ArchSummit微课堂|构建大数据系统的前沿技术概述
引言
本文整理自ArchSummit微信大讲堂线上群分享内容;解释一下这次我为什么不是分享安全方面,反而分享数据方面的,ArchSummit北京2015分享的实际也是数据计算方面的技巧,只不过用在了风控场景上,这次我尝试把那些操作更加往底层架构上延伸一下,更加有逻辑去考虑这个话题。
正文
第一部分存储模型之前,先抛两个问题:
1)这些存储的数据结构,主要是来优化什么操作的?
2)SSD对于这些存储结构有什么样的影响?
一. 存储模型--读和写的取舍
一个好的存储结构,我们希望的是更新数据快,查找特定的数据也快,最好占用空间还小,一般来说,这算得上是对存储的终极要求了。
终极要求,这东西一般都是YY,但是,加上一定的限制条件,在特定的时期,数据大爆炸之前,单机时代,B树这个结构,可以算得上是银弹。基本上所有的关系型数据库系统都采用这种结构。SqlServer和Oracle都采用B树,Mysql,Db2还有informix采用的B+树,
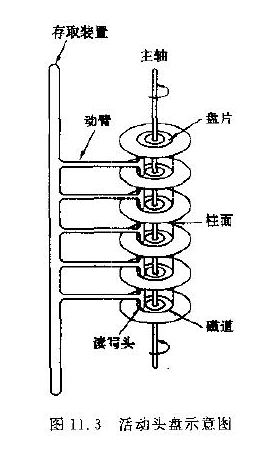
磁盘读数据和写数据的过程,1)移动磁头到对用的扇区,2)然后磁头接触磁道,写或者读数据,3)通过总线传输到内存或者寄存器。
磁头移动时间,十分之一秒的级别,读写的时间,按照普通磁盘,7200转的,差不多在百分之一秒级不到,还有一个耗时就是总线传输时间,这个基本可以忽略,在10的8次方分之秒。
另一个背景知识是,文件系统, 读写是有最小操作单位的块,每次I/O操作,都是整块操作。块大小,跟文件系统的格式有关,fat32,ext3/4等等,常见的块大小4096个字节,块大小可以调整,块,对应到物理的扇区。
通过上面的分析,有效的优化是降低磁头定位的次数;B树就是综合读写两方面的需求,提出的对磁头定位操作优化的结构。隐含的数据特征是:重查询,轻新增,并发写要求不高。总的数据量优先,单挑记录会被反复更新,这刚好就是单机时代的数据特征。在做关系型数据库表设计的时候,知道这点会比较有用。
B+树和B*树是B树的两种变形,B+树降低了中间节点的数据大小,同样的块大小,可以存储更多的数据,检索上更有效率,但是,实际数据读取上有妥协。B*树,相对于B数在节点的分裂,旋转,平衡方面有增强。
进入互联网时代,数据的特征有了变化,写多读少,数据具备热点时间。有效期之后的数据,就相当于传统数据库的归档。另外一个有利的变化,是内存变得很便宜,可以用足够低的成本hold住热点数据。这种前提下,顺序写做持久化,热点数据保持在内存中,并且在内存中进行排序,保证顺序写入的数据是有序的。
基于这样的思路,就有了LSM-Tree和COLA-Tree两种改进。区别在于LSM的MemTable保持固定大小,持久化数据的索引都有compaction阶段完成。COLA的思路,是Memtable就按照固定的逻辑完成索引更新。COLA里面是没有Memtable这个名称的。
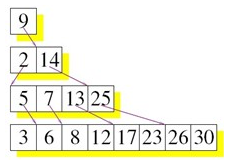
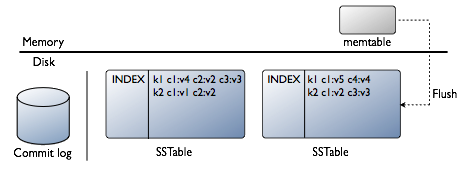
基本上现存所有的NoSQL都是采用LSM-Tree的思路,除了TokuDB。
Cassandrda和LevelDB,需要特别提一下,他们两个在Compaction阶段的实现,是参考了COLA的做法的,sstable做了分层合并。COLA在层之间,还引入了分形树(Fractal Tree)的实现,改进索引性能,Cassandra和LevelDB是没有,单层上数据检索,还是采用的BloomFilter和二分法。
二.实时计算-精度和速度的权衡
纯粹从性能对比,COLA跟B树算是公平对决,数据如下:块大小4098字节
查询Cola比B树慢12倍,插入速度是B树的340倍。
LSM不具备可比性,更多靠cache命中的效率。
之前提到的问题,SSD的影响,这么看起来,SSD对B树和Toku的影响要比LSM大(只是相对的),这些算法,对于ssd来说,算法对性能的影响并不重要,比较重要的反而是,通过算法降低,flash的读写次数,达到延长ssd使用寿命和减少损坏率。
除了需要保存检索数据,还需要对数据进行计算,流计算,实时计算的框架,已经是大数据里面到处可见,Storm,Spark Stream等等,这些流行框架更多是调度系统,真正的计算还需要自己来实现。
在我现在的实际工作中,常见的有点难度的计有exist是否存在,distinct count 去重计数,top n 等等在 window内部。
所有这些计算,对于内存都是很巨大的挑战。可行的做法,就是引入精度,接受概率。
这些做法,在数据挖掘的领域,已经是司空见惯的做法,比如关联规则挖掘的Apriori跟Fp-growth等都引入的概率的做法。
很多程序员其实也用过,一说就知道,Bloom Filter做去重,接受一定概率的误差,换来空间的减少,提升性能。
接下来介绍几个,我在实际工作中,用得比较多的方法,实际上是几个概念。
1)Bloom Filter
2)Sketching
3)基数估计
BF略过,大家都知道。Sketching,用于做频率估计,估算数据流中每个数据的出现次数。基本思路也跟BF差不多,通过互相独立的hash函数依次处理输入,接受一定程度的正负错判,估计值在一定概率内正确,这个概率可调整。这类方法的另一个优势是可以很容易实现分布式,能够合并。
Sketch有几个变种,basic sketch, counter sketch和counter min sketch,依次各有改进。
Bf和counter min sketch算是当前最优的top n的方法。Cms对于重复度高的效果较好,重复度不高了,有基于cms基础上的改进,counter-mean-min sketch。
上面在存储模型中间没有提到,cms还能够用在nosql的range query索引上,不追求精确度,在性能方面完爆B树。
基数估计也是类似的思路,用很少的空间,计算集合的势,常见的算法有Linear counter,LogLog counter两类,分别使用在重复情况比较明显和重复情况相对于总量来说较低
Redis在支持bitmap之后,在2.8.9之后,直接提供了hyperloglog的支持,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基 数。线性的counter也可以直接利用bitmap实现。Hash函数的murmur是比较可以无脑使用的实现。
具体的算法描述,大家可以问百度,不细说了,知道有哪些可用场景就好。我们主要用在风险检测的参数计算方面。
三.分布式持久化-CAP的妥协
对于分布式持久化的内容,也扯两句,我个人很喜欢Dynamo模型的对称结构,BigTable的管理节点实在是不美观。也就是zk和gossip+vector clock的战争,这种选择也就决定了各自在CAP和ACID中间能够达到的水平。
四.日志为中心的基础架构设计
ArchSummit全球架构师峰会 上我也推荐过kafka的作者写的文章,在推荐一次,个人觉得每一个做分布式系统设计的架构师,都应该读几遍才好。
给大家看这样一个图
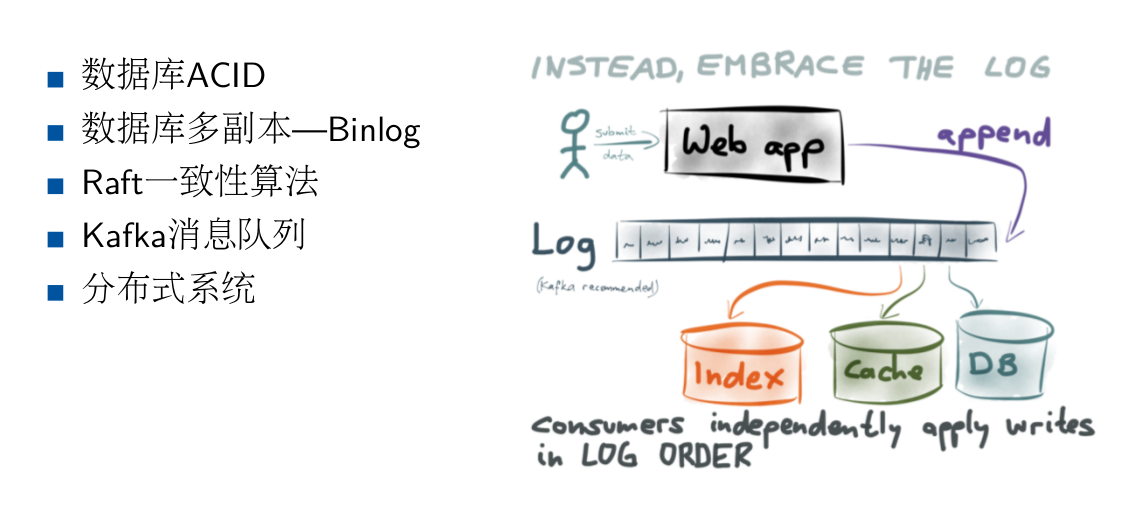
(点击放大图像)
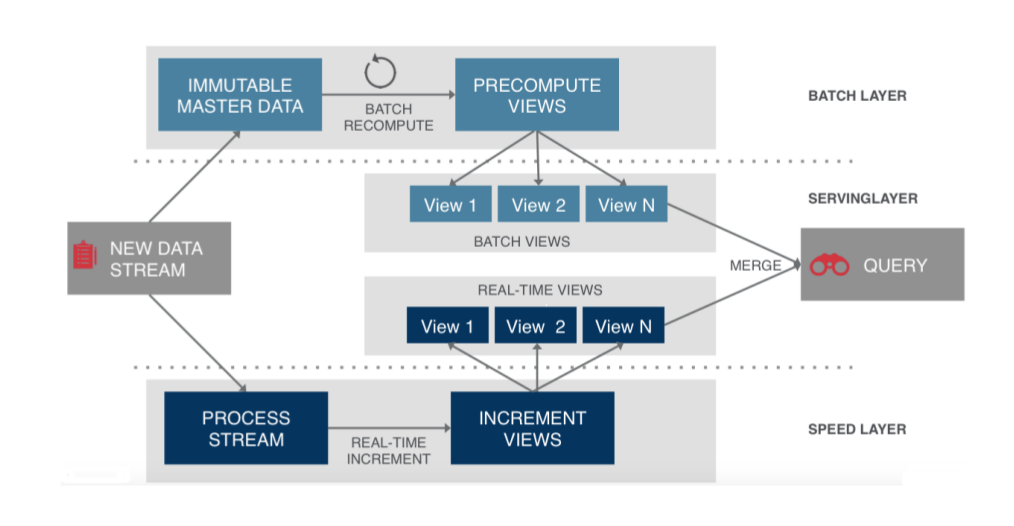
苏宁现在整体数据系统建设思路,差不多就是这样,通过日志,串行所有操作,避免冲突。基本上满足异地多活的需求。
中间过程,分实时计算,批量计算并且在服务层合并数据。
五.Q&A
Q1.您好,您在处理复杂的任务调度方面,有什么心得体会?
我自己看法,最看重的任务状态的保存或者说状态重现,至于运算能力的调度,现在的调度框架已经做得很好了。rdd在最大程度上保证了状态的可重现,这点上,是我最看好rdd,也就是spark的原因
Q2.你们代码是自动Review的吗?
代码review的问题,讲真,这块我们做得特别土,全人工的,而且还要人工两次,一轮是开发团队内部的。如果谁有好的自动化review工具分享,一定发红包。还有一轮是安全团队的代码审核。安全团队的代码审核倒是有些个工具辅助,但也只是辅助,fb开源的几个代码审核工具,实际上效果都不是很好。
Q3.storm和spark的应用场景有什么区别?
spark 跟 storm的使用场景,实际上,差不多类似作用的是spark和 storm stream,这两个系统,苏宁现在都在使用。最初采用的是storm,后来引入的spark stream原因很简单,仅仅就是为了跟spark更好的集成说道sprak的场景,跟rdd的特性有关系。简单的说,类似与kmeans这种多轮迭代逼近的模型,使用sprak会更加有效,且spark的数据科学方面的周边支持更多
Q.4日志输出是否有自研组件?所有业务线统一一个吗?主要输出哪些内容?
苏宁的日志输出是没有自研的,很普通的组合,flume 采集 kafka订阅 hdfs存储,所有业务线公用,并且汇总。内容和格式要求就是日志必须保证业务能够重放。实际上,只有核心业务能满足这个要求。
Q.5对SSD而言,现有的文件系统已经不太能发挥存储设备的最大速度,未来的SSD文件系统会是什么样?
SSD的文件系统,现在有些实验性的产品,主要是基于log struct FS,但是还不成熟。具体内容大家可以参考这里http://lwn.net/Articles/353411/。另外,现在还有些文件系统综合考虑hdd,ssd,自动地根据文件大小,读写频率写数据到ssd或者hdd里面。
Q6.对于Google任务调度系统Borg,您怎么看?
borg,不是很熟悉,没研究过,跟上面说的一样,我更加喜欢关注状态保持,资源调度基本就是哪个用得多就用哪个,我们团队有这方面的专家,这点我不擅
Q.7能否详细讲解一下sketch算法的计算过程,这个算法在苏宁有哪些应用?
算法的介绍,推荐一个blog: http://www.cnblogs.com/fxjwind/p/3289221.html 大家可以参考。Top n类型的计算基本都在用sketch,热点商品,网络流量模式识别,风控中的支付行为特征也在用。之前as上介绍的argo框架,也提供了sketch实现。
Q.9随着新硬件的快速发展,大数据系统当存储和网络不再成为瓶颈时,会不会呈现出一种新的形态?
这个话题其实吓了我一跳,太高端了,应该kk这样的预言大师才敢想的问题。我想到的第一个词是 grid computer,sun在很多很多年前就希望做成的未来。之前在开源项目JNODE搞文件系统的时候,就尝试去实现分布式的文件系统,比较早,受限在当时网络环境,没能成功。Sun是一个有情怀的公司,grid computer的模式跟科幻电影里面matrix母体是不同的,一个是独裁,一个是民主。悲观的想,未来可能是matrix母体,因为量子。
讲师介绍
季虎,苏宁IT总部安全研发技术总监,ArchSummit北京专题讲师,目前已构建了苏宁电商和金融的风控技术体系,此前,任阿里集团安全部高级技术专家,参与了AE,金融和集团的风控系统建设,并致力推进风控自动化和大数据风控实践。
本文根据ArchSummit微信大讲堂上邀请讲师,苏宁IT技术总监 季虎为大家线上分享内容整理而成, 长按下方二维码,回复“架构师”,获取参与方式,加入围观大牛线上分享,同步大会筹备近况……

ArchSummit 架构师峰会2016深圳站将于7月15-16举行,邀请了来自Uber、Twitter、Netflix、腾讯、百度、阿里等公司的50多位CTO和研发总监,为大家带来更多精彩的线下分享 ,更多精彩 点击这里 。
正文到此结束
- 本文标签: 参数 dist 任务调度 占用空间 产品 UI 需求 二维码 build kk 自动化 战争 金融 代码 Cassandra 线下 2015 db 互联网 map Google HTML Uber 文章 node 数据库 NOSQL 管理 程序员 同步 红包 db2 Oracle sql 大数据 CTO 开源 数据挖掘 tab 安全 开源项目 百度 http rmi struct apr redis 空间 开发 src 数据科学 mysql ip HDFS 数据 时间
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

