Zookeeper选举算法总结及集群搭建
Zookeeper选举算法总结及集群搭建
Zookeeper是一个分布式的,开放源码的分布式应用程序协调服务,它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名服务等。
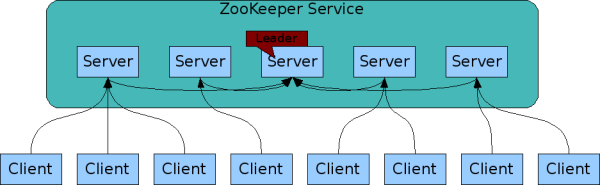
图1
在集群中有三种角色,leader、follower和observer。leader和各个follower是互相通信的,对于zk系统的数据都是保存在内存里面的,同样也会备份一份在磁盘上。对于每个zk节点而言,可以看做每个zk节点的命名空间是一样的,也就是有同样的数据(下面的树结构)如果Leader挂了,zk集群会重新选举,在毫秒级别就会重新选举出一个Leaer集群中除非有一半以上的zk节点挂了,zk service才不可用。
其默认选举算法为FastLeaderElection。FastLeaderElection的本质是类fast Paxos的算法。Google Chubby的作者Mike Burrows说过这个世界上只有一种一致性算法,那就是Paxos,其它的算法都是残次品。
以下给出FastLeaderElection算法的分析过程:
首先给出几个名词解释:
Serverid:在配置server时,给定的服务器的标示id。
Zxid:服务器在运行时产生的数据id,zxid越大,表示数据越新。
Epoch:选举的轮数,即逻辑时钟。
Server状态:LOOKING,FOLLOWING,OBSERVING,LEADING
总结:
一、首先开始选举阶段,每个Server读取自身的zxid。
二、发送投票信息
a、首先,每个Server第一轮都会投票给自己。
b、投票信息包含 :所选举leader的Serverid,Zxid,Epoch。Epoch会随着选举轮数的增加而递增。
三、接收投票信息
1、如果所接收数据中服务器的状态是否处于选举阶段(LOOKING 状态)。
首先,判断逻辑时钟值:
a)如果发送过来的逻辑时钟Epoch大于目前的逻辑时钟。首先,更新本逻辑时钟Epoch,同时清空本轮逻辑时钟收集到的来自其他server的选举数据。然后,判断是否需要更新当前自己的选举leader Serverid。判断规则rules judging:保存的zxid最大值和leader Serverid来进行判断的。先看数据zxid,数据zxid大者胜出;其次再判断leader Serverid,leader Serverid大者胜出;然后再将自身最新的选举结果(也就是上面提到的三种数据(leader Serverid,Zxid,Epoch)广播给其他server)
b)如果发送过来的逻辑时钟Epoch小于目前的逻辑时钟。说明对方server在一个相对较早的Epoch中,这里只需要将本机的三种数据(leader Serverid,Zxid,Epoch)发送过去就行。
c)如果发送过来的逻辑时钟Epoch等于目前的逻辑时钟。再根据上述判断规则rules judging来选举leader ,然后再将自身最新的选举结果(也就是上面提到的三种数据(leader Serverid,Zxid,Epoch)广播给其他server)。
其次,判断服务器是不是已经收集到了所有服务器的选举状态:若是,根据选举结果设置自己的角色(FOLLOWING还是LEADER),退出选举过程就是了。
最后,若没有收到没有收集到所有服务器的选举状态:也可以判断一下根据以上过程之后最新的选举leader是不是得到了超过半数以上服务器的支持,如果是,那么尝试在200ms内接收一下数据,如果没有新的数据到来,说明大家都已经默认了这个结果,同样也设置角色退出选举过程。
2、 如果所接收服务器不在选举状态,也就是在FOLLOWING或者LEADING状态。
a)逻辑时钟Epoch等于目前的逻辑时钟,将该数据保存到recvset。此时Server已经处于LEADING状态,说明此时这个server已经投票选出结果。若此时这个接收服务器宣称自己是leader, 那么将判断是不是有半数以上的服务器选举它,如果是则设置选举状态退出选举过程。
b) 否则这是一条与当前逻辑时钟不符合的消息,那么说明在另一个选举过程中已经有了选举结果,于是将该选举结果加入到outofelection集合中,再根据outofelection来判断是否可以结束选举,如果可以也是保存逻辑时钟,设置选举状态,退出选举过程。
安装配置zookeeper集群:
准备三台服务器
192.168.201.128
192.168.201.131
192.168.201.132
分别在3台服务器进行如下操作:
1.解压zookeeper安装包后得到目录: /usr/zookeeper-3.3.3
2.进入zookeeper-3.3.3目录下,把conf目录下的zoo_sample.cfg 复制成zoo.cfg文件
3. 打开zoo.cfg并修改和添加配置项目,如下:
# tickTime这个时间是作为Zookeeper服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个tickTime时间就会发送一个心跳;
tickTime=2000
#initLimit这个配置项是用来配置Zookeeper接受客户端(这里所说的客户端不是用户连接Zookeeper服务器的客户端,而是Zookeeper服务器集群中连接到Leader的Follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。
当已经超过10个心跳的时间(也就是tickTime)长度后 Zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是 10*2000=20 秒;
initLimit=10
#syncLimit这个配置项标识Leader与Follower之间发送消息,请求和应答时间长度,最长不能超过多少个tickTime的时间长度,总的时间长度就是5*2000=10秒;
syncLimit=5
# clientPort这个端口就是客户端连接Zookeeper服务器的端口,Zookeeper会监听这个端口接受客户端的访问请求;
clientPort=2181
#dataDir顾名思义就是Zookeeper保存数据的目录,默认情况下Zookeeper将写数据的日志文件也保存在这个目录里;
dataLogDir=/usr/zookeeper-3.3.3/log
#server.A=B:C:D
#A是一个数字,表示这个是第几号服务器,B是这个服务器的ip地址
#C第一个端口用来集群成员的信息交换,表示的是这个服务器与集群中的Leader服务器交#换信息的端口
#D是在leader挂掉时专门用来进行选举leader所用
server.1=192.168.201.128:2888:3888
server.2=192.168.201.131:2888:3888
server.3=192.168.201.132:2888:3888
4、 新建log和data目录
mkdir /usr/zookeeper-3.3.3/data
mkdir /usr/zookeeper-3.3.3/log
5 、在/usr/zookeeper-3.3.3/data目录下创建一个文件:myid
6、分别在myid上按照配置文件的server.中id的数值,在不同机器上的该文件中填写相应过的值
192.168.201.128 的myid内容为1
192.168.201.131 的为2
192.168.201.132 的为3
7.分别在三台机器/usr/zookeeper-3.3.3/bin/目录下执行:
./zkServer.sh start
8.执行jps就可以看启动的zookeeper进程了。
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

