每日一搏 | ELK 完整搭建流程(小白速成记)
原 荐 顶 ELK完整搭建流程(小白速成记)
发表于2天前(2016-04-21 22:59) 阅读( 1062 ) | 评论() 0 人收藏此文章,
赞 1
4月23日,武汉源创会火热报名中,期待您的参与>>>>> 
摘要
1、文章的目的:搭建ELK,并能友好的使用 2、解决什么问题:①搭建流程;②中文索引 不分词(not_analyzed)的两种解决方案;③部分窍门 3、解决过程:通过阅读英文文档+中文文档,毕竟这个是灵活的新鲜事物,很多东西需要自己思考然后灵活配置 4、总结:熟悉这套简单流程,ELK基本也就入门了
elk logstash kibana raw supervisor ruby
目录[-]
客官~直接上菜!
首先直接来张思维导图,演示大众化的入门级的ELK搭建流程。(我的mac不能画visio图,各位看官请等我用坑比的Windows画的visio,晚些一定画出来)
First things first, 搭建架构,就如上图咯;
Two, 在每台机器上安装对应的软件
直接去 官网 下载,然后download,然后解压,就可以在bin目录下启动测试了。
需要注意的是,logstash需要在你采集日志的机器上部署,kafka和elasticsearch根据自己的情况来部署,kibana只需要在单台机器上部署就OK(当然如果用户多,而且这台机器挂掉呢。so,最终还是要部署多台,单台部署kibana 只是入门).
Three, 配置logstash,官网的这张图不错,直接盗用过来了
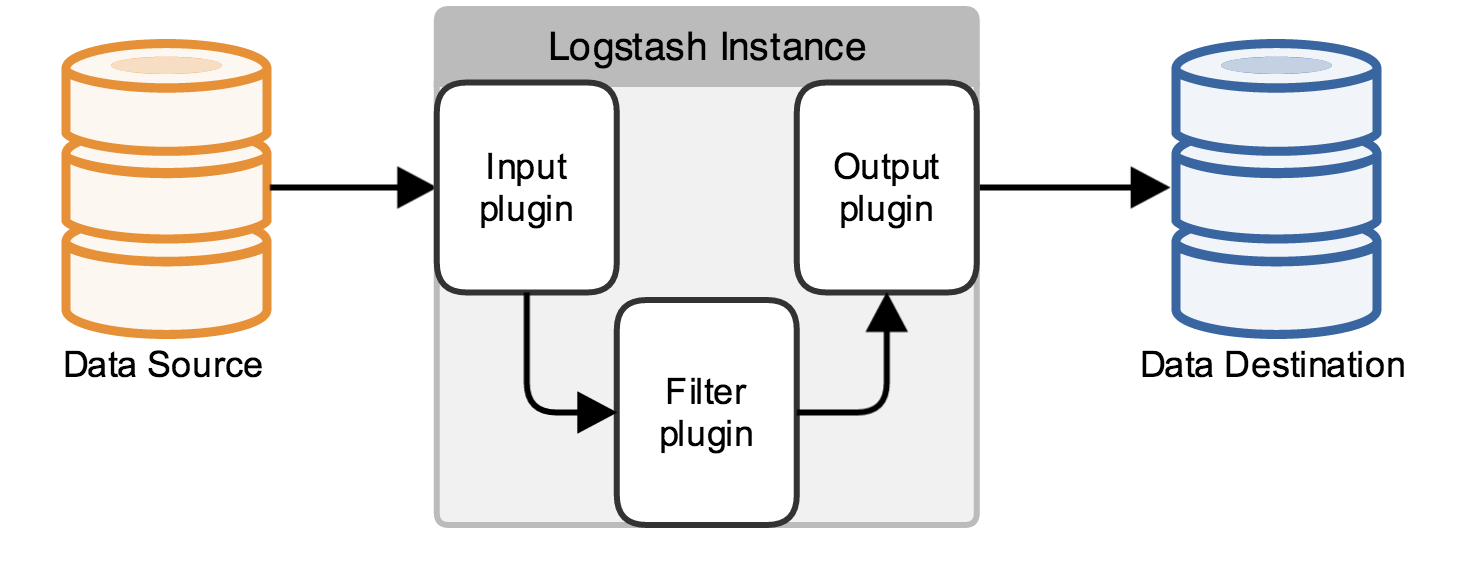
在input中,按需取log,一般去拿路径下面的log; 在filter中,有大约200多个插件,能够实现不同的功能,下面的例子我用ruby插件实现过hash; 在output中,将信息传送到消息队列或者elasticsearch中;
我的两个实例如下:
① shipper->broker:将消息从源送往缓存,减轻elasticsearch的压力
input { file { codec => multiline { pattern => "^201" negate => true what => "previous" } type => "test-type" path => ["/path/to/yourlog/test1.log","/path/to/yourlog/test2.log"] exclude => ["*.gz"] tags => ["test-tags"] start_position => "beginning" } }#注释——file插件,只需要指向日志的path即可,自己定义type(保证唯一~在后面会用到;start_position是log扫描的起始位置,默认是尾部,这里设成的是begining) #注释———filter能对数据做200多种处理(因为有200多种插件),这里只是传输数据,所以没必要用filter处理数据,但会在下面用到 output { kafka { codec => plain { format => "%{host} %{message}" } compression_type => "snappy"#注释——kafka的压缩格式,能够节省空间 topic_id => "test-topic-id"#注释——区分不用的消息队列,每个topic_id都要保证唯一性 client_id => "10.0.40.1"#注释——类似于id,便于后期查找问题 bootstrap_servers => "0.0.49.1:9092,0.0.49.2:9092,0.0.49.3:9092,0.0.49.4:9092,0.0.49.5:9092" }#注释——五台kafka的机器用来做消息队列,起到缓冲的作用 } ② broker->indexer->elasticsearch:将消息从缓存拿出来(input),然后用filter按我们需要的处理,然后送到elasticsearch(output)
input{ kafka { codec => plain {} zk_connect => "0.0.49.1:2181,0.0.49.2:2181,0.0.49.3:2181,0.0.49.4:2181,0.0.49.5:2181"#注释——注意这里是zookeeper,不是kafka,所以,各位需要自行配置zk实现负载均衡等... group_id => "test-group-id"#注释——区分用~避免以后争抢同一topic_id topic_id => "test-topic-id"#注释——注意这里和上面的topic_id对应 consumer_threads => 2 auto_offset_reset => "smallest" } } filter{#注释——在这里可以通过处理数据,做很多事情 grok { match => ["message", "%{TIMESTAMP_ISO8601:logdate}"] }#注释——grok这个插件自我感觉主要就是用正则匹配 date { match => [ "logdate", "yyyy-MM-dd HH:mm:ss,SSS" ] target => "logtime" remove_field => [ "logdate"] }#注释——date插件用来处理时间 ruby{#注释——ruby插件用来:首先熊message中,匹配到id,然后将id对应的name用hash展示出来,我们的原始数据是类似这样的(一条,其中加黑加斜体部分是可变的,比如registerFrom:56,regiserFrom和loginFrom是信息类型,56和222是id,他们分别对应着中文名字——中文名字是我们最终想要的结果):bj2-lkb-tomcat2.quantgroup.cn 2016-04-19 21:38:09,975 [INFO ] c.q.x.c.external.user.AppController - 第三方用户登录成功, **_loginFrom:222_**, phoneNo:13976701637 我们要将**_loginFrom:222_**提取成**_channelName:222对应的中文名字_** init => "@kname = ['channelName'];@pattern=/registerFrom:(/d+)|loginFrom:(/d+)/;@hashChannel={'56'=>'量化派','222'=>'现金巴士'}"#注释——此处配置的ruby的hash来将匹配到的数字转换为 中文名字(提高在kibana的阅读性) code => "event.append(Hash[@kname.zip(Array(if @pattern.match(event['message'])[1] then @hashChannel[@pattern.match(event['message'])[1]] elsif @pattern.match(event['message'])[2] then @hashChannel[@pattern.match(event['message'])[2]] end ))]) if @pattern.match(event['message'])"#注释——ruby代码 :最后面的if 相当于我们的前提条件,如果匹配到,才会去执行前面的代码,避免ruby报exception(否则exception会显示在kibana中) } } output{ elasticsearch { hosts => ["10.0.9.1:9200","10.0.9.2:9200","10.0.9.3:9200", "10.0.9.4:9200", "10.0.9.5:9200"]#注释——集群,hosts可以写多个地址,有细心的朋友问不是可以写一个地址,然后ES实现自动分配吗?正解:万一 一个断了,ES可以分配给其余的节点(ES只会根据优先级挑选一个ES,不会发给所有的host),苦逼的运维思路~ index => "logstash-test-%{+xxxx.ww}"#注释——index索引,后面的xxxx.ww说明我们是按周来生成索引,我们可以按需设置成按天/周/月...自我感觉按周的适用性较高。另外特别注意的一点是没什么事老实的用logstash-起头来定义你的index索引,因为这样的话,logstash会自动去匹配一个优化好的模板,否则的话,你还需要自己配置映射,麻烦麻烦麻烦的很,[可参见这篇博文](http://my.oschina.net/yangchunlian/blog/660848),我当时走过弯路。这里就是配置中文索引字段的小技巧了,其中配置模板映射的模式可以精准命名。raw的方式会同时包含一个analyzed的字段和一个not_analyzed的字段。强烈建议日志前加 logstash-!!!!!!!!!!!!!!! } } 至此,logstash配置完毕。
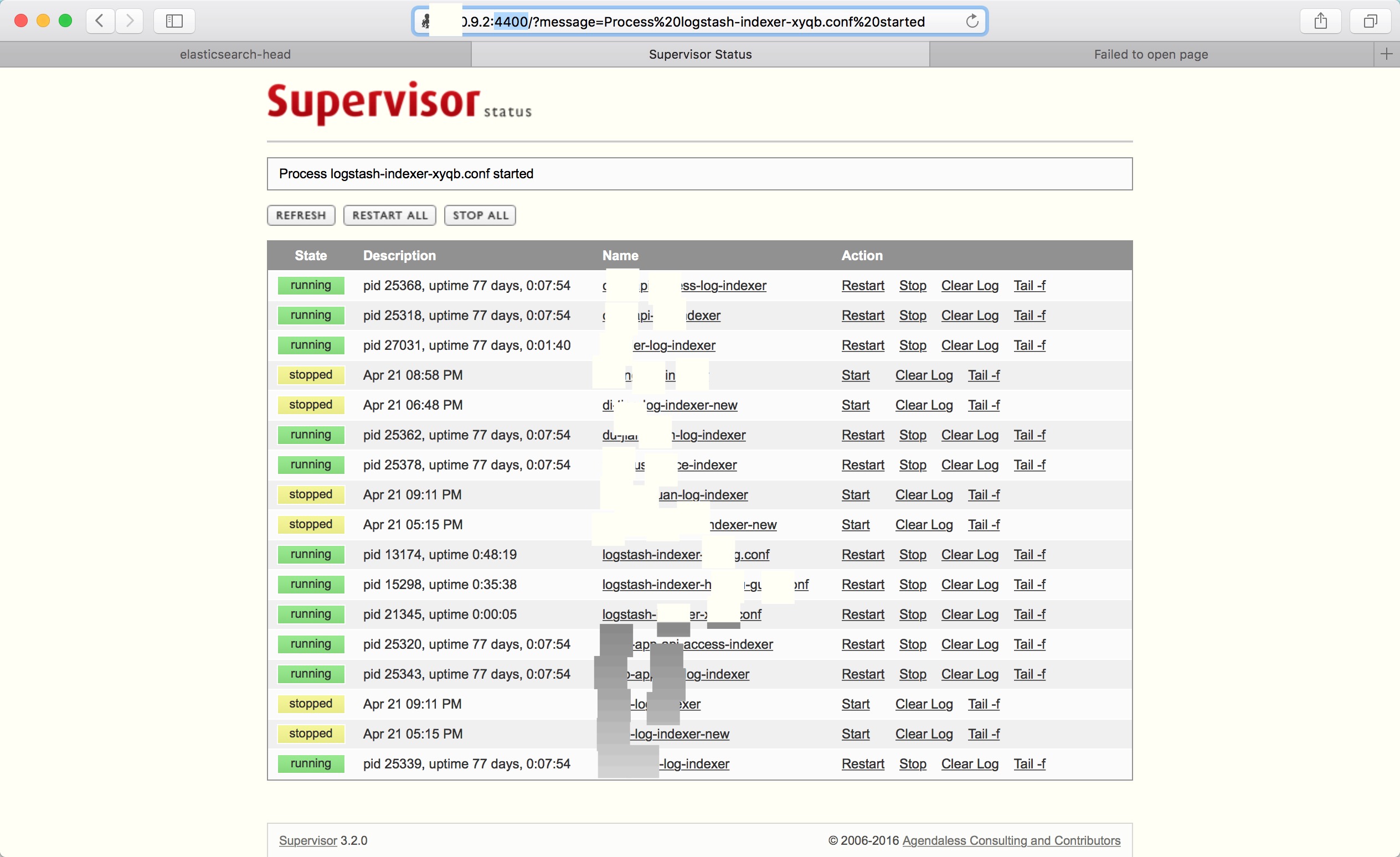
但是,大家肯定不会每次启动logstash的时候都用 logstash -f xx.conf 的方式去启动, 这里,需要我们配置supervisord,配置的教程大家 看这儿吧 ,这里要配置成自动拉起(需要注意的是,每台机器都要配置哦~~),它还可以直接图形化界面的形式管理你的logstash启动项(见下图),好开心有木有?
在supervisor/conf/supervisord.conf中,我们可以修改相应的参数,添加相应的logstash的conf启动项。
Four, 配置Elasticsearch
Elasticsearch需要配置什么呢? 我目前也就改改bin/elasticsearch.in.sh里面的内存
if [ "x$ES_MIN_MEM" = "x" ]; then ES_MIN_MEM=256m fi if [ "x$ES_MAX_MEM" = "x" ]; then ES_MAX_MEM=1g fi
logstash说不定还会改改java环境变量。 再就是改改config/elasticsearch.yml里面的名字神马的,
cluster.name: my-application#注释——集群名字,一个集群下的名字总该相同咯 node.name: node-2#注释——节点名字,一个集群下,节点名字肯定不同咯 node.rack: r1 path.data: /home/es/elasticsearch-2.2.0/data#注释——索引存储地址,所以这儿的文件最大咯 path.logs: /home/es/elasticsearch-2.2.0/logs#注释——es的log地址 network.host: 10.0.9.2#注释——配置host http.port: 9200#注释——配置端口,建议默认哦 discovery.zen.minimum_master_nodes: 3 gateway.recover_after_nodes: 3
思前想后,也就这么点东西吧,欢迎补充。
Five, 配置kibana
与logstash和elasticsearch不同,kibana我们设置单节点即可(当然如果用户多,也可以配置集群;另外,万一我们配置的机器如果挂了,也能从其它机器访问嘛;but,入门阶段,建议先配置一个就好了,机器哪那么容易就挂掉)。
随便找台你的es机器,安装启动了kibana之后,在网页中打开host:5601就能打开kibana的web界面。
而就是这个web界面,能够极大提高程序员的bug查找效率。
比如最low的方式是去线上机器中查找log(tailf命令。。。。。。),然后用你的肉眼凡睛去定位你的问题。 但是用了kibana,可以直接图形化界面的形式查找。
再就是kibana能够根据日志来形成图形化界面,来观测数据库中和程序中看不到的数据。(其实kibana还可以做一些权限控制等功能,这个大家入门后根据需求慢慢深入)
此外,利用logstash的filter的二百多个插件,我们可以集成很多不同的功能,比如传统的用ab + nmon来测系统的负载情况,我们可以直接用filter的collectd插件集成进来,然后用kibana来图形化,简单!高效!开心!
so,开源的ELK就是利国利民的神器。
个人原创,欢迎转载,注明出处——如有批评建议,+杨春炼~qq:1028750558
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

