协议 进行许可。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

