面部表情识别新方式:Multimodal Learning实现Image与Landmark的融合
Multimodal Learning用于面部表情识别,多模态分别表现为图像数据和标记点数据,使用Multimodal Learning对二者融合的意义在于更全面地表现表情信息以及区分不同模态的数据对表情识别的影响。
模式识别领域国际权威期刊Pattern Recognition在2015年4月发表了山东大学视觉传感与智能系统实验室与华为诺亚方舟实验室的研究成果“ Multimodal Learning for Facial Expression Recognition ”,该文章提出的多模态学习(Multimodal Learning)算法开拓了面部表情识别的一种新方式。
面部表情识别是人工智能的一个重要领域,其应用领域也较为广泛,如人机交互、交通安全、智能医疗等。近年来,随着众多学者不断地探索与发现,面部表情识别已经取得了长足的进步,对面部表情的识别精度和效率的要求也越来越高,因此,如何在冗余数据中提取有效信息并针对不同信息进行区别对待成为面部表情识别领域的一个关键。最近几年,包括麻省理工(MIT)、卡耐基梅隆大学(CMU)、匹兹堡大学(University of Pittsburgh)、Google、微软、中科院等国内外知名研究机构和公司都在不断推进这项研究。
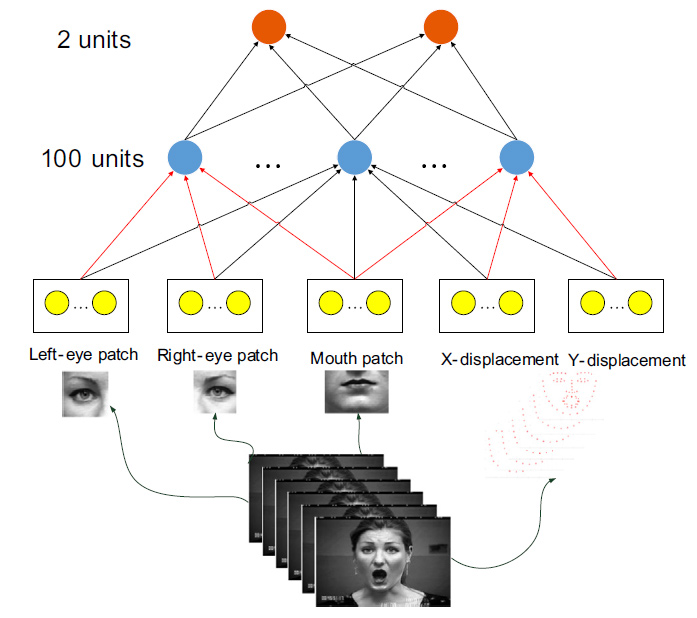
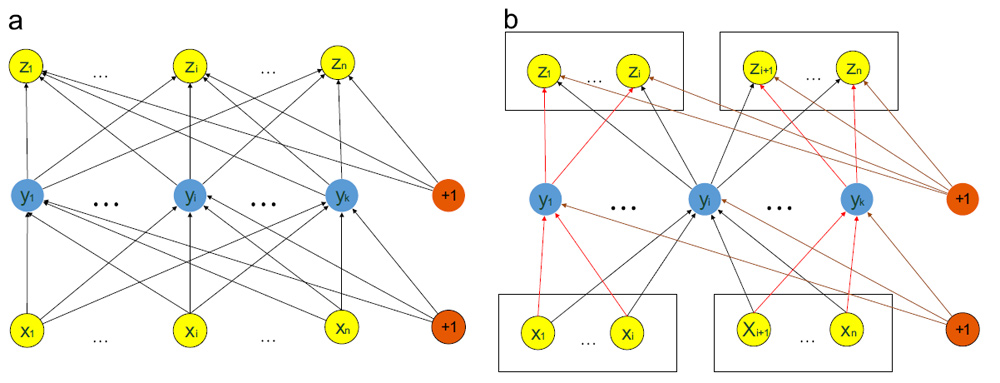
考虑到面部表情的整体性与局部细节完整性,山大和华为的研究人员在进行表情识别时融合了Image与Landmark信息,并具体分为5个模态的数据并同时输入到神经网络。在对神经网络采用AE(Auto-encoder)进行预训练时,为区分不同模态的数据对表情识别的影响,加入了结构化正则项(Structure Regularization),有效限制了隐层神经元与不同模态数据的连接,从而实现了网络区分不同模态数据对表情识别影响强弱的能力。山大和华为合作提出的多模态学习方法将Image与Landmark进行融合,使得输入数据能全面,与此同时,对不同输入信息区别对待,在表情识别任务上超过了其它研究机构,达到了业界领先水平。
山大张伟博士和华为马林博士介绍,多模态学习算法为面部表情的识别的展开了新的方式,他们会持续关注并进一步就该方向开展研究。
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

