基于Hazelcast的分布式自增ID实现
在当前的互联网类产品中,如何高效可用的生成的一个全局自增ID,是一个比较有挑战性的工作。我见过的一般的做法其实就是时间戳再加固定长度的随机 字符串。这个方案其实有两个问题,一个是生成的自增ID的可读性,另外就是随机,并不是真正的唯一,它是一个碰撞概率的。其它方案,如依赖数据的自增 ID,如果多个库,可以通过不同的步长来实现可读的序列。不过,这其实性能上肯定不可能很高。另外,会有单点的问题。所以,果断放弃。在查看了目前比较成 熟的snowfake方案之后,感觉不错。下图是它的算法核心

分3段进行详细说明:
Snowflake – 时间戳
这里时间戳的细度是毫秒级。
Snowflake – 工作机器id
严格意义上来说这个bit段的使用可以是进程级, 机器级的话你可以使用MAC地址来唯一标示工作机器 , 工作进程级可以使用IP+Path来区分工作进程 。如果工作机器比较少,可以使用配置文件来设置这个id是一个不错的选择,如果机器过多配置文件的维护是一个灾难性的事情。
Snowflake – 序列号
序列号就是一系列的自增id(多线程建议使用atomic),为了处理在同一毫秒内需要给多条消息分配id,若同一毫秒把序列号用完了,则“等待至下一毫秒”。
原理其实不复杂,下面我们结合Hazelcast(高可用的分布式内存框架)来进行实现。
snowcase,基于hazelcast的自增实现。GITHUB地址https://github.com/noctarius/snowcast
为什么选用hazelcast
1 基于内存计算,速度得到了保证
2 数据可以持久化,服务重启之后,数据还可以读取。
3 每秒的并发可以支持W级别
代码示例
1 首先需要添加依赖
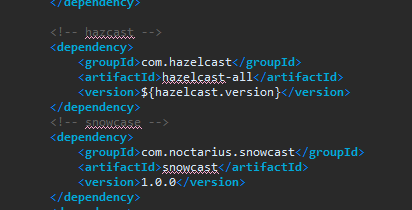
目前hazelcast的版本是3.5.5
2 在容器里面注入服务
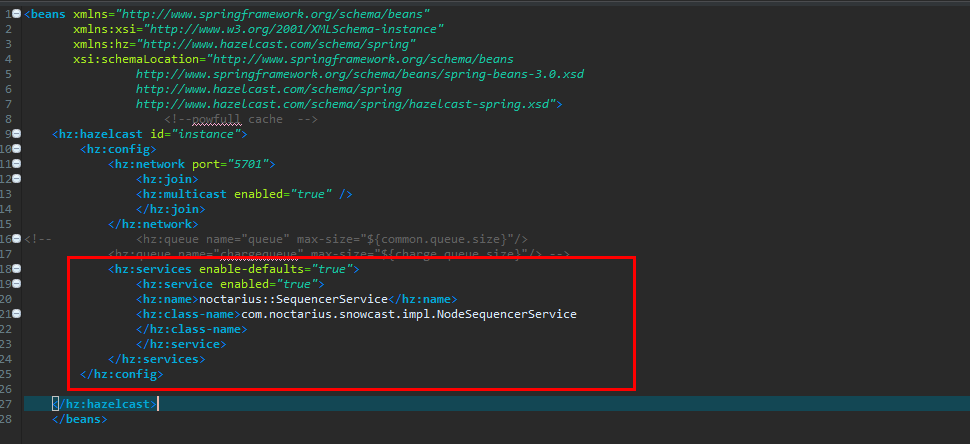
这个是例用hazelcast的spi接口,封装了自增的一个服务类
3 简单使用例子
snowcase客户端:

自增ID服务:
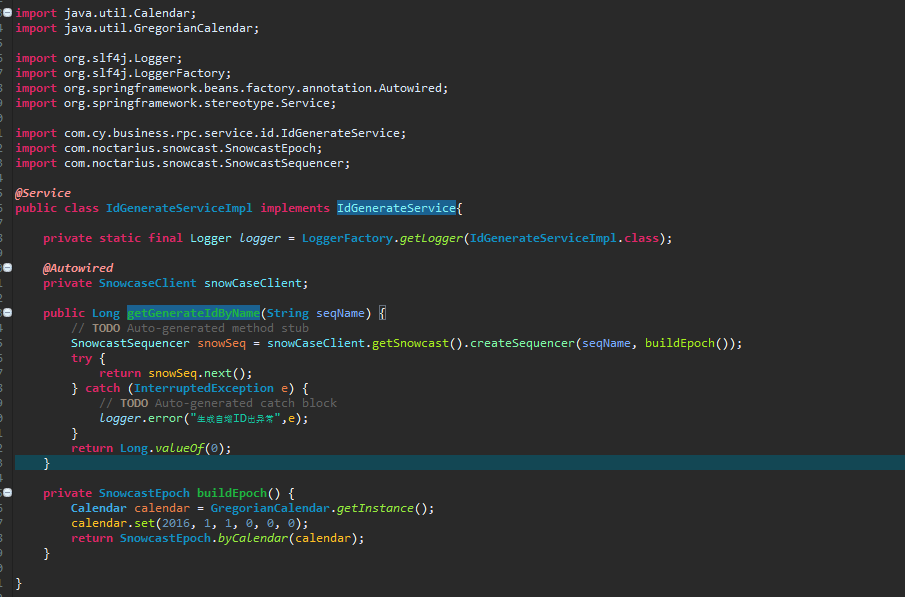
参照前面的原理说明,这里只传递了一个参数,就是时间戳。工作机器与序列号是使用的默认值 。其中工作机器的最大值是8129,最小值是128,序列号是hazelcast依据分布式自动生成的.至于seqName只是给这个自增ID取了别名。
CASE测试:
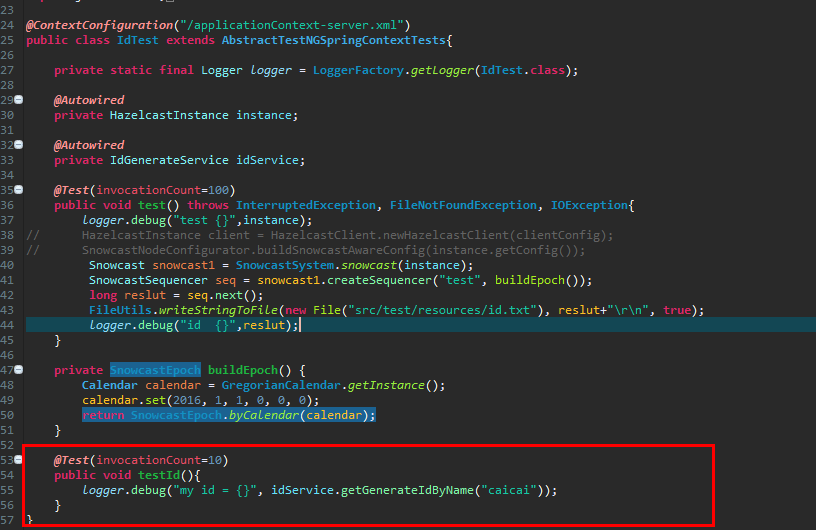
报告输出:
唯的一点缺陷就是因为它的长度是41BIT,这个方法的使用年限差不多是69年。
具体是这样算的:默认情况下有41个bit可以供使用,那么一共有T(1llu << 41)毫秒供你使用分配,年份 = T / (3600 * 24 * 365 * 1000) = 69.7年。
其中有一段,我还没有弄明白,T(1llu << 41),希望知道的同学提示,多谢。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

