机器学习里程碑:谷歌开源TensorFlow 0.8完全实现并行计算并原生态支持与kubernetes相结合

最近谷歌正式宣布TensorFlow 0.8 已经完全实现并行计算并原生态支持与kubernetes相结合,使得谷歌机器学习开源项目TensorFlow在支持集群化、并行化和分布式训练方面都实现了质的飞跃。
在上周谷歌的官方博客中,谷歌公布了谷歌实验TensorFlow 0.8 不同数目的GPU能够带来的加速效果:

图中显示100个GPU可以带来接近56倍的加速效果,并在65小时内将图片分类器训练到接近78%的精确度。
TensorSlow or TensorFlow?
我们先回顾一下TensorFlow的历史,早在去年年底,谷歌就已经将其深度学习系统TensorFlow开源。而且根据Github的统计,TensorFlow已经成为去年最受关注的开源项目之一。在它开源之初便引来无数试用者。然而刚刚开源的TensorFlow并没有引来多少好评,更有人戏称为TensorSlow,究其原因就在于单机的环境无法满足海量数据的需求。
反观谷歌内部,早在2011年谷歌就已经开始了对于深度学习的研究,如今已成功将其应用在搜索、广告、地图、翻译和YouTube等众多产品之中。通过深度学习,谷歌成功将语音识别的错误率降低了25%。而且谷歌大脑(Google Brain,谷歌内部版的TensorFlow)早就实现了和borg(谷歌内部版的kubernetes)的结合,可以轻松跑在上万台机器上。
上个月TensorFlow迈出了集群化的第一步( 原文链接 )通过Kubernetes实现了并行化。
如今谷歌正式宣布TensorFlow 0.8已经可以支持分布式训练,在提供多GPU测试结果的同时也提供了Kubernetes的测试脚本。随着TensorFlow和kubernetes两大技术的结合,这将对机器学习技术的实践产生深远影响。
什么是深度学习?
我们再来了解一下“深度学习”,深度学习这个词已经成为了很多人耳熟能详的概念,这个概念在AlphaGo战胜李世石之后更是变得世人皆知。那究竟什么是深度学习?
深度学习的本质就是通过复杂的模型结构或者多层非线性变化的组合来挖掘复杂数据中隐含的规律。理论上任何复杂的机器学习方法都可以作为深度学习的基础,但大部分成熟的应用以及研究都是以神经网络为基础。
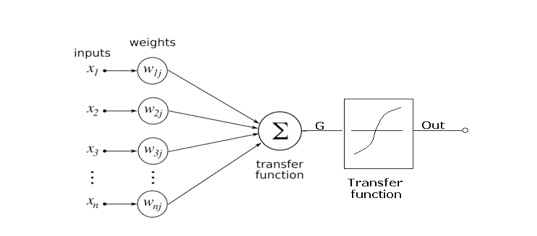
受人类大脑神经元结构的影响,神经网络希望模拟人类感知。一个最直接的例子就是图像识别,这也是深度学习最早的应用之一。人的眼睛在收到光的刺激之后,脑部不同的神经元会被激活,最后我们能分辨出眼前的东西是狗还是猫。
在神经网络中,neurons被用来模拟人类神经元的功能。上图给出了一个neurons的模型:将多个输入进行一系列变换后产生一个(或多个)输出。下图展示了如何将多个neurons有效的组织起来成为了一个神经网络。红色的输入层模拟人类接受刺激的器官(比如眼睛),蓝色的隐藏层(隐藏层可以有多个)模拟人类大脑的处理过程,最后绿色的输出层给出结论(比如是猫还是狗)。
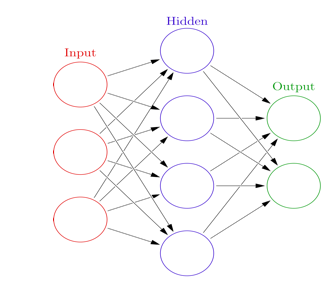
神经网络算法早在上世纪70年代就被提出,但在很长一段时间没都没有受到重视,直到最近才通过深度学习成为新宠。那么深度学习到底和传统的神经网络有什么区别呢?
他们最大的区别就在“深度”上。传统的神经网络的隐藏层一般比较少(一般在1-2层),而深度学习的隐藏层都比较深,微软研究院曾经尝试过上千层的神经网络。
理论上越深的神经网络的表达能力更强,这样就更有可能从复杂的问题中找到隐含的规律。但越深的神经网络对于数据和计算量的要求也越高,这也是为什么TensorFlow需要和kubernetes相结合才能带来更深远的影响。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

