详解:全球最大正版流媒体音乐服务平台Spotify是如何管理服务器的
Spotify是全球最大的正版流媒体音乐服务平台,我们拥有大约1.2万台服务器,每当用户登录Spotify,浏览个性化推荐 Discover Weekly 列表,并播放某个媒体的时候,就有其中的一些与之互动。

出于历史原因,Spotify并未使用AWS之类的公共云服务,而是选择了在私有物理服务器机组上运行核心架构。我们的服务器机组已经达到了硬件配置最小化,这些服务器分别位于全世界的四个数据中心。在基于容器的持续集成和持续部署方面(CI/CD),我们大量运用了 Helios 模型,每台服务器一般都有单独的用途,也就是说大多机器都只运行一个微服务单例。
在Spotify,我们认为每个团队都有“运营责任”:即微服务的构建者也负责它的部署与相应服务器的管理。也许大家会以为,让数以百计的工程师管理数千台服务器,还要保证可靠性,情况一定会非常复杂。
在本文中,我们将会详细描述Spotify的服务器管理架构进化史,并在技术实现上、这些实现对生产率的影响、对工程师情绪的影响方面讲述一些细节。
2012年以及之前——前序
Spotify那时还只是一家小公司,想要有一只传统、集中化的运营团队还是可以实现的。虽然这只团队一直不停地忙于“救火”事宜,同时要完成所有的运营任务,然而他们很聪明,知道不能一直只靠手动来管理日益增长的服务器群。
在Spotify,首批用于服务器管理的工具之一就是著名的ServerDb:ServerDb负责追踪细节,比如服务器的硬件规格、所处位置、主机名、网络接口以及硬件的唯一名称,每台服务器都有一个“ServerDb状态”,比如“使用中”、“已坏”或“安装中”。最初,我们只有一个简单的SQL数据库和一系列脚本,并通过 全自动的安装程序(FAI) 来完成服务器的安装,管理一般是通过可提供串行控制台访问与电源控制的 moob 来执行。我们所使用的DNS zone数据,大多是由人工精选出来的,并且需要手动推送才能生效。一旦基本操作系统安装完毕,所有服务器都会由(现在仍是) Puppet 来管理。
之后该堆栈有很多部分都被替换掉了,FAI先是换成了 Cobbler 和 debian-installer ,后来又换成了我们自己开发的 Duck 。尽管在配置过程中有很多步骤都是自动执行的,但很容易出错,仍旧需要人类的监督。想要对20台新服务器进行配置,都可能会成为不可预知且非常耗时的工作。工程师们在 JIRA 上创建资源请求,等待我们来分配,而满足这个请求可能需要几周乃至数月的时间。
2013年末——架构与运营部落
Spotify一直很偏爱 敏捷 团队(按照Spotify的说法就是小组)。在2013年末,运营团队被并入了新成立的架构与运营(IO)团队,在运营中针对特定的问题再组建新的小组,而我们的小组全权负责配置和管理Spotify的服务器。
一开始,我们预想的是完全自助式的机器管理服务,但由于小组工作非常繁忙:我们应接不暇地处理请求新机器、机器录入(在ServerDb中记录新的服务器)等事务。于是我们决定从小处开始,先将一些最小可行产品(MVPs)拼凑起来,让最主要的痛点自动化,以便腾出时间做些更重要的事。
我们的努力集中在下面这三个方面:
DNS推送
DNS推送是我们最早获得成功的项目之一。起初,运营团队必须手动编辑DNS zone文件,提交版本控制,再在DNS master上运行脚本,以编译部署新的DNS zone数据。我们逐渐将这个过程自动化:首先我们构建了一个工具,从ServerDb自动生成大部分的DNS zone数据;然后再添加集成测试与代码review机制,从而保证所更改内容的质量。不久之后,我们解决了难题,让推送自动化——我们创建了Cron任务,来自动触发上述过程。最终,类似为新的ServerDb子域自动创建DNS zone之类的工作总算能够自动搞定了。
服务器录入
在我们小组负责相关任务的时候,ServerDb成为了受PostgreSQL支持的RESTful网络服务。通过对数据中心团队手工整理的CSV文件进行分析,它记录下了数百个服务器,这些文件包含有类似机架位置、MAC地址之类的信息,如果让技术人员来查看,很容易错读;而且我们还用女性名为每个服务器分配了唯一静态标识符,上千台服务器占用了大量的命名空间。
我们的目标就是为了让录入过程完全自动化,不再需要人类介入。我们将网络引导基础设施从Cobbler切换到 iPXE ,后者可以根据服务器的ServerDb状态来决定如何引导:将“使用中”的服务器引导到生产OS,将“安装中”及ServerDb未知的服务器引导到Duck所创建的微型Linux环境(我们称之为pxeimage),然后通过一系列脚本执行安装或录入。
为了让服务器在不需人类介入的情况下完成录入,我们放弃了以女性名命名服务器的做法,而是采用了各机器唯一、程序可发现的序列号。在未知服务器上运行侦查脚本来确定序列号、硬件类型、网络接口等信息,并自动在ServerDb上执行注册。
配置请求
简单来讲就是鸟枪(Provgun)换炮(provcannon)。早期我们通过脚本Provgun来自动读取JIRA上的“配置请求”事件,并发送能满足相应资源请求的必需命令。配置请求包括:位置、角色、硬件规格以及服务器数量等信息,例如“在伦敦安装10台高IO的服务器,角色设定为fancydb”,则Provgun会在ServerDb中找到合适的服务器,为它们安排域名,然后通过ServerDb来请求安装。
ServerDb通过 Celery 来调用 ipmitool ,并引导目标服务器通过网络引导启动到pxeimage来执行安装。在安装完毕并重启新的OS之后,Puppet会根据服务器的角色做进一步配置。
我们最开始提出了一系列问题,包括“能否将provgun放在cron循环中”,就像解决DNS推送那样?不幸的是,provgun不够智能,无法判断所运行的命令是如何运作的,我们担心这中间反反复复的工作反而会增加工作量。
最后,我们采用了新的解决方案:provcannon,它实际上是Python版的provgun,通过监控所有的安装进程以确保安装能够成功执行。同时,对指数退避而导致失败的安装进程执行重试,替换那些一直无法安装的机器。同时配置provcannon,以每天2次重复执行配置请求。

影响
经过我们的努力,这时候DNS改变、机器录入和配置请求都已经自动化了,从而将资源处理的等待时间从数周减少到了数小时。我们不再需要执行DNS更新了,从而将运营小组从无聊、易出错的工作中解放出来,将精力集中到进一步改善同事们的周转时间和体验上。
2014年中期——喘息空间
在最初的权宜解决方案部署之后的几个月里,整个小组都风平浪静。Spotify的老员工都很高兴整个周转周期缩短了,但用惯了AWS和类似平台的新员工却不太满意还要等上几个小时。由于整体基础设施可靠性不足,我们只让安装过程实现了自动化,而控制故障机器以及将多余服务器“回收”到可用池中这些工作,仍需要我们读取JIRA列表并运行脚本,因此是时候实现我们的宏伟愿景——为Spotify的工程师们实现自助服务平台与API,根据需求管理机器。
Neep
我们以原堆栈为基础开始建立服务,这个服务就叫做Neep,负责协调机器的安装、回收及重启工作。在每个数据中心都有特定的机器运行Neep,并以带外数据(OOB)的方式来管理网络。由于吃过了Celery的亏,我们将Neep打造成了基于 RQ 的轻量级REST API,也就是一个基于Redis的简单任务队列。出于务实考虑,我们选用了 Pyramid 作为web框架;并将ServerDb继承为Pyramid服务,希望能轻装上阵。
{ "status": "finished", "result": null, "params": { }, "target": "hardwarename=C0MPUT3", "requester": "negz", "action": "install", "ended_at": "2015-07-31 17:45:53", "created_at": "2015-07-31 17:36:31", "id": "13fd7feb-69d7-4a25-821d-9520518a31d6", "user": "negz"}上面是某个Neep任务的案例。
provcannon的大部分逻辑在管理机器安装与回收的Neep任务中都是可用的。从Neep的角度来看,这些任务同样有效。Neep简单地将机器的ServerDb状态设置为“安装”或“回收”,并请求pxeimage执行相应操作,然后重启网络。为了简化交付的复杂度,我们将对ipmitool的调用换成了OpenStack的 pyghmi IPMI library。
Sid
最初我们在测试Neep时,通过provcannon来触发Neep的任务,等到在新堆栈中解决了一些bug之后,我们将两者结合在一起,从而造就了Sid。
Sid是现在我们的工程师在Spotify用来请求和管理机器的主要工具,它是另一个将从ServerDb获得机器存储数据、从Spotify的内部微服务数据库获得的角色数据、以及在Neep中的机器管理任务三项合一的Pyramid REST服务,从而使得squads具有了服务管理性能。Sid拓展了provcanno的部分逻辑,以寻找和分配最合适的机器来满足配置请求。Sid优秀的 Lingon UI可以轻而易举地在API之上构建,并作为配置请求接口来取代JIRA。
触发Sid配置请求

响应Sid的配置请求
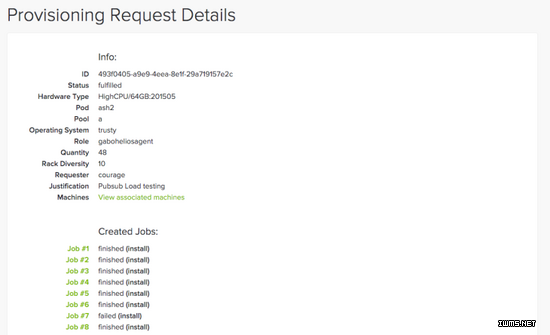
在Sid中管理机器
影响
在Spotify公司,Sid和Neep并非唯二获得改进的堆栈,我们还重建了DNS zone的数据生成过程,并且在安装时定期应用自动生成的OS镜像,而不再是只在运行时执行Puppet。
结果:响应配置或回收请求的时间可在数分钟内完成,而不再需要数小时。其他小组也基于Sid的API构建了工具,以实现机器群的自动化管理。在Spotify的配置堆栈上,Sid是架构与运营中受到赞誉最多的服务,至今为止它已经完成了3500个配置请求,发出了2.8万个Neep任务,包括安装、回收及重启机器,且成功率高达94%。考虑到数据中心各个机器固有的不可靠性,这个数据已经很优秀了。
2015年中期——最新水平
在2015年,Spotify决定逐渐完成迁移,不再使用自己的物理机器,而改用 谷歌云平台(GCP) 。这一转变对我们提出了挑战:为多团队的工程师管理大量的云计算服务设想方式,同时还不能互相重复。
Spotify Pool管理工具
为了避免 “非主观意愿” 所产生的陷阱,我们小组评估了GCP所提供的管理性能,希望这个工具能够执行Spotify的观点与模式,以便为工程师们提供简单明确的办法来获得计算性能。我们认为开发者控制台(Developer Console)非常强大,但过于灵活,很难引导工程师选择我们偏好的设置;而 部署管理器(Deployment Manager) 也很强大,而且也能执行我们的想法,但在测试中工程师发现它非常难用。
在向谷歌发送了反馈之后,我们开始构建Spotify Pool管理器(SPM)。SPM是一个相对轻量的层面,是基于GCP的API根据Spotify具体情况所搭建而成的框架,其中提供了合理的默认预设值。工程师只需指定需要什么角色的机器、需要多少实例、以及放置在哪里,SPM就会确保能实现相应数量的实例,并通过谷歌的instance groups来管理,同时Pool可以根据要求来增大或缩小。
Spotify Pool管理器管理下的Pool 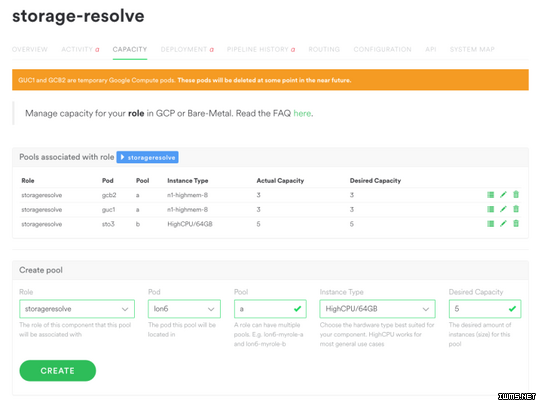
SPM是无状态的Pyramid服务,主要通过调用Sid和GCP来完成最繁重的工作。
物理池(Physical Pools)
Spotify不会立即取消物理机器群,因此我们在Sid后端建立了对Pool的支持机制。尽管Sid的配置需求模式对我们来说很有用,但太过于倚重个人机器。如果工程师们有办法让物理机器达到与谷歌实例群组类似的性能,是否能够加入类似自动替换故障机器,以及在过渡到GCP时生成随机域名这样的模式呢?Sid对pool的支持允许SPM管理GCE实例以及物理机器,能在无视后端的情况下提供同等的用户体验。
结论
在最近几年中,Spotify的机器管理框架一直是凸显迭代开发优势的范例。 网站 可靠性 与 后端 工程师 小组通过将多项工作自动化,提高了同事们的生产力,从而可以有效地执行迭代。我们将新机器申请需求的周转时间从数周减少到了数分钟,并大幅减少了Spotify在管理机器时所需的支持交互。

正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

