如何选择Docker监控方案
这是2016/4/23关于Docker性能监控的一次Meetup的内容节选,完整内容请参见文末 链接
大家好,非常高兴来上海跟大家分享一下我们在Docker监控方面的一点点经验。
今天我要跟大家享主题是《如何选择Docker监控方案》。
这里我将主要对Docker监控的原理和常用工具以及主流的解决方案进行简单介绍,如果大家正准备对Docker进行监控,希望这次分享能为大家带来一些帮助,如果你们已经进行了对Docker的监控,我也希望能的大家交流一下经验,跟大家互相学习一下。
同时,最后我也会安利一下SaaS这种商业模式,甚至是一种消费观念。可以说,我这次代表的不是某具体厂商,而是代表我们同样做类似服务的SaaS行业。
什么是监控
为什么监控,监控什么内容?
我们要对自己系统的运行状态了如指掌,有问题及时发现,而不让让用户先发现我们系统不能使用,打电话过来到客服,客服再反映到开发,这个过程很长,而且对工程师来说,是一件比较没面子的事情。
我们也不能一问三不知,比如领导问我们这个月的MySQL并发到了什么情况?slowsql处于什么水平,平均响应时间超过200ms的占比有百分之多少?
回答不出来这个问题很尴尬,尽管你工作很辛苦,但是却没有拿得出来的成果。不要以为没出问题就没事了,你要换位想想,站在领导的角度,领导什么都不干,你提案,他签字,出了问题领导责任也很大啊。
监控目的
- 减少宕机时间
- 扩展和性能管理
- 资源计划
- 识别异常事件
- 故障排除、分析
我们为什么需要监控我们的服务?其中有一些显而易见的原因,比如需要监控工具来提醒我服务出现了故障,比如通过监控服务的负载来决定扩容或缩容。如果机器普遍负载不高,则可以考虑是否缩减一下机器规模,如果数据库连接经常维持在一个高位水平,则可以考虑一下是否可以进行拆库处理,优化一下架构。
此外,监控还可以帮助进行内部统制,尤其是对安全比较敏感的行业,比如证券银行等。比如服务器受到攻击时,我们需要分析事件,找到根本原因,识别类似攻击,发现没有发现的被攻击的系统,甚至完成取证等工作。
Docker监控的挑战
- Docker特点
- 像host但不是host
- 量大
- 生命周期短
- 监控盲点(断层)
- 微服务
- 集群
- 全方位
- Host(VM) + Services + Containers + Apps
容器为我们的开发和运维带来了更多的方向和可能性,我们也需要一种现代的监控方案来应对这种变化。
随着不可变基础设施概念的普及,云原生应用的兴起,云计算组件已经越来越像搭建玩具的积木块。很多基础设施生命周期变短,不光容器,云主机、VM也是。
在云计算出现之前,一台机器可能使用3、5年甚至更长都不会重装,主机名也不会变,而现在,我们可能升级一个版本,就重建一个云主机或者重新启动一个容器。监控对象动态变化,而且非常频繁。即使全部实现自动化,也会在负载和复杂度方面带来不利影响。
集群的出现,应用的拓扑结构也变得复杂,不同的应用的指标和日志格式也不统一,再加上如何应对多租户,也给监控带来了新挑战。
传统的监控内包括主机、网络和应用,但是Docker出现了,容器这一层容易被忽略,成为三不管地区,监控的盲点。
有人说,容器不就是个普通的OS么?装个Zabbix的探针不就行了么?
Docker host和Docker 容器都要装Zabbix探针。。。其实问题很多。
除了容器内部看到的cpu内存情况不准之外,而且容器生命周期短,重启之后host名,ip地址都会变,所以最好在Docker host上安装Zabbix agent。
如果每个容器都像OS那样监控,则metric数量将会非常巨大,而且这些数据很可能几分钟之后就无效率了(容器已经停止)。容器生命周期短暂,一旦容器结束运行,之前收集的数据将不再有任何意义。
主要的解决方式就是对以App或者Service为单位进行监控(通过Tag等方式)。
Docker监控技术基础
-
docker stats - Remote API
- 伪文件系统
我们可以通过 docker stats 命令或者Remote API以及Linux的伪文件系统来获取容器的性能指标。
使用API的话需要注意一下,那就是不要给Docker daemon带来性能负担。如果你一台主机有200个容器,如果非常频繁的采集系统性能可能会大量占据CPU时间。
最好的方式应该就是使用伪文件系统。如果你只是想通过shell来采集性能数据,则 docker stats 可能是最简单的方式了。
docker stats命令
$ docker stats redis1 redis2 CONTAINER CPU % MEM USAGE/LIMIT MEM % NET I/O redis1 0.07% 796 KB/64 MB 1.21% 788 B/648 B redis2 0.07% 2.746 MB/64 MB 4.29% 1.266 KB/648 B 该命令默认以流式方式输出,如果想打印出最新的数据并立即退出,可以使用 no-stream=true 参数。
伪文件系统
- CPU、内存、磁盘
- 网络
文件位置大概在(跟系统有关,这是Systemd的例子):
/sys/fs/cgroup/{memory,cpuacct,blkio}/system.slice/${docker ps --no-trunc}.scope Docker各个版本对这三种方式的支持程度不同,取得metric的方式和详细程度也不同,其中网络metric是在1.6.1之后才能从伪文件系统得到。
Memory
内存的很多性能指标都来自于 memory.stat 文件
... ... cache 11492564992 rss 1930993664 swap 0 pgfault 728281223 ... ... total_cache 11492564992 total_rss 1930993664 total_pgpgin 406632648 total_pgpgout 403355412 total_swap 0 total_pgfault 728281223 ... ... 前面的不带total的指标,表示的是该cgroup中的process所使用的、不包括子cgroup在内的内存量,而total开头的指标则包含了这些进程使用的包括子cgroup数据。这里我们看到的数据都是一样的,由于这里并没有子cgroup。
两个比较重要的指标:
- RSS: resident set size
进程的所有数据堆、栈和memory map等。rss可以进一步分类为active和inactive(active_anon and inactive_anon)。在内存不够需要swap一部分到磁盘的时候,会选择inactive 的rss进行swap 。
- cache memory
缓存到内存中的硬盘文件的大小。比如你读写文件的时候,或者使用mapped file的时候,这个内存都会增加。这类内存也可以再细分为active和inactive的cache,即active_file和inactive_file。如果系统需要更多内存,则inactive的cache会被优先重用。
CPU
-
cpuacct.stat文件 - docker.cpu.system
- docker.cpu.user
但是比较遗憾,Docker 不会报告nice,idle和iowait等事件。
System也叫kernel时间,主要是系统调用所耗费的部分,而user则指自己程序的耗费CPU,如果User时间高,则需要好好检查下自己的程序是否有问题,可能需要进行优化。
Blkio
优先从CFQ(Completely Fair Queuing 完全公平的排队)拿数据,拿不到从这两个文件拿:
blkio.throttle.io_service_bytes ,读写字节数 blkio.throttle.io_serviced ,读写次数
Throttle这个单纯可能有误导,实际这些都不是限制值,而是实际值。
每个文件的第一个字段是 major:minor 这样格式的device ID。
网络数据
- iptables
- 伪文件系统
-
网络设备接口
-
Virtual Ethernet
针网络的监控要精确到接口级别,即网卡级别。每个容器在host上都有一个对应的virtual Ethernet,我们可以从这个设备获得tx和rx信息。
不过找到容器在主机上对应的虚拟网卡比较麻烦。这时候可以在宿主机上通过 ip netns 命令从容器内部取得网络数据。
为了在容器所在网络命名空间中执行 ip netns 命令,我们首先需要找到这个容器进程的PID。
$ CONTAINER_PID=`docker inspect -f '' $CONTAINER_ID` $ mkdir -p /var/run/netns $ ln -sf /proc/$CONTAINER_PID/ns/net /var/run/netns/$CONTAINER_ID $ ip netns exec $CONTAINER_ID netstat -i 或者:
$ CONTAINER_PID=`docker inspect -f '' nginx ` $ cat /proc/$CONTAINER_PID/net/dev 实际上Docker的实现也是从伪文件系统中读取网络metric的:
$ pwd /sys/class/net/veth559b656/statistics $ ls collisions rx_crc_errors rx_frame_errors rx_packets tx_compressed tx_heartbeat_errors multicast rx_dropped rx_length_errors tx_aborted_errors tx_dropped tx_packets rx_bytes rx_errors rx_missed_errors tx_bytes tx_errors tx_window_errors rx_compressed rx_fifo_errors rx_over_errors tx_carrier_errors tx_fifo_errors Docker监控方案实现
- 自己动手 + 开源软件
- SaaS
评价标准
- 功能
- 满足
- 信息详细程度
- 查询的灵活程度
- 报警 + API
- 灵活性
- 定制
- 成本
- 学习、开发
- 维护
- 运维
- 部署复杂程度
- 高可用
需要考虑的基本要素如上所示,不多述。
自己动手
- 灵活性强
- 成本高
这里的成本包括开发成本,开发成本可能包括招人和培训,开发时间和填坑时间。开发完了还需要维护成本,而且随着Docker的升级,可能还需要对metric的采集实现进行升级,以及各种bugfix。
自己动手打造监控方案
- 采集
- 存储
- 展示
- 报警(动作)
StatsD 是 Flickr 公司首先提出来的,后来由 Esty 公司发扬光大的一个轻量级的指标采集模块。
简单来讲,StatsD 就是一个简单的网络守护进程,基于 Node.js 平台(Esty实现,其实也有其他语言版本),通过 UDP 或者 TCP 方式侦听各种统计信息,包括计数器和定时器,可以用来采集操作系统、不同数据库、中间件的数据指标,进行缓存、聚合,并发送到Graphite 等存储和可视化系统中。
StatsD 具有以下优点:
- 简单
首先安装部署简单,且StatsD 协议是基于文本的,可以直接写入和读取,方便实现各种客户端和SDK。
Cloud Insight的探针也是采用这些方式,我们有些SDK也是基于StatsD的,目前有Ruby、Python和Java的,在 GitHub 上可以看到。
- 低耦合性
StatsD 守护进程采取 UDP 这种无状态的协议,收集指标和应用程序本身之间没有依赖,不会阻塞应用,不管StatsD的状态是运行中,还是没在运行,都不会影响应用程序,应用程序也不关心StatsD是否收到数据。
- 易集成
StatsD非常容易整合其他组件,可以自己编写采集业务逻辑,发送到StatsD守护进程即可。也就是说用户的工作很简单,只需要按定义好的规则采集数据发送到Stats,然后用Graphite存储、展示,通过使用Riemann进行报警。
Tcollector
- 来源于OpenTSDB
Tcollector 是一个采集指标数据并保存到OpenTSDB的框架,你可以使用该框架自己编写采集的业务逻辑。类似StatsD,运行在客户端,收集本地的metric信息,推送到OpenTSDB。
Collectd
- System statistics collection daemon
- 存储到RRD
- 插件机制(input/output)
- 简单报警功能
Collectd即是一个守护进程,也是一个框架,类似StatsD,它性能非常好,采用C语言编写。Collectd不直接支持从Docker中取数据,但是我们可以自己编写插件来采集性能指标数据。
Collectd有强大的插件机制,已经实现了包括amqp、rrdtool、graphite、http、kafka、redis、mongodb、OpenTSDB以及CSV文件等在内的各种插件。
在4.3版本之后还支持简单的基于阈值检查的报警机制。
cAdvisor(Container Advisor)

cAdvisor是一个用于收集、聚合处理和输出容器运行指标的守护进程。而且cAdvisor基本算是一个获取Docker性能数据的标配了吧。
sudo docker run / --volume=/:/rootfs:ro / --volume=/var/run:/var/run:rw / --volume=/sys:/sys:ro / --volume=/var/lib/docker/:/var/lib/docker:ro / --publish=8080:8080 / --detach=true / --name=cadvisor / google/cadvisor 一句命令就可以启动cAdvisor容器,访问8080端口即可看到性能指标数据。cAdvisor可以通过storage_driver参数将数据存到influxdb,同时也可以将metric输出为Prometheus的格式,所以很多自定义Docker监控系统都会采取cAdvisor + Prometheus 的组合。
存储TSDB
- OpenTSDB
- Influxdb
- RRDTool
- Graphite
关于时序列数据库,可以看附录中相关的介绍文章。推荐使用OpenTSDB或者Influxdb,简单对比一下各自特点如下:
- OpenTSDB
- Java & HBase
- 易扩展(集群功能强大)
- 机器多,运维稍显麻烦
- Influxdb
- Golang
- 集群功能不太成熟
- 有类SQL的查询语句
- 单台即可工作
这两者都支持自由模式和多维度,非常适合用于采用tag机制的数据模式建模。
开源可视化工具
- Graphite
- Influxdb + Grafana
- Prometheus
光有数据是不够的,raw data没有任何意义,我们需要良好的可视化组件来展示数据和数据的内在意义,发挥数据的作用。
我们也可以将数据存储和展示交给其他开源软件。
如果你的数据采集和存储都是自己来完成的,只想使用一个外部的图形化界面的话,选Grafana应该没错,Grafana展现形式非常丰富,配置也很灵活。

开源方案
- cAdvisor(经典)+ InfluxDB + Grafana
- Zabbix/Nagios/Hawkular
- Fluentd
- Prometheus
- Riemann
- ATSD(Axibase Time Series Database)
Hawkular 是一个来自于RedHat开源的监控解决方案,也包括报警等系统,可以说功能非常强大。
Hawkular基于Cassandra存储,它认为这虽然增加了运维的复杂程度,但是扩展变得容易(参考前面关于OpenTSDB和Influxdb的对比)。
Zabbix
- 最经典(SaaS软件的最大敌人)
- 架构简单、清晰
- 文档丰富
- 包括采集、触发、告警
- Agent支持用户自定义监控项
- 通过SNMP、ssh、telnet、IPMI、JMX监控
- 一套HTTP + JSON的接口
现在Zabbix已经实现了探针的自动注册,也支持了基于角色的监控对象自动发现,但是你还是需要管理这些自动配置的项目。而且监控的服务多了,Zabbix探针在监控对象上运行的脚本也会变多,需要更多的进程,可能会对正常业务产生影响。
在Zabbix中支持Docker,可以使用 Zabbix Docker Monitoring ,首先需要下载两个xml的模板文件,导入到管理界面,然后在docker host,也就是zabbix的agent的机器上,安装zabbix模块(.so),然后还得在Docker主机上启动cadvisor容器。
Graphite
主要功能:
- 存储数值型时序列数据
- 根据请求对数据进行可视化(画图)
Graphite是一个经典的时序列数据存储,容易扩展,提供了功能强大的画图Web API以及大量的函数和输出方式。Graphite有自己的可视化实现,也可以支持Grafana。
Graphite本身不带数据采集功能,你需要选择其他第三方插件,比如Collectd等。
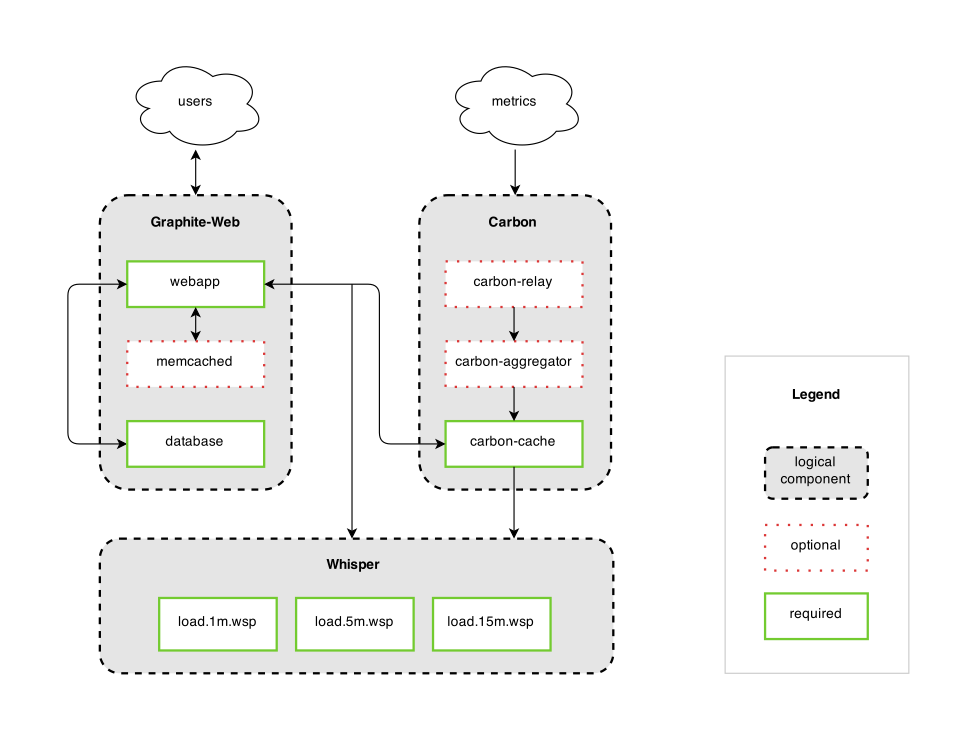
Graphite架构自下而上分为3个模块:
- whisper:创建、更新RRD文件
- carbon:以守护进程的形式运行,接收数据写入请求
- carbon-cache:数据存储
- carbon-relay:分区和复制,位于carbon-cache之前,类似carbon-cache的负载均衡
- carbon-aggregator:数据集计,用于减轻carbon-cache的负载
- graphite-web:用于读取、展示数据的Web应用
Whisper使用了类似RRDtool的RRD文件格式,不像C/S结构的软件,whisper没有服务进程,只是作为library来使用,直接对文件进行create/update/fetch等操作。
Prometheus
- 一体化、仪表盘和告警
- 多维度
- 灵活查询语言
- 非分布式、单机自治
- 基于HTTP的pull模式(push需要中间网关)
- LevelDB
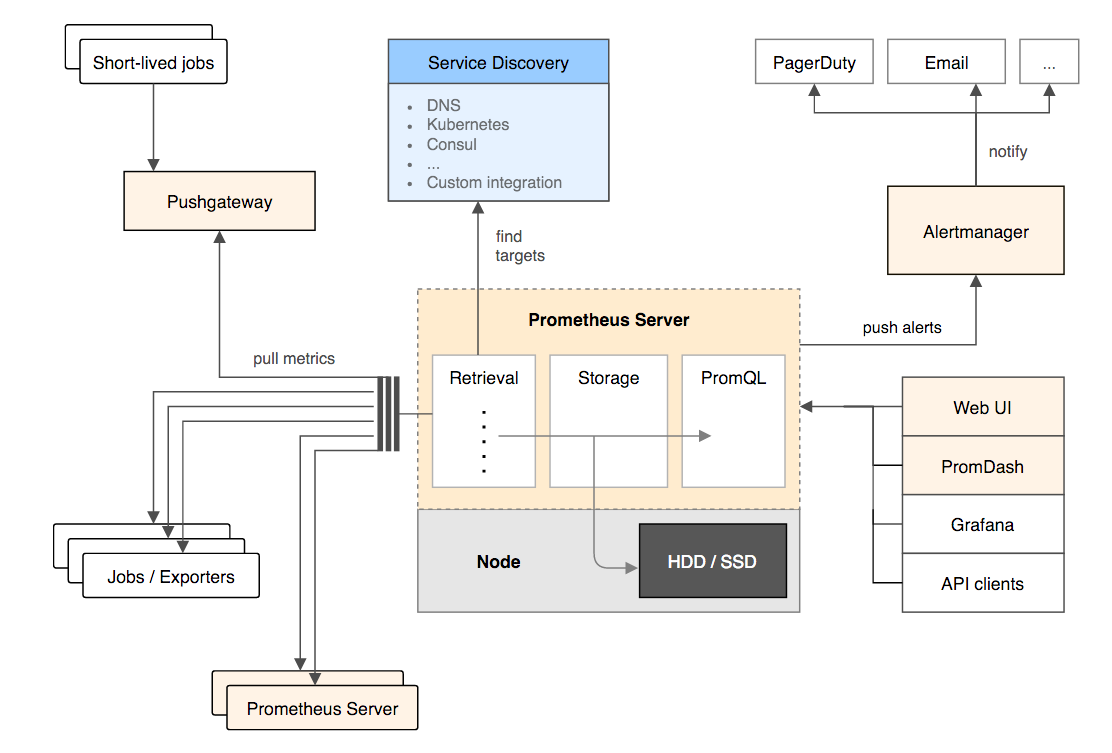
Prometheus是一个全套监控和预测方案,包括数据采集、存储、查询和可视化,以及报警功能。由社交音乐平台SoundCloud在2012年开发,最近也非常火。
在集群流行的时候,很少有软件专为单机、本地存储而设计。Prometheus就是这样一个软件,它采用了基于LevelDB的本地存储,并没有使用成熟的面向列的数据库。不过Prometheus 也在实验将数据存储到OpenTSDB。
Prometheus 采用了pull模式,即服务器通过探针端的exporter来主动拉取数据,而不是探针主导上报。
Prometheus部署和运维起来可能比较麻烦,需要很多组件单独安装,比如dashboard(PromDash),虽然这虽然显得更加开放和包容。不过使用Docker的话将会简单很多,通过一个Docker Compose配置文件就能建立全功能的Prometheus监控环境,网上有很多这样的例子。
Heapster
- 经典组合:heapster + Influxdb + grafana
- Sink:Kafka、stdout、gcm(Google Cloud Monitoring)、hawkular、monasca、riemann、opentsdb
Heapster是k8s的一个子项目,用于获取集群的性能数据。现在Heapster原生支持k8s和CoreOS,也可以很容易扩展来支持其他集群管理软件。
Heapster除了支持,基本的metric之外,还支持事件类型的数据,比如容器生命周期事件。
Riemann
- 事件处理
- Clojure实现
Riemann 是一个分布式监控(数据处理)系统,但它做的事情其实非常简单,就是接收事件->按定义规则处理->转发或存储到外部系统。
我们可以将Riemann 与时间序列数据库,或者基于 StastD 的方案集成使用,来弥补其他方案在报警、事件流处理这方面上的不足。
Riemann采用Clojure语言编写,这是一门Lisp方言,函数式编程语言,对于大多数习惯于过程式或者面向对象的现代人来说,理解起来有一定难度,有一定的学习曲线。
开源软件的问题点
- 灵活性受限于upstream
- 维护成本高
- 定制难度大
- 技术栈
要选择自己熟悉或者能投入精力去熟悉的技术栈产品,否则有问题没人调查,监控产品将沦为摆设。
SaaS
- turnkey解决方案
- 维护成本 ~ Zero
- 适合中小企业
对于中小型企业尤其创业公司来说,自主开发或者直接利用现有的开源工具进行监控都有一些问题,主要是成本和风险的问题。对于中小企业,应该先把精力集中在发展核心业务,能外包的就先不自己做。而且很多中小公司大家都是全栈,没有专门的运维人员,都是临时抱佛脚,随时都会变成救火队员。
SaaS最大的优点是什么?那就是免运维,开箱即用,修改的代码少甚至不需要修改代码,或者只需要简单的安装一个agent就可以工作了。很多SaaS软件的开场白都是运行一条 yum install ,然后倒上一杯咖啡等几分钟,就能看到数据了。
你的初期投入非常少,上手非常快,而且成本比较低(如果你的公司已经有数百上千服务器了,则这部分成本可能会变高,就跟是自建机房还是用云主机的对比一样)。
SaaS
- 传统APM
- New Relic
- AppDynamics
- Dynatrace(Ruxit)
- 基础设施监控
- Datadog
- SysDig
- Cloud Insight
- clusterup
- Scout
RancherLab公司有人写了篇文章,本讲稿的最后有链接,大家可以参考下。这篇文章名为《Comparing Seven Monitoring Options for Docker》,即对比了七种不同的监控Docker的方案,包括使用 docker stats 命令, cAdvisor, Prometheus ,Sensu,以及saas服务 Scout, Sysdig Cloud and DataDog等方案,作为结论作者觉得Datadog是这其中最优秀的方案。
RancherLab有一个产品叫RancheOS,是一个专门为了运行Docker准备的微型Linux版本,它的口号是“The perfect place to run Docker”。跟CoreOS类似,但是貌似功能不如CoreOS多,也没有CoreOS有名,也没有CoreOS中fleet、flannel和etcd这样的组件,尤其是etcd,可以说是CoreOS的副产品,但是几乎成了Docker业界标准的kv store和服务发现组件了。
Datadog
- 国外最好
- 功能很强大
- 安装很简单
国外最流行的SaaS解决方案是Datadog,国内可能比较成熟、规模较大的应该算是Cloud Insight了。
这类服务用户只需要注册一个账号,按照安装过程通过一条命令来安装探针即可在web展示端看到数据。
要说到Datadog的不足,那就是在国外,网络延迟需要考虑,万一哪天不科学了也需要有所准备。
价格方面Datadog也比较贵。免费plan支持5台机器,而且只保留一天的数据,而且没有报警功能。收费版15美元一台主机,支持报警功能,数据存储13个月。
说道SaaS,不得不提客服,直接面对非母语客服人员交流起来肯定会有诸多不顺吧。
Cloud Insight
- 实时数据
- 历史数据
- 仪表盘
- 混合监控
- 报警功能
当然,最便宜的还是Cloud Insight,有多便宜呢,官方定价的话3个探针以下是免费的,支持超过3台主机的话,平均每天1快钱。
这只是官方定价,实际上还会便宜,貌似联系客服就可以知道有多便宜了。
Cloud Insight还支持ChatOps集成,包括国内的 BearyChat 和简聊。随着devops文化的普及,相信这些工具的重要性也会与日俱增。
Cloud Insight的图表功能也很丰富,能对任何指标以图表的方式展示,还能在图表上叠加事件,比如报警通知、服务启动停止等,能在观察到metric变动趋势的同时,看到相应的时间,了解metric发生变动的原因。比如CPU load超过一定值时,可能触发报警,这时你能在图表上看到相应的事件,同样,如果CPU load一直不是很低,但是从某一时间点开始变低了,你可能也能从一次新的代码部署中了解原因。
Sysdig
- 免费工具
- SaaS服务 Sysdig Cloud
- 拓扑可视化
可以认为sysdig是strace + tcpdump + htop + iftop + lsof + 众多linux常用的系统监控命令的合体。
如果你熟悉tcpdump,那么你知道它能还原整个网络流量,而sysdig则是操作系统级别的监控工具,能捕捉到所有OS事件和数据。
而且sysdig原生支持Linux container,包括Docker和LXC,提供了基本的指标监控信息。除了性能指标,sysdig还能采集trace等日志信息,用于以后的问题分析和解决。
Sysdig Cloud是sisdig的SaaS版,除了基本的单机sysdig功能之外,还提供了跨平台跨基础设施的组件间依赖关系的可视化。
Librato
- 数据聚合平台
- 简单探针
- 图表和报警
- 价格不贵
Librato是一个数据聚合平台,而不是严格意义的监控系统。
Librato很容易从AWS CloudWatch和Heroku获得数据,如果是自己监控主机或者Docker,需要使用Collectd框架。它也有很多插件,可以从StatsD、Riemann等数据源采集数据。
Librato的探针虽然功能不是强大,但是他提供了丰富的实时在线数据处理功能,用户可以使用DSL对任意时间序列数据组合进行数学运算,比如加减乘除、比率导数等。还支持和时间窗口滑动功能,即跟过去某一段时间进行比较。
Librato也支持报警,基于metric和条件,设置报警信息。
Librato是按照metric的个数和时间分辨率来收费的,在官网的主页上有一个大概的估算,如果你有20个metric,并且时间间隔为60秒,则一台服务器的价格只有2美元1个月,这比datadog要便宜。
Axibase(ATSD)
- 非开源TSDB
- 支持报警
- 预测功能
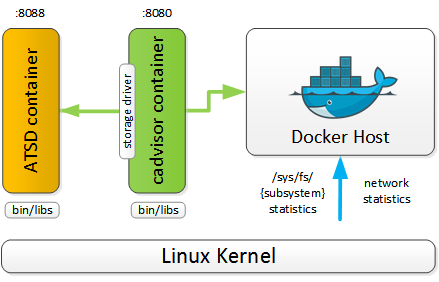
作为TSDB,ATSD支持长时间存储高精度的metric数据。ATSD支持多种数据采集工具和协议,比如tcollector, Collectd,当然ATSD也支持从多台Docker主机手机指标数据,并长期保存,进行可视化和分析。
除了传统的时间序列数据,ATSD还支持属性(Properties)和消息这两种类型的数据。属性一般用于保存meta data,这有点类似标签。
和OpenTSDB一样,ATSD也支持tag,我们可以使用这些tag进行过滤和聚合。
ATSD内置了自动回归推断算法(holt-winters,arima),可以提早预测故障。预测功能的准确性取决于数据的采集频率,保存时间(也就是数据量大小)和算法。
最大的遗憾,就是ATSD不是开源,也不是免费的软件,不过他们提供了一个社区版可以免费使用,但是你只能在一个节点上安装ATSD,而且不能用于盈利性服务,也不能对软件进行修改以及再发布。
如果我们只是评估一下,或者想自己构建监控方案,它的产品设计还是非常值得我们来借鉴一下。
SaaS的挑战
- 数据敏感性
采用SaaS,意味着你的数据都将会保存到公网,可能会带来心理不安全感。实际上SaaS反而会更安全些,尤其是对中小公司没有专门的安全运维团队的情况下。
- 成本(迁移和使用成本)
一般来说这是一个一次性投入成本。
- 内部抵抗(观念、个人爱好)
来自技术人员自身的抵抗,不是每个人都喜欢自己变得轻松,使用SaaS可能会给一些人带来工作上的不充实感。
趋势
- 标签机制
一种观点:监控服务状态胜过监控个别容器,通过tag机制对服务整体的性能指标进行聚合。
Tag可以是任何维度,比如BU,地区,服务,甚至个别容器。
Docker和Kubernetes等都支持label机制,即tag机制。
- docker daemon –label com.example.group=“webserver”
- docker run –label com.example.group=“webserver”
-
Dockerfile: LABEL com.example.group=“webserver”
-
通过API打通
通过API化实现共赢。开源软件比如fluentd、Collectd等,都支持插件功能。包括Docker本身,也在1.11版本中,采用了runC作为容器运行时,在上面通过containerD来统一控制,来支持符合OCI标准的容器。
- Total解决方案
包括从探针到展示、告警,就是现在类似Datadog和Cloud Insight这样的产品,以及支持中间件的详细程度,就像一个大市场,什么都能买到,不管你用什么软件,平台都能提供监控。
这就像是去了酒吧突然想吃碗拉面,然后竟然酒吧能给你做出来的那种感觉。
另一个层面就是从RUEM(实时用户体验管理)到基础设施层的 打通 。比如你看到某URL的用户HTTP响应较慢,如果不能跟后端的APM打通,你尽管能识别出问题,但是你不知道如何解决。如果和后端的APM以及基础设施监控打通,你就能定位到HTTP响应慢时,相应的后端代码的位置,并根据后端代码的位置从而进一步找到MySQL的监控数据以及系统异常事件,立刻知道问题的根本原因所在并解决问题,可以说效率应该能提高几个数量级。
系统监控工具如果能够做到 All in One,真的对解决人力和时间成本上有非常大的帮助。
- 拓扑可视化
跨组件、跨基础设施和应用,自动识别组件以及组件之间的依赖关系,以帮助更好的发现问题和解决问题。
- Weave Scope
- Ruxit
- Sysdig
参考:
- 本次分享全部资料
- Comparing Seven Monitoring Options for Docker
- How to collect Docker metrics
- 时序列数据库武斗大会
- Fluentd Docker Metrics Input Plugin
- Docker Runtime metrics
正文到此结束
- 本文标签: heartbeat 负载均衡 cat 配置 API 创业公司 json 开发 统计 下载 java 协议 自动化 js 产品 安装 管理 UDP MongoDB 操作系统 core 文章 云 服务器 db git 进程 map 领导 TCP Cassandra 参数 src python mysql Nginx node iptables 数据库 sql IDE 时间 google cloud 软件 lib ACE linux root awk 银行 HBase redis 代码 Kubernetes 插件 example strace 探针 remote 网卡 创业 安全 数据 GitHub App key 企业 生命 web 端口 ip swap rrdtool 开源软件 Node.js CTO XML Uber http IOS update tab shell 集群 UI Google 空间 Docker 开源 主机 免费 ssh 定制
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

