PostgreSQL Partial Index
说起「 Partial Index 」,估计很多人没听说过。在 PostgreSQL 中,它的含义是指:通过查询条件索引选定的行,而不是所有的行。虽然 MySQL 也有此概念,但是其更接近前缀索引的含义:比如你想索引一个 VARCHAR(255) 的字段,根据数据分布情况,你可以仅索引前面若干个字符,如此通过降低索引体积来达到提升性能的目的。
例一:
有一个 users 表,里面有一个 mobile 字段,缺省值为 null。用户可以不填写手机号,如果填写,每个手机号只能关联一个用户,怎么办?
听起来这就是一个唯一索引,但是直接创建的话肯定会失败,因为字段里有空值,这个问题放到 MySQL 里就无解了,只能通过新建一个 users_mobiles 表来约束唯一性。下面看看在 PostgreSQL 中如何利用 Partial Index 来搞定:
sql> CREATE UNIQUE INDEX on users (mobile) WHERE mobile IS NOT NULL;
通过在创建索引的时候过滤掉无关的数据,从而实现创建唯一索引的目的。
例二:
有一个 questions 表,里面有一个 created_at 字段表示创建时间,一个 answer_count 字段表示答案数量,查询不同时间范围里答案数量大于 10 个的问题:
sql> SELECT * FROM questions WHERE answer_count > 10 AND created_at > 1455555555 LIMIT 100;
插播知识广告:查询分为两种类型:其一是 point 查询,比如 foo = 123;其二是 range 查询,比如 foo > 123。通常,一个索引里只能用到一个 range 类型的查询字段。
如此说来,本例如何创建索引呢?因为两个查询条件都是 range 类型的,所以一般情况下创建索引时必须二选一。下面看看在 PostgreSQL 中如何利用 Partial Index 来搞定:
先看看没有使用 Partial Index 时查询的效果:
sql> CREATE INDEX created_at on questions (created_at);
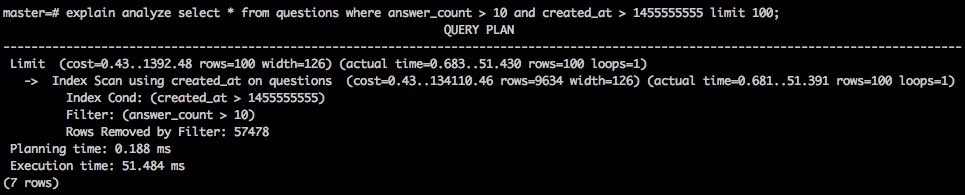
没有使用 Partial Index
再看看使用 Partial Index 时查询的效果:
sql> CREATE INDEX partial_index on questions (created_at) WHERE answer_count > 10;

使用 Partial Index
对比前后两次查询可以发现,在没有使用 Partial Index 的时候,只能先通过索引拿到结果,然后再通过 Filter 过滤另一个条件;而在使用 Partial Index 的时候,可以直接通过 Partial Index 拿到结果,无需二次过滤,在本例中查询效率有百倍提升。
当然了,只有那些相对固定的条件适合用在 Partial Index 中,比如本例中,答案数量大于 10 的条件是作为热门问题的判断依据存在的,是明确的业务逻辑,如此则适合;而另一个创建时间的条件这是频繁变化的,如此则不适合。
推荐阅读: Handling Growth with Postgres: 5 Tips From Instagram 。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

