人工智能继续进步的关键,自然语言处理概述
作者 :Javier Couto
机器之心编译
参与:吴攀、李亚洲
从上世纪五十年代就已经出现的自然语言处理有着怎样广泛的应用?从语言学的角度来看, 无处不在的自然语言处理 又是如何理解文本的?符号和统计哪一个是最好的 NLP 方法?这篇文章对自然语言处理作出了概述性介绍。
如果一台计算机能够欺骗人类,让人相信它是人类,那么该计算机就应当被认为是智能的。——阿兰·图灵
当我还是个孩子的时候,我读了 Jeremy Bernstein 的一本书《分析引擎——计算机的过去、现在和将来》。在图灵机(Turing Machine)或加法器(Pascaline)等迷人的概念之间,Bernstein 提到机器翻译是计算机可以执行的一种任务。试想一下:一台能够理解语言文本并拥有将其翻译成另一种语言所需知识的机器。
机器能像我们人类一样理解文本吗?我知道,这听起来有点难以置信。而且多年以来那对我来说就像是魔术,直到我发现了一个解决这类问题的领域——自然语言处理(NLP:Natural Language Processing)。是的,通过人工智能、计算语言学和计算机科学的力量的结合,NLP 让机器可以理解自然语言,这项任务到目前为止都还只是人类独有的特权。
第一次应用 NLP 是 20 世纪 50 年代从俄语到英语的机器翻译。那时的结果不是特别好,而接下来的几十年中还有以下一些案例说明了该领域的限制:当《圣经》中的句子「The spirit is willing but the flesh is weak(心灵固然愿意,肉体却是软弱的)」被翻译成俄语后再被翻译回英语时,结果是「The vodka is good but the meat is rotten(伏特加很不错但肉烂了)」。好吧,这只是一个主要受直译的缺陷所启发的故事,但它通常被认为是一个实际的案例,多年以来一直在败坏 NLP 领域的名声。
自 20 世纪 50 年代以来,人们已经取得了很多进展,而当互联网从友好的计算机小型社区成长为可利用数据的巨型资源库时,NLP 就变成了经济和社会发展中的一个主要问题。我撰写本文的目的是给出该领域的一个简要介绍,并尝试解释我们日常所用的一些应用背后的一点「魔法」。本文的目的不是给出关于该领域的广泛而深刻的见解,也不会是给出正式定义或精确的算法和技术。这只是一篇概述,而且如果这些内容能够激发你对这一已让我着迷多年的领域的好奇心,我就会非常高兴了。
即使我们不知道,但NLP无处不在
自然语言处理方面让我吃惊的一件事是尽管这一术语并不如大数据(Big Data)或机器学习(Machine Learning)那样流行,但我们每天都在使用 NLP 应用或受益于它们。下面是 NLP 应用广泛使用的一些例子:
机器翻译
也许你已经使用过机器翻译并且现在它对你来说似乎是一个自然的功能:Twitter 上的地球图标、Facebook 帖子中的「查看翻译」链接、谷歌和必应的搜索结果、一些论坛或用户审核系统。
我们已经远远超越了「spirit(心灵)」与「vodka(伏特加)」的故事,但翻译的质量是波动的,有时候并不好。机器翻译在一些特定的领域工作良好,即当词汇和惯用语的结构主要是已知的时。例如,当翻译技术手册、支持内容或特定的目录时,机器翻译可以显著地降低成本。
然而,在一般情况下仍有改进的空间。我想,你收到过你有资格享受退税或某个遥远国度的好心人坚持向你的拖欠账户转入数百万美元浮游资金的邮件。而其中一些是用糟糕的英语写成的,几乎无法理解,对不对?嗯,有时候机器翻译的结果会给你同样的印象。问题在于尽管这些诈骗邮件是故意写成那样以获得信任或通过垃圾邮件过滤器的,但当你试图理解用外语写成的指示列表或包装说明书时,糟糕的翻译真的会成为一个问题。
让我们假设你正在旅行,而且你必须处理以下文本:
越式炸春卷
即便有各种可能的术语和语法错误,但有一个拍张照片就能得到以下译文的应用难道不是很好吗?
Vietnamese fried spring rolls(直译为:越南的炸过的春天卷)
自动摘要(automatic summarization)
和机器翻译一起,自动摘要提出于 20 世纪 50 年代:对于给定的文本,目标是获得一个包含了其中最重要信息的简化版本,一个可以通过提取(extraction)或抽象(abstraction)得到的摘要。
基于提取的方法可以检测输入文本(通常是句子)的最重要部分,并将其提取出来构建一个摘要。除了决定每个句子的相关性问题,基于提取的摘要器(summarizer)还必须解决连贯性的问题。比如,摘要中的句子可以引用不存在于摘要中的句子元素,这个现象被称为悬垂回指(dangling anaphora):
「大众的新 CEO Matthias Mueller 为他削减了他的工作。Mueller 的大部分职业生涯都在大众集团所以他知道该公司的内部运作。现在专家表示他将不得不做出一些大且大胆的变革以让这家世界上最大的汽车制造商回到正轨。」
在上面的例子中,如果只有第三句被系统保留,那么读者肯定会问这个摘要所谈论的「他」到底是谁。
另一方面,基于抽象的方法意味着文本生成(text generation):摘要器并不从输入中复制文本,而是用自己的话写出其从文本中所理解到的内容。这个方法极其复杂,目前大部分可用的系统都使用的是基于提取的方法。
当涉及到给出一组期刊新闻的信息概述时,自动摘要是尤其让人感兴趣的。一些被称为多文档摘要(multi-document summarization)的方法可以将多个文档浓缩成一份摘要。这在避免来自不同文档的冗长和最大化多样性上是很重要的。一些其它方法将建立摘要视为关键词的简单列表,所以它们更像是关键短语或关键词提取器。你可能已经见过一些像博客平台或科学文献索引管理器这样的系统向你建议你的文章或论文中最重要的概念。
情感分析(sentiment analysis)
情感分析的目的是识别文本中的主观信息。它可以是一个判断、意见或情绪状态,而且最近它对那些想要了解自己在互联网上声誉的公司和名人来说是一个重大问题。用户对我们的产品有什么看法?他们怎么看待我的餐厅或我的酒店?他们对我们的客户支持服务满意吗?他们怎么看待这个竞赛?
最常见的情感分析应用是极性检测(polarity detection),即理解关于某个给定主题的文本是正面的、中立的还是负面的。这似乎很简单,而且在某些情况下确实如此:
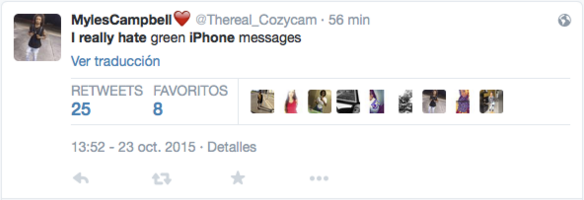
用户推文:我真的厌恶绿色 iPhone 信息
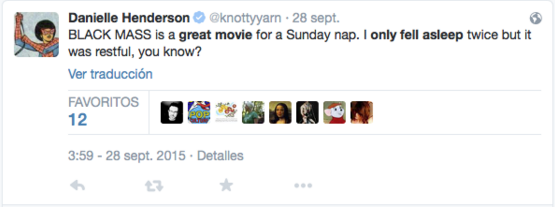
用户推文:《黑色弥撒》是一部用来星期天打盹的好电影。我只睡着了两次,但它就是为了让人休息的,你懂吗?
文本分类(text classification)
文本分类的目标是将预定义的分类分配给文本。在例如自动垃圾邮件检测等一些应用中,分类只有两个:垃圾邮件和非垃圾邮件。我们称这样的应用为二元分类器(binary classifier)。在其它情况下,分类器可以有多个分类,比如按主题组织新闻报道或按领域组织学术论文。因为我们有超过两种分类或分级,我们将其称为多类分类器(multi-class classifier)。而要是一篇博客文章谈论的是体育和娱乐又会怎样?一个分类器如何在多个选项之间选择正确的分类?嗯,那依赖于具体应用:它可以简单地选择最有可能的选项,但有时候为一个文本分配多个分类是有意义的。这被称为多标签分类(multi-label classification)问题。
文本分类中并非所有应用都面向语义。比如,我们可以使用一个分类器执行自动语言检测,即检测文本是用那种语言写成的。

《联邦党人文集》封面
一些应用特别复杂。其中我喜欢的一个是作者身份识别(authorship attribution):基于文本的风格,一个系统在合理的误差范围内确定其作者。你能想象吗?这样一个系统必须知道候选作者的集合,并且还要了解其中每一个作者的一组文本样本。为风格建模的方法有很多,而风格实际上是个非常复杂的概念。这些系统所使用的一些典型特征包括词频、词汇丰富度、句子长度和短语结构。尽管这是一个当前的研究主题,但第一个显著的成果则是在1964 年取得的:Mosteller 和 Wallace 的工作分析了有争议的《联邦党人文集》的作者身份。
会话代理(CA:conversational agent)
你记得《2001 太空漫游》中的 HAL 9000吗?HAL 可以说话、思考、还善解人意,他能识别面部、表达感情,甚至还能读唇语和撒谎。会话代理是能与人类进行连贯对话的系统。它可以以纯文本界面的形式呈现,或是口语对话系统。通常对话都有一个确切的目的。例如通常被称为自动在线助理或聊天机器人的客户服务 CA 能够处理用户的请求和问题,另外还有可以给出旅行建议的 CA 等。
你可能已经和某个会话代理交互过,可能一开始还不知道对方实际上是机器。我也猜想你在对话中意识到了这一点,因为这个对话缺少一些东西,一些人类的东西,对话中一定程度上的流畅性和不可预测性。问题是我们目前离创造 HAL 那样的智能实体还相距甚远。但如果我们专注于特定的主题或任务(只需解决某些受限的或程式化的语言),我们就可以得到相当好的结果。
1964 年,Joseph Weizenbaum 编写了一个可以模拟与私人心理治疗师的对话的计算机程序 ELIZA。以下是可能的对话的一个例子:
ELIZA:请告诉我什么一直在困扰着你。
你:没什么,我今天感觉很高兴。
ELIZA:多描述一点这些感觉。
你:呃,我只是高兴。
ELIZA:你的治疗让你高兴吗?
你:当然。
ELIZA:关于这个,告诉我多一点。
你:我不想谈论那个。
ELIZA:那让你感到麻烦吗?
这样的对话可以持续几个小时。ELIZA 使用的是非常基本的模式匹配技术,但在当时其影响是非常巨大的。自那以后,我们已经取得了很多进步。看看两个口语对话系统彼此交谈时会发生什么:
还有其它许多应用
NLP 还有其它很多真实世界的应用。你的电子邮件应用是否会自动检测事件并建议你将它们添加到日历中?嗯,这就是被称为信息提取(Information Extraction)的 NLP 任务。你会使用拼写检查器识别语法错误吗?你是否已经尝试过手写识别软件?像来自麻省理工学院的 Ask.com 或 START 这样的问答系统?基于内容的广告呢?苹果的 Siri、IBM 的沃森?你知道自 2012 年开始福布斯杂志就在使用讲故事的系统 Narrative Science 自动撰写网络文章吗?你最近是否看到过机器人领域的巨大进步?
即使我们不知道,但 NLP 无处不在。而且尽管 NLP 应用达到 100% 完美性能表现是非常罕见的,但它们已是我们生活的一部分,为我们所有人提供着宝贵的帮助。
但机器怎样可以理解文本?
呃,它其实不能……但它可以模拟理解。为了实现这一点,它必须在一定程度上能够了解自然语言的规则。NLP 处理语言的不同方面:音系学(phonology)、形态学(morphology)、句法学(syntax)、语义学(semantics)和语用学(pragmatics)。而它最大的敌人是歧义(ambiguity)。下面我们将看到不同层次的分析(我会将音系学放到一边,因为它不太直观,需要特定的背景)以及 NLP 系统通常如何应对它们。
词、词、词
首先需要理解的是词,特别是每一个词的性质。它是一个名词还是一个形容词?如果它是一个动词的屈折形式,那么它的不定形式是什么,以及该屈折形式使用了什么对应的时态、人称和数?这个任务被称为词性标注(Part-of-Speech (PoS) tagging)。让我们来看看下面的句子:
John bought a book (John 买了一本书)
那么,有一个直接的方法:我们可以使用一本包含了所有这些词、它们的屈折形式和词性的信息的词典,以计算下面的输出:
John/专有名词
bought/动词过去式
a/限定词
book/名词
好吧,让我们抛开这样一个事实:语言是一种极为丰富的活性实体,因此我们永远无法知道所有的词。如我们所见,即使对最简单的句子而言,这种方法也没有用。bought 这个词也可作形容词,book 还可以是一个动词或作为字母(在这种情况下它的词性是名词)。作为人类,我们通常可以解决这种歧义。但试试解读下面的句子:
Will Will will the will to Will? (可译为:Will 将会想把遗嘱给 Will 吗?)
真正的 NLP 应用通常使用两类方法执行任务:符号的(symbolic)和统计的(statistical)。符号方法由一组为不同语言现象(language phenomena)建模的规则集合组成,这些规则通常是由人工编写的,但有时也是自动学习到的。统计方法通常使用机器学习算法来学习语言现象。
Brill 标注器可能是最广为人知的基于规则的词性标注器。它使用考虑到语境的转换规则。首先分配一个词性标注(最常见的),然后应用规则以得到正确的输出。所以如果在上面的例子中「bought」首先被标注为了形容词,可以用一个规则对其进行校正:
如果前面一个词的标注是专有名词,那么:形容词→动词
统计方法将词性标注看作是一个序列标注问题。其基本思想是:给定带有各自标注的词的序列,我们可以确定下一个词最可能的词性。在例子中,如果我们已经看到了「John bought a」,而且知道它们的词性,那么我们就可以肯定地说「book」是名词而不是动词。这非常有意义。现在已经有隐马尔可夫模型(HMM)或条件随机域(CRF)等统计模型了,这些模型可以使用有标记数据的大型语料库进行训练,而有标记的数据则是指其中每一个词都分配了正确的词性标注的文本。
从词到结构
好了,我们的 NLP 应用知道怎么处理词了。比如,它可以在一个文本中找到动词「buy(买)」的所有实例。接下来的问题是:谁买了什么?对此我们将需要句法分析。那是个艰难的问题,有时甚至对人类来说也很困难。比如在下面的句子中:
I saw a man on a hill with a telescope (译者注:这句话有多重歧义,可译为「我看见山上一个带着望远镜的男人」或「我在山上用望远镜看见一个男人」或「我用望远镜看见一个男人在山上」或「我看见一个男人在有望远镜的山上」)
我有望远镜还是那个男人有?还是说望远镜在山上?我在山上还是他在山上?
如你所见,句法可能会非常棘手。我们必须了解词是怎么组成被称为词块(chunk)的单元的,以及这些词块是如何相互联系的。为此,我们使用语法。比如:
句子 → 名词词组 + 动词词组
名词词组 → 限定词 + 名词
名词词组 → 专有名词
动词词组 → 动词 + 名词词组
专有名词 → John
动词 → bought
限定词 → a
对于这种语法,一旦在一个被称为解析(parsing)的过程中对我们的例句进行了分析,就构建了一个解析器树(parser tree);然后我们就知道是「John」买了「a book」。语法可以人工编写,也可以从树库(treebank)学习到,树库是指用解析器树注释过的文本语料库。
获取词的含义
幽默格言「Time flies like an arrow. Fruit flies like a banana.」(译者注:fly 做动词表示飞行,做名词表示蝇。这个格言有多种译法,最正常的是:时光飞逝如箭,果蝇喜欢香蕉;最不正常的是:时间苍蝇喜欢箭,水果像香蕉一样飞行)完美地说明了语义歧义的复杂性。语义歧义有两个主要问题:
1. 多义词:具有多种含义的词
2. 同义词:具有类似含义的不同词
此外还有一些其它的重要的语义关系,如反义关系和上下义关系,但多义关系和同义关系通常是最有意义的。
词汇语义学(lexical semantics)处理以词为单位的含义,而组合语义学(compositional semantics)研究的是词怎么结合组成更大的意义。所以存在几种语义学方法,这仍然是 NLP 的一个重大的开放问题。
词义消歧(WSD:word sense disambiguation)试图确定给定句子中多义词的含义。让我们以下面的句子为例:
The tank is full of soldiers.
The tank is full of nitrogen.
(译者注:tank 有多个含义,这里用到的两个含义是坦克和罐子。上面两个句子可正常地译为:「坦克装满了士兵」和「罐子充满了氮气」。)
如你所见,这确实是个非常困难的问题。在上面两个句子中,词性标注和句法都是一样的。一个 NLP 应用如何知道每个句子中「tank」的含义呢?嗯,可以使用一种深度的方法。它需要关于世界的知识。比如说:一个罐子通常不装人。当然这成本太高了,所以更为常用的是浅度的方法:对于句子中给定的 tank,它周围的词是什么?这是有道理的:当我们看到词「soldiers(士兵)」或「nitrogen(氮气)」时,我们人类可以确定这是什么 tank。所以词的共现(co-occurrence)可被用来消除歧义。这个知识可以从每个词的含义都被正确标记的语料库中学习到。
词义消歧领域内的大部分应用都是通过使用 WordNet 执行的;WordNet 是一个非常大的计算词库,其中的名词、动词、形容词和副词各自被组织成了同义词的集合——同义词集(synset)。每一个同义词集代表一个独特的概念。比如,tank 有五个名词同义词集和三个动词同义词集。和我们上面例子相关的两个同义词集分别是{tank, army tank(陆军坦克), armored combat vehicle(装甲战车), armoured combat vehicle(装甲战车)} 和 {tank, storage tank(储存罐)}。
你可以在线试试 WordNet,看看什么词可以是多义词。也可能想看看其它相关的语义资源,如 FrameNet 或 ConceptNet。
关于组合语义学,事情就变得有点复杂了。首先,其中的关键思想是组合原则(principle of compositionality),整体的意义可以通过部件的意义建立。在组合语义学中,该部件通常是指句法分析(syntactic parse)的成分。所以,为了理解一个句子,我们构建它的逻辑表征。我们可以使用一阶谓词逻辑(first-order predicate logic),其中谓词有特定的非歧义含义。让我们想象一位用户写出了以下的请求:
a hotel with sea view near San Francisco (旧金山附近的海景酒店)
要正确处理这个请求,该系统必须以非常精确的方式理解它。所以该系统可以构建该请求的以下逻辑表征:
∃x Hotel(x) Λ View(x, Sea) Λ Near(LocationOf(x), LocationOf(SanFrancisco))
然后该系统可以使用 Prolog 这样的编程语言来计算结果。当然,这在一般情况下非常困难且昂贵,而且全局意义并不总是能够从部件的意义中派生出来,但在有限制的领域内,我们可以得到相当好的结果。组合语义学仍是一个悬而未决的问题,它也是 NLP 领域当前一项关键的研究课题。
关于语用学的词
关键不是你说了什么或怎么说的,而是语境。语用学(pragmatics)研究的是语境对意义的影响方式。想象一下对话:
JOHN: You are an idiot. (你是个白痴。)
PETER: Oh, thanks, that’s very kind of you. (哦,谢了,你真是太好了。)
一个 NLP 应用应该认为 Peter 觉得 John 的话是好话吗?要是 John 只是在开玩笑呢? 讽刺和挖苦是非常复杂的机制。NLP 领域有尝试特征化它们的研究工作。比如,我们可以训练一个分类器来确定某条推文是否是讽刺的。特征可以包括词频(假设不可预测是讽刺的一个信号)或某些形容词的使用(假设夸张也是讽刺的一个信号)等。但尽管目前已有一些有趣的结果,这仍然是一个开放的问题,还有很大的提升空间。
所有这些分析都是所需的吗?
并不一定。这依赖于具体的应用。例如对于垃圾邮件检测,你很可能会在词之上训练一个朴素贝叶斯分类器(Naive Bayes Classifier)。所以基本上,该应用需要知道的是如何将文本分割成词,这个过程被称为标记化(tokenization)。另一方面,如问答系统或信息提取系统等复杂的应用可能会需要执行形态分析、句法分析和语义分析才能得到恰当的结果。
符号或统计,最好的方法是什么?
简短的回答是:它们都不是。关于这个问题的讨论有很多,其中立场激进的讨论是不可忽略的。据报道,曾领导 IBM 语音识别团队大约 20 年的 Fred Jelinek 曾说「任何时候只要语言学家离开团队,识别率就会上升」,这句话常常以一个更为通顺的方式被引用:「每次我开除一个语言学家,我们的语音识别系统的性能就会提升」。另一方面,著名语言学家 Noam Chomsky 曾在 1969 年表示「必须承认,在这个词的任何已知的解释下,『句子的概率』的概念是完全无用的。」
符号方法主宰了所谓的NLP 的第一个时代。而从 2000 年代开始,统计方法变成了现实,而多年以来,即使更多的批评者也不得不承认统计的 NLP 能给出非常好的结果,而且有时还优于纯符号的方法。
统计方法的优点是你可以使用一点数据做很多事。所以如果你想开发一个 NLP 应用,你可能会想从这类方法开始。我推荐你阅读 Raúl Garreta 关于机器学习的博客,他给出一些通常来自机器学习领域的统计方法的案例。
统计方法也有其局限性。当基于 HMM 的词性标注时代开始时,表现正确率大约是 95%。嗯,这看起来是个很好的结果,5% 的错误率似乎是可以接受的。也许吧,但如果你考虑每句话平均 20 个词,5% 的错误率就意味着每句话中都将有一个词被错误地标注了。自那以后,不管是通过更好的训练资源还是尝试条件随机域(CRF)等其它模型,正确率得到了提升;但总会有必须处理的错误率。在一些情况下,错误率非常低以至于可以认为该问题已得到了解决。自动垃圾邮件检测就是其中之一。
另一方面,尽管符号方法更为昂贵,但它们却更容易被人类理解,且不需要概率学和统计学方面的特定背景。此外,在某种程度上,使用这种方法能让你有更好的控制:在测试之后如果你发现了一些错误或缺失的东西,你可以删除或改变规则或创建新规则。统计方法则没那么直接和直观:你可以提高你的训练语料库的质量,你可做特征工程以确定更好的特征,你可以创建新的特征;在任何情况下,你有时都会有在和黑箱打交道的感觉。
所以符号方法和统计方法哪种更好?答案依赖于具体的应用、目标、现有的资源、人的背景、预算等许多变量。你也可以尝试混合的方法。你可以使用统计方法自动创建规则(就像 Brill 词性标注器做的那样),然后最终手动组织它们。或者,你可以手动向统计方法中注入构建知识以改善结果。例如,你可以编写一个规则声明:名词词组永远不能以限定词作为结束。这样就算你的系统是用非组织化的语料库训练的,也不会造成错误。
结语
十五年前,要让一家 NLP 公司说未来他们的产品不能以绝对的准确度工作是很困难的。但时代已经改变。随着更好的搜索引擎、博客、社交网络、电子商务的到来,社会慢慢开始理解,即使 NLP 还有待完美,但它已经为我们的日常提供了宝贵的帮助。
NLP 是一个年轻的领域,充满了希望,而且还有一个持续开发新算法、技术和资源的国际化社区。它正在快速进步。最近使用深度学习的一些成果惊人地改善了一些艰难的 NLP 任务。人工智能的进步和互联网的涌现,两者之间的结合促使 NLP 达到了几年之前无法想象的程度。
在 MonkeyLearn(使用机器学习做文本分析的平台),我们相信 NLP 是一个可以改变游戏规则的技术,而且它还将塑造互联网的未来。是的,NLP 是一个困难的领域,而那正是我们想要改变的。我们与 MonkeyLearn 的目标是让世界上的每一个软件开发者都能够使用 NLP,并且还希望能够带来下一代智能应用。想象一下,通过将通常仅限于数据科学家的领域转变成一种每个人都能够使用的技术,那会有怎样的无尽可能!
未来我们将看到 NLP、机器学习和人工智能能走多远。有时候我会想,我们会看到随处可见的机器都能通过图灵测试的那一天吗?
来源:机器之心微信公众号
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

