分享回顾Love Data大数据夜修行│闵军:互联网大数据平台建设

分享记录:
大家好,我是闵军。目前就职于找钢网。此前曾在1号店,teradata,中国电信等单位工作。目前在数据行业已经摸爬滚打将近10年。
今天给大家分享的话题是,互联网行业的大数据架构。
这个题目很宽泛,很大,今天也不可能完全讲清楚,讲透。我重点讲几块:
1、互联网行业大数据的物理架构,比如Hadoop+DBMS,如何来分工;
2、数据仓库本身,如何架构,各部分的定位信息;
3、数据仓库到应用,数据改怎么流动?
4、应用本身,如何架构能做到降本增效,适应愈来愈多的多屏需求;
5、互联网行业,我们可以用数据来做什么。
第一次用这种方式和大家交流,看不到大家,不太适应。不知道前面大家是怎么交互的。这样,我保持我的节奏,先讲完,然后来看大家的问题。下面我们言归正传,从上面提到的5个方面来谈大数据架构问题。
1、Hadoop+DBMS架构在业界被广泛的使用
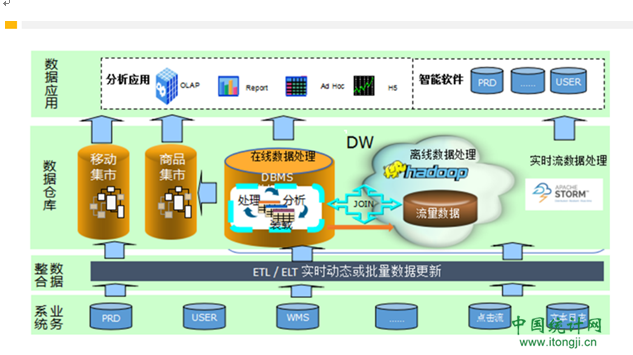
我们先看一下PPT,将业务系统数据抽取后,我们一般会放到Hadoop中,在这里我们做很多的事情。比如数据清理,数据整合等,下一页P我们将具体介绍。清理整合完成后,我们将数据导入到DBMS进一步做应用。
为什么这么安排?主要基于以下几个维度考量: 经济性,不考虑IOE,传统MPP如Teradata,尽可能用开源; 可扩展,考虑数据膨胀的可能性; 可用性,较成熟,有成功的实践案例。只有同时满足上述3点的架构,我们才认为是较为理想的选择。那么对标上述3点要求,我们看Hadoop+DBMS架构。经济性,扩展性:hadoop是目前最为经济,好扩展的大数据平台了,DBMS部分,我们也尽可选择如mysql的开源数据库。对于可用性,我们需要关注一下,我们知道hadoop的可用性不太好,特别是交互部分。但我们有DBMS作为补充啊,建议的做法是:充分利用Hadoop的存储及计算资源,利用DBMS的交互友好型特征。也就是说,数据底层部分,我们尽量使用Hadoop方案,靠近应用层,我们使用DBMS。
曾经也有同学问我,为什么不统一使用DBMS,搞这么麻烦?这是基于以下两点考虑:
1、非开源的DBMS,如oracle,DB2等,都是要花钱买的,不在我们的考虑范畴;
2、mysql等较为成熟,使用广泛的开源数据库,在大数据场景下,如表的复杂关联,性能会特别糟糕,也就是说,他不具备大数据的复杂计算能力。实践证明,即便是mysql的数据仓库方案,inforbright也是一个糟糕的选择。
还有同学可能会问,现在市面上广受关注的开源x86 MPP方案呢?我只能说,他们还处于初级阶段,成功案例太少,建议大家对他们加以关注,说不准哪天也会大行其道。
2、3层数据仓库架构可较好的平衡扩展性与易用性
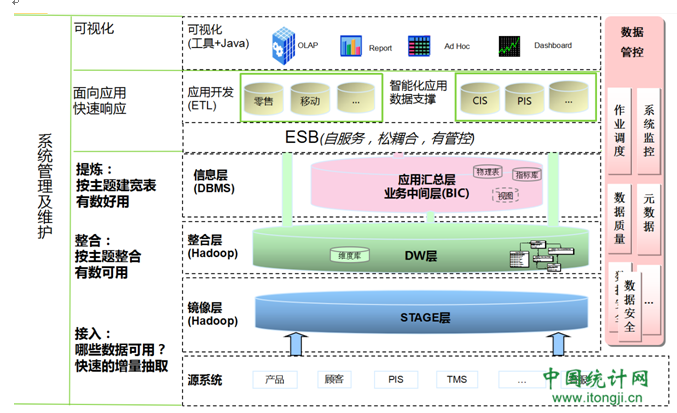
看一下PPT,前面我们提到了,数据底层部分,我们用Hadoop来承载,以利用高性价比的存储和计算资源。落到实处,镜像层和数据整合层,我们用Hadoop来承载。到了信息层,我们用DBMS,因为理想情况下,各类应用,我们都期望用这层来承载,也就是说,交互性要求高。
我们来看这3层。镜像层,我们关注的是如何高效的接入各类有用数据。一般来说,这层的表结构和业务系统基本相同,且不需要保留太久的历史数据。只是考虑到重刷数据的需求可能性,保留一周就可以了。整合层,重点关注数据的整合,以及规范化处理。这层模型是业务系统没有的,需要DW建设人员建模。这层的建模,我们多还是采用3范式方式,不太考虑数据的易用性,重点考虑数据的扩展性。此层完成后,我们可以做到有数可用,也可初步满足企业的one data要求。但前面说了,这里并不太关注数据的易用性,满足是可满足,用起来还是比较痛苦的,因为我们需要套多的表关联,太多的筛选过滤逻辑。也简单说下,整合和规范化处理是做什么吧。整合,我的客户信息,可能来源于多个业务系统,比如ERP,CRM等等。这里面的信息,可能有重复,且不能保证一致性。我们要做的,就是让这些信息统一起来,比如我常用来举例的,在ERP中,性别属性值,用F,M来标识;CRM中,这两个值可能试0,1。这需要我们统一起来。
再说信息层,注意这里开始提到信息,另外两层都是数据的数据。这里要做的是,从数据到信息的转化。对于数据的使用者,在此层可能满足需求的情况下,他们可能不太关注镜像层和整合层。但是作为建设者,我们必须关注:如果说信息层开始关注招式了,那整合层练的就是内家功夫。这一层,我们开始关注数据的易用性。如何做到易用?需要关注点:
1、模型容易理解;
2、数据容易获取。
那么在模型层面,我们采用维度建模,模型由维度和指标构成,这是最容易理解的建模方式了。数据层面,我们做充分的封装,将复杂的逻辑全部封装在整合层到信息层的逻辑中。举个例子,在电商行业,有个关键的指标叫做有效订单,他的定义是很复杂的,需要关注用户的付款方式,需要关注订单状态是否取消,需要关注用户购买时是否使用抵用券等等。可以想象,如果直接去统计这个数据,SQL没有20行代码你绝对搞不定。那在整合层到信息层的ETL处理中,我们封装这个20行代码的逻辑。你需要的时候,直接用就好了,2行代码的事情。
眼尖的听众可能看到了,在信息层,我写了视图,物理表。这里是说,信息层的实施是较为灵活的,不强求有实体表,不过在存储不成为问题的时候,我是建议用物理表来提升使用效率。还有一个,指标库,这是个什么概念?这个很重要,可以用来解决指标不能累加的问题,比如客户数,你今天去沃尔玛买了洗衣机,洗衣粉,对于洗衣机商家,他有一个客户,对于洗衣粉商家亦如此。但是对于沃尔玛,你只是一个客户,不是两个,亦即不能累计。指标库是用来解决类似问题的。时间问题,这个不展开来说。
3、理想的应用数据流是先封装在使用
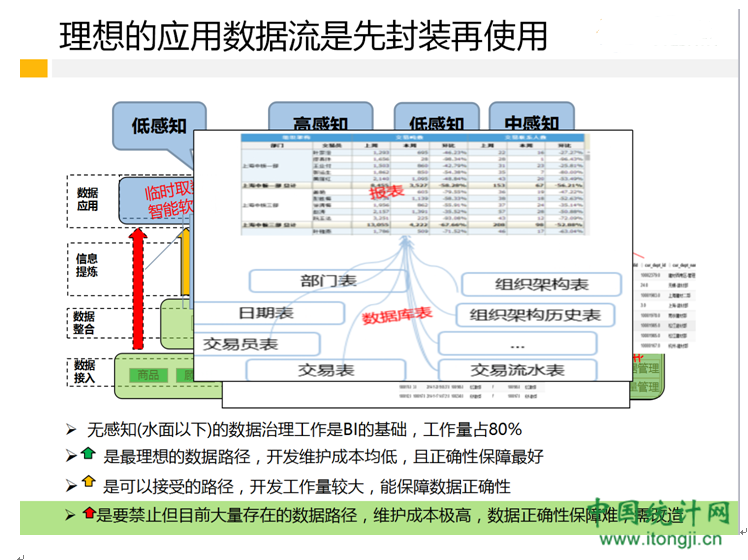
大家先看下PPT,这页PPT其实是上一页的补充。里面的信息比较丰富,但因为截图给大家,看不出来。我简单讲一下。首先,我将BI工作分成了几大块,DW/BIC建设,数据管理,adhoc取数,自动软件支持,可视化门户,数据分析等等。这里面,水面以上的,大家可感知的工作可能只有可视化出来的东西加上一些分析报告。除这之外,我们有超过80%的工作是水面以下的,大家感知不到的。这个事情,大家在负责DW平台时,需要对老大讲清楚,得到理解和认可,这点很重要。另外,关于数据流。做应用时,若信息层有数据可支撑,他是我们的不二之选。我们也可以使用整合层来支撑,前面说了,这里要付出的成本是开发工作量大。较好的办法是,若需求用到的数据有共性,其他地方也可以用到,强烈建议丰富信息层后再来做应用。直接从镜像层出应用,是我们要杜绝的,如果你大规模的这么做了,你将付出的代价是数据不准,维护成本高,应用间数据打架等各类问题,并将直接导致项目失败。
4、一套代码,多屏部署的应用架构
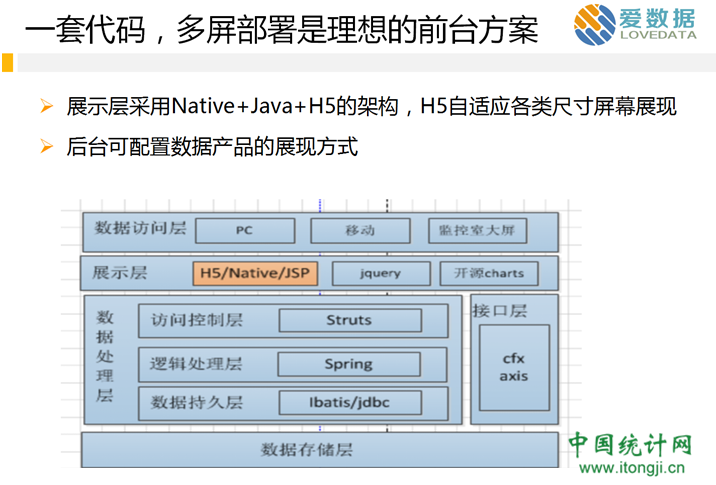
这个是我一直在推,也取得了一些成效的架构。其背景是,现在互联网行业,有PC,手机,监控大屏幕的可视化需求。老方法是,分别建设几套系统。导致的后果是,各系统独立维护,维护成本高。更为重要的是,若需要灵活的将内容挂载到各屏幕,或者要实现各屏幕之间的互动,成本会增加的非常厉害。为了解决这个问题,我们有了图示的架构方案。也即,用H5来作为可视化页面,自适应各类屏幕。然后,对手机端,PC端,我们只需开发容器及Native来放置H5报表即可。有了H5报表,有了容器后,我们可以经过简单的配置,即可将报表随心所欲的挂载到各类屏幕。
5、两个闭环一条链
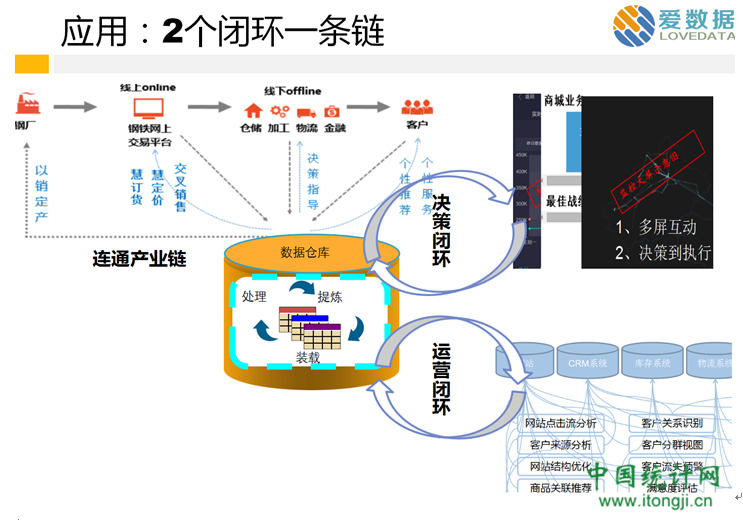
严格来说,这不属于架构范畴,但我还是想分享一下。简单说下大家就明白了。在大数据应用方面,传统行业如电信银行做的最多的,为决策支持类,即DSS类应用。这类应用的特点是,数据辅助决策后,会有行动跟进,如营销活动的开展。开展活动后,活动数据会再次流动到数据仓库,可再次分析。即形成了决策闭环。运营闭环,比如B2C的个性化推荐,如何推荐?数据来源于数据仓库。推荐后,数据会再次流入数据仓库,也形成闭环,即为运营闭环。还有一个一条链,说的是什么呢?在传统产业领域,比如钢贸相关,产业链过长,导致上下游信息不对称明显:对钢厂来说,他们不能正确获得消费需求信息,牛鞭效应,导致产能过剩;对用钢者来说,想要知道哪里可以买到物美价廉的产品非常困难。打通这个链条,对上可以环节厂家产能过剩,对下可以帮用户找到合适产品。
好了,我的介绍到这里,看看大家有什么问题?
——————————————END——————————————
数据夜修行是由海洋老师发起的一线数据分析从业者探讨交流的微信频道。
不定期对数据分析从业童鞋所遇问题进行交流讨论。
夜修行系列文章平均两周发布一次数据从业者高质量分享讨论文章。
不定期发布福利篇章,欢迎关注夜修行系列专栏。
夜修行,数据人深夜中的探索修行。
如果您是大数据行业的专业人士,愿意与大家分享,请联系:唐唐 18251923099(微信)
本文为中国统计网原创文章,需要转载请联系中国统计网(info@itongji.cn ),转载时请注明作者及出处,并保留本文链接。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

