记录一种工作流心跳机制的设计
最近工作中一直和SWF(Amazon的Simple Work Flow)打交道,在一个基于SWF的工作流框架上面开发和修bug。SWF的activity超时时间是5分钟,在activity task开始执行以后,activity worker需要 主动发送心跳请求 告知service端:“我还活着,我还在干活”,如果出现超过5分钟(可以 配置 )没有心跳,SWF的service端就认为,你已经挂了,我需要把这个activity安排到别的activity worker上来执行了。借用AWS 官网 的一张图:
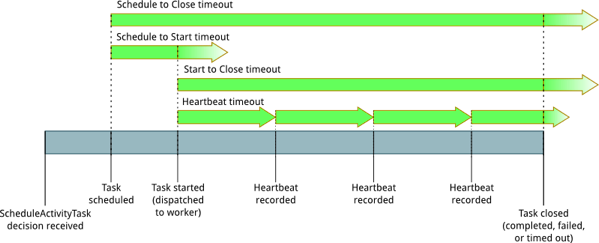
可以看到,在activity任务启动起来以后,需要用不断的心跳来告知service端任务还在进行,activity worker还活着。这个“汇报”需要activity worker所在的host主动进行,这也是SWF的service端无状态(几年前写过一点东西介绍它)的基本要求之一。任务都是由worker端去pull的,这些行为也都是worker端主动触发的。
这个机制描述起来很简单,但是实际在相关设计实现的时候,有许多有趣和值得琢磨的地方。
在我手头的这个workflow里面,心跳机制是这样实现的:
- 有两个queue,它们都是dequeue(双端队列),一个是main queue,一个是backup queue,都是用来存放需要发送心跳的activity信息(heartbeatable对象);
- 每秒钟都尝试执行这样一个方法A:从main queue里面poll一个heartbeatable对象(如果queue为空就忽略本次执行),检查该心跳所代表的activity task是否还在工作,如果是,就发送一个心跳。发送成功以后,就把这个heartbeatable对象扔到backup queue里面去。这样,一秒一个,逐渐地,main queue的heartbeatable对象全部慢慢被转移到backup queue里去了。
- 每隔两分钟(称为一个cycle)执行方法B:把backup queue里面所有的heartbeatable对象全部转移到main queue里去,于是就又可以继续执行上面一步的逐个心跳逻辑。
这个机制的基本好处是,所有activity task的心跳统一管理,通常情况下保证了心跳不会过快(默认配置下是一秒一个,或者不发送),同时保证了没有谁会被遗漏:
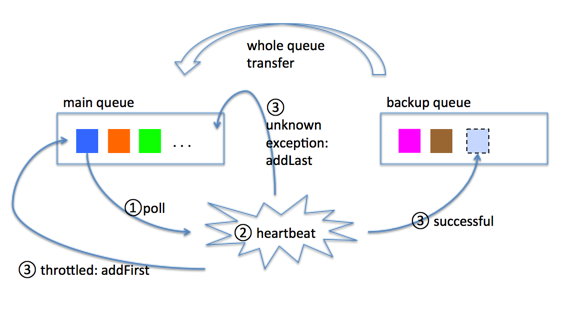
但是,这里又会浮现好多好多问题:
为什么要使用两个queue?
首先,有这样一个事实:方法A在执行的时候,理论上每秒钟会执行一次,但是这里并没有强制的保证,使得前一秒的A执行一定会在这一秒的A开始之前完成。换言之,它们的理论启动时间是按序的,但是实际启动时间和实际的心跳执行时间是不定的,需要处理并发的情形。而到底最多可能存在多少个执行A的线程并行,取决于用于此心跳功能的线程池的配置。因此,在执行和判断的过程中,需要对当前poll出来的heartbeatable对象加锁。
使用两个queue,这主要是为了记录在本次cycle里面,能够很容易判断某一个heartbeatable对象是否已经完成心跳行为。还没有完成心跳的,都在main queue里;完成了的,都放到backup queue里。
如果使用一个queue,那么也是有解决方案的:
- 有一个公共计数器,每个cycle+1。
- 每一个heartbeatable对象自身需要携带一个私有计数器,用以标识当前这轮cycle的心跳是否已经完成。
- 每次完成的heartbeatable对象给自己的计数器+1以后扔到队尾;每次A取新的heartbeatable对象的时候从队首取。
- 如果取到的对象自己的计数器已经等于公共计数器的数值,说明整个queue里面的对象心跳都已经完成了。
当然,这种方法的弊端在于,判断是否还需要发送心跳这件事情,不仅需要从queue里取对象,还要判断对象的计数器数值,明显比两个queue的解决方案复杂和开销大。因为两个queue的解决方案下,只需要尝试从main queue里面取对象就好,取不到了就说明本次cycle里没有需要发送心跳的对象了。看起来是多了一个queue,但是方案其实还是简单一些。
心跳的频率保持在多久为好?
显然不是越高越好,不只是成本,因为心跳也是需要消耗资源的,比如CPU资源;而且,心跳在service端也有throttling,当前activity worker发起太频繁的心跳,当前心跳可能被拒,还可能会让别的activity worker的正常心跳被拒了。
我们要解决的最核心问题是,正常情况下,必须保持上限5分钟内能发起一次成功心跳就好。
要这么说,尽量增大cycle,那我设计一个每隔5分钟就执行一次的定时器就好了。但是问题没那么简单,首先要考虑心跳的发起不一定成功。如果在接近5分钟的时候才去尝试发起心跳,一旦失败了,也没有时间重试了。因此,要trade-off。比如,配置cycle为120秒,这样的好处是,5分钟的超时时间内,可以覆盖1~2个完整的cycle。如果cycle配置为3分钟,那么5分钟无法严格保证一定覆盖有一个完整的cycle。
确定心跳频率的有两个重要参数,一个是方法A的执行频率,一个则是一个cycle的时间长度。例如,前者为1 per second,后者为2分钟,那么在理想情况下,一个cycle 120秒,可以处理120个activity task,换言之,极限是120个activity task在这台机器上一起执行。超过了这个数,就意味着在一个cycle内,无法完成所有的心跳发送任务。
当然,实际情况没有那么理想,考虑到暂时性的网络问题,线程、CPU资源的竞争等等,实际可以并行的activity task要比这个数低不少。
异常处理和重试
在上图中,步骤③有三个箭头,表示了心跳出现不同种情形的处理:
- 有一些常规异常,比如表示资源不存在,或者任务已经cancel了,这种情况发生的时候,要把相应的activity task给cancel掉,同时,把自己这个heartbeatable对象永久移除出queue。
- 重试机制1:throttling导致的异常,这种异常发生的时候,把当前heartbeatable对象再addFirst回main queue,因为这不是当前有什么不可解决的或者不明原因的问题造成的,只需要简单重试即可。
- 重试机制2:其它未知原因的异常,这种情况当然需要重试(之前我们缺少这样的重试机制,导致下一次该activity task能够得到心跳的机会被推到了下一个cycle,这显然是不够合理的),但是,可以把heartbeatable对象放到queue尾部去重试(addLast),并且附上一个私有计数器,如果重试超过一定次数,就挪到下一个cycle(backup queue)去。这个放到queue尾部的办法,使得重试可以在当前cycle里进行,又可以使得这个重试能够尽量不影响其他heartbeatable对象的心跳及时发送。整个重试过程其实就是把当前失败对象再放回queue的过程,没有线程阻塞。
曾经遇到过一些这方面的问题,经过改进才有了上述的机制:
在CPU或者load达到一定程度的时候(比如这个时候有一个进程在call service,占用了大量的CPU资源),就很容易发生心跳无法及时进行的问题,比如有时候线程已经初始化了,但是会stuck若干时间,因为没有足够的资源去进行。等到某一时刻,资源被释放(比如这个call service 的进程结束),这个时候之前积攒的心跳任务会一下子爆发出来。不但这些心跳的顺序无法保证,而且严重的情况下会导致throttling。如果没有当前cycle内的重试机制,那么下一次该对象的心跳需要等到下一个cycle,很容易造成activity task的timeout。
下面再说一个和心跳异常有关的问题。
有这样一个例子,在这个工作流框架内,我们需要管理EMR资源,有一个activity把EMR cluster初始化完成,另一个activity把实际执行的steps提交上去。但是发现在实际运行时有如下的问题:EMR cluster已经初始化完成,但是steps迟迟没有办法提交上去,导致了这个cluster空闲太长时间,被框架内的monitor认为已经没有人使用了,需要回收,于是EMR cluster就被terminate了。但是这之后,steps才被提交上去,但是这时候cluster已经处于terminating状态了,自然这个step提交就失败了。而经过分析,造成这个EMR cluster非预期的termination,包括这样几个原因:
- decision task timeout。在EMR cluster创建好之后,SWF会问decider下一步该干嘛,这时候如果因为CPU高负荷等各种原因,导致decision task timeout,SWF就会一直等在那里,而如果这个timeout的时间配得太长,这段超时就足以让上面的这个EMR cluster空闲过长时间导致被误回收了。
- 判断EMR cluster空闲到一定时间就要回收的逻辑有问题。我们以前的实现是,每隔2分钟执行一次“EMR资源操作”,包括检查资源状态,进行资源操作,然后如果发现该EMR资源创建后经过了4次资源操作,依然没有step提交上去,就认为空闲时间过长,需要回收(2 x 4 = 8分钟)。但是问题在于,实际由于种种原因(和心跳的执行间隔实际时间不确定的原理一样),间隔执行EMR资源操作并不能严格保证每隔2分钟一次,有时一段时间都得不到执行,而有时候会迎来一次集中爆发,这个时候就可能实际EMR资源空闲了远远不到8分钟就被回收了。因此,这个逻辑最好是能够用绝对的“空闲时间”来判断,例如EMR资源创建时记录好时间,之后每次检查时都用当前时间去和创建时间比较,空闲超过8分钟再回收。
- 由于之前提到过的心跳无法按时完成导致activity task timeout,于是这个EMR cluster创建的任务实际已经完成了,但是被当做超时给无视了。
最后,我想说的是。设计一个好的工作流框架,还是有很多困难的地方,需要尤其考虑周全的地方。即便是基于SWF这样现有的workflow来搭积木和叠加功能,也有很多不易和有趣的地方。
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

