如何使用ELK来监控性能
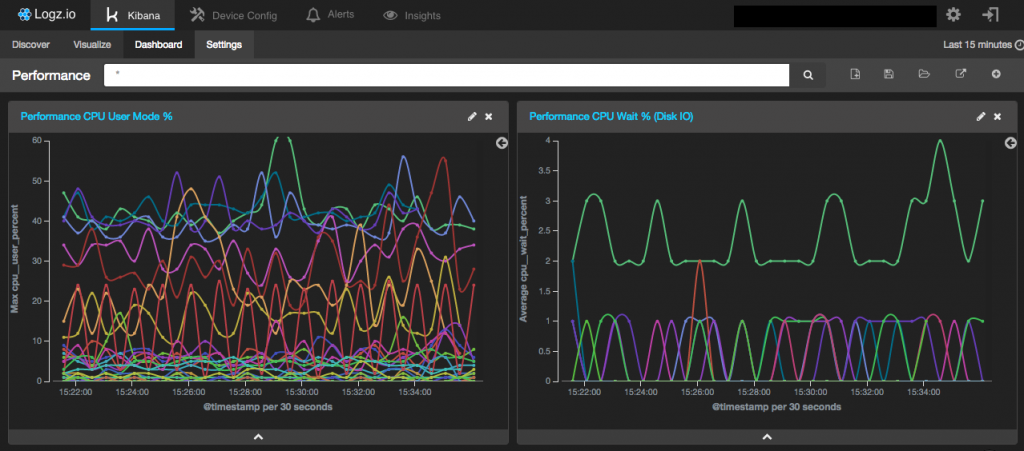
每当我解决一些应用性能问题的时候,我常常会看到一个服务由于高的CPU利用率而使得一台或者多台服务器运行变得非常缓慢。这也许意味着它因为高负载而导致资源缺乏,但是通常情况下这其实是代码有bug,一个异常或者一个错误的流程导致过多占用了系统资源。为了把这些问题找出来,我不得不在NewRelic/Nagios和ELK之间查看信息。
所以我确信我需要有一个单一的管理面板来查看从各个应用,操作系统以及网络设备上收集来的事件组合而成的性能指标
为了使用ELK来监控你平台的性能,你需要集成一系列的工具。Probes是必须包含的组件,它运行在各个主机上用来收集各种系统性能指标。然后,采集的数据需要发送给Logstash,然后在Elasticsearch中进行聚集,最后由Kibana转换成图形。最终,软件服务操作组成员使用这些图形展示系统性能。在这篇文章中,我将分享我们如何建构我们的ELK软件栈来监控服务的性能。
1. 收集和传送
收集
在收集和传送数据到Logstash中的第一个步骤,我们使用一个名为 Collectl 的工具。该工具来自于一个开源项目,它包含的大量的选项允许系统管理员从多个不同的IT系统中获取各种指标,并且运行保存这些数据供以后分析。我们使用它来生成,追踪,以及保存指标数据,例如网络吞吐量,CPU的磁盘IO等待时间,空闲的内存,以及CPU的空闲时间(指出过度/未充分使用计算机资源)。它也常被用于监控其他类型的系统资源,例如inode的使用以及打开的socket数量。
Collectl命令输出样例
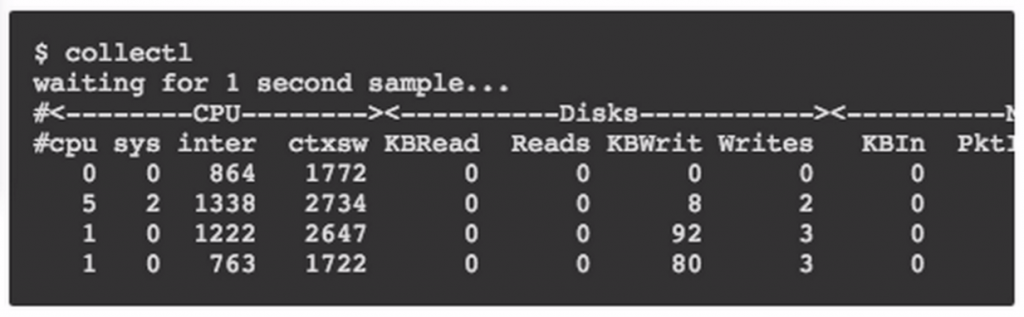
最后,Collectl使用指定格式(in plot format)将采集的指标输出到一个日志文件中。该开源项目知道如何收集信息但是它并不会自动发送数据到ELK软件栈中。
使用一个Docker容器
我们把Collectl封装到了一个Docker容器中来获取一个Docker镜像,该镜像会包含了数据采集和数据发送的基本软件。我们使用版本4.0.0的Collectl以及下面提到的配置,这样可以避免一系列的问题:
—— 为了避免数据在容器中过载,我们只保存了当天的数据。更久的数据都是维护在ELK软件栈中,因此你无需担心在容器的日志中保存所有的数据导致的问题。
—— Collectl可以以指定的时间周期收集各种采样数据,当它会用不同的时间周期把数据持久到磁盘。这被称为刷新周期。如果数据每秒钟都被刷新到磁盘那么你可以得到近乎实时的数据。不过例如对于一个30秒的采集间隔,那么选择一个十分激进的采样周期不是必须的。一个输出格式化器会用于输出指定格式(a plot format)的输出,默认它会在每一行输出多个值,每个值用空格分开。
Collectl配置文件看上去类似下面:
DaemonCommands = -f /var/log/collectl/performance-tab -r00:00,0 -F1 -s+YZ -oz -P --interval 30 PQuery = /usr/sbin/perfquery:/usr/bin/perfquery:/usr/local/ofed/bin/perfquery PCounter = /usr/mellanox/bin/get_pcounter VStat = /usr/mellanox/bin/vstat:/usr/bin/vstat OfedInfo = /usr/bin/ofed_info:/usr/local/ofed/bin/ofed_info Resize=/usr/bin/resize:/usr/X11R6/bin/resize Ipmitool = /usr/bin/ipmitool:/usr/local/bin/ipmitool:/opt/hptc/sbin/ipmitool IpmiCache = /var/run/collectl-ipmicache IpmiTypes = fan,temp,current使用RSYSLOG
RSYSLOG 是另一个容器组件。它用来从日志文件中提取数据,并且发送数据到ELK软件栈中。为了让Logstash专注于需要字段而不是所有的数据上,这里建议使用RSYSLOG在日志里增加一些元数据来对日志进行筛选。这里可以在数据发送前对指标进行过滤或者增加一些信息比如实例名称以及IP地址。附加上了时间戳后,这些信息可以被发送到Logstash。
一些注意点
在本步骤,有两个问题需要注意:
1 - 时间戳: 首先,Collectl并不在采集的数据中输出它的时间戳。因此如果你不同的主机运行在不同的时区,它们在你的ELK里面并不会对齐。为了解决这个问题,我们需要查询容器当前运行的时区,然后设置相应的时间戳。
2 - 遵循Collectl日志文件名: 另一个复杂的问题是Collectl输出数据到一个文件中,但是该文件名不是固定不变的。仅仅文件名的前缀是可以自定义的,然后Collectl自动在文件名上加上了当前日期。这个问题导致RSYSLOG不能通过文件名来监视文件,当日期切换时文件名也会改变。我们可以用最新版本的RSYSLOG —— 版本8来解决它,但是这里我假设大多数用户还没有用上这个版本。我们创建了一个很小的脚本,它调用了老版本的RSYSLOG,该脚本在容器里运行了一个定时的任务,该任务会链接一个指定的名称的文件名到一个固定的日志文件名上。然后SYSLOG只中那个固定日志文件中提取数据,即便该文件链接的目标文件改变了也没有关系。这就像一个指针,它在一定的时间下总是指向正确的Collectl日志文件。
$ModLoad imfile $InputFilePollInterval 10 $PrivDropToGroup adm $WorkDirectory /var/spool/rsyslog # Logengine access file: $InputFileName /var/log/collectl/daily.log $InputFileTag performance-tab: $InputFileStateFile stat-performance $InputFileSeverity info $InputFilePersistStateInterval 20000 $InputRunFileMonitor $template logzioPerformanceFormat,"[XXLOGZTOKENXX] <%pri%>%protocol-version% %timestamp:::date-rfc3339% XXHOSTNAMEXX %app-name% %procid% %msgid% [type=performance-tab instance=XXINSTANCTIDXX] XXOFSETXX %msg% XXUSERTAGXX/n" if $programname == 'performance-tab' then @@XXLISTENERXX;logzioPerformanceFormat容器检查清单
— Collectl
-
RSYSLOG
-
链接Collectl输出文件的脚本
-
脚本文件的配置
上面用到的Docker镜像可以在DockerHub上拉取,链接: https://registry.hub.docker.com/u/logzio/logzio-perfagent/
2. 解析数据
在收集和装箱发送后,我们需要做数据的解析。Collectl返回的是未结构化的日志数据,它基本是由一系列的数字组成, Logstash Grok表达式使用这些数据来获取每个字段的名称和指定的值。
Collectl的配置参数显示设置了一个特定的输出模式。RSYSLOG日志配置在发送的消息中的特定位置增加了时区的信息。如果你想同时使用了这两个配置,那Grok模式配置如下:
%{GREEDYDATA:zone_time} %{NUMBER:cpu__user_percent:int} %{NUMBER:cpu__nice_percent:int} %{NUMBER:cpu__sys_percent:int} %{NUMBER:cpu__wait_percent:int} %{NUMBER:cpu__irq_percent:int} %{NUMBER:cpu__soft_percent:int} %{NUMBER:cpu__steal_percent:int} %{NUMBER:cpu__idle_percent:int} %{NUMBER:cpu__totl_percent:int} %{NUMBER:cpu__guest_percent:int} %{NUMBER:cpu__guestN_percent:int} %{NUMBER:cpu__intrpt_sec:int} %{NUMBER:cpu__ctx_sec:int} %{NUMBER:cpu__proc_sec:int} %{NUMBER:cpu__proc__queue:int} %{NUMBER:cpu__proc__run:int} %{NUMBER:cpu__load__avg1:float} %{NUMBER:cpu__load__avg5:float} %{NUMBER:cpu__load__avg15:float} %{NUMBER:cpu__run_tot:int} %{NUMBER:cpu__blk_tot:int} %{NUMBER:mem__tot:int} %{NUMBER:mem__used:int} %{NUMBER:mem__free:int} %{NUMBER:mem__shared:int} %{NUMBER:mem__buf:int} %{NUMBER:mem__cached:int} %{NUMBER:mem__slab:int} %{NUMBER:mem__map:int} %{NUMBER:mem__anon:int} %{NUMBER:mem__commit:int} %{NUMBER:mem__locked:int} %{NUMBER:mem__swap__tot:int} %{NUMBER:mem__swap__used:int} %{NUMBER:mem__swap__free:int} %{NUMBER:mem__swap__in:int} %{NUMBER:mem__swap__out:int} %{NUMBER:mem__dirty:int} %{NUMBER:mem__clean:int} %{NUMBER:mem__laundry:int} %{NUMBER:mem__inactive:int} %{NUMBER:mem__page__in:int} %{NUMBER:mem__page__out:int} %{NUMBER:mem__page__faults:int} %{NUMBER:mem__page__maj_faults:int} %{NUMBER:mem__huge__total:int} %{NUMBER:mem__huge__free:int} %{NUMBER:mem__huge__reserved:int} %{NUMBER:mem__s_unreclaim:int} %{NUMBER:sock__used:int} %{NUMBER:sock__tcp:int} %{NUMBER:sock__orph:int} %{NUMBER:sock__tw:int} %{NUMBER:sock__alloc:int} %{NUMBER:sock__mem:int} %{NUMBER:sock__udp:int} %{NUMBER:sock__raw:int} %{NUMBER:sock__frag:int} %{NUMBER:sock__frag_mem:int} %{NUMBER:net__rx_pkt_tot:int} %{NUMBER:net__tx_pkt_tot:int} %{NUMBER:net__rx_kb_tot:int} %{NUMBER:net__tx_kb_tot:int} %{NUMBER:net__rx_cmp_tot:int} %{NUMBER:net__rx_mlt_tot:int} %{NUMBER:net__tx_cmp_tot:int} %{NUMBER:net__rx_errs_tot:int} %{NUMBER:net__tx_errs_tot:int} %{NUMBER:dsk__read__tot:int} %{NUMBER:dsk__write__tot:int} %{NUMBER:dsk__ops__tot:int} %{NUMBER:dsk__read__kb_tot:int} %{NUMBER:dsk__write__kb_tot:int} %{NUMBER:dsk__kb__tot:int} %{NUMBER:dsk__read__mrg_tot:int} %{NUMBER:dsk__write__mrg_tot:int} %{NUMBER:dsk__mrg__tot:int} %{NUMBER:inode__numDentry:int} %{NUMBER:inode__openfiles:int} %{NUMBER:inode__max_file_percent:int} %{NUMBER:inode__used:int} %{NUMBER:nfs__reads_s:int} %{NUMBER:nfs__writes_s:int} %{NUMBER:nfs__meta_s:int} %{NUMBER:nfs__commit_s:int} %{NUMBER:nfs__udp:int} %{NUMBER:nfs__tcp:int} %{NUMBER:nfs__tcp_conn:int} %{NUMBER:nfs__bad_auth:int} %{NUMBER:nfs__bad_client:int} %{NUMBER:nfs__reads_c:int} %{NUMBER:nfs__writes_c:int} %{NUMBER:nfs__meta_c:int} %{NUMBER:nfs__commit_c:int} %{NUMBER:nfs__retrans:int} %{NUMBER:nfs__authref:int} %{NUMBER:tcp__ip_err:int} %{NUMBER:tcp__tcp_err:int} %{NUMBER:tcp__udp_err:int} %{NUMBER:tcp__icmp_err:int} %{NUMBER:tcp__loss:int} %{NUMBER:tcp__f_trans:int} %{NUMBER:buddy__page_1:int} %{NUMBER:buddy__page_2:int} %{NUMBER:buddy__page_4:int} %{NUMBER:buddy__page_8:int} %{NUMBER:buddy__page_16:int} %{NUMBER:buddy__page_32:int} %{NUMBER:buddy__page_64:int} %{NUMBER:buddy__page_128:int} %{NUMBER:buddy__page_256:int} %{NUMBER:buddy__page_512:int} %{NUMBER:buddy__page_1024:int}?( %{GREEDYDATA:user_tag})3. 可视化
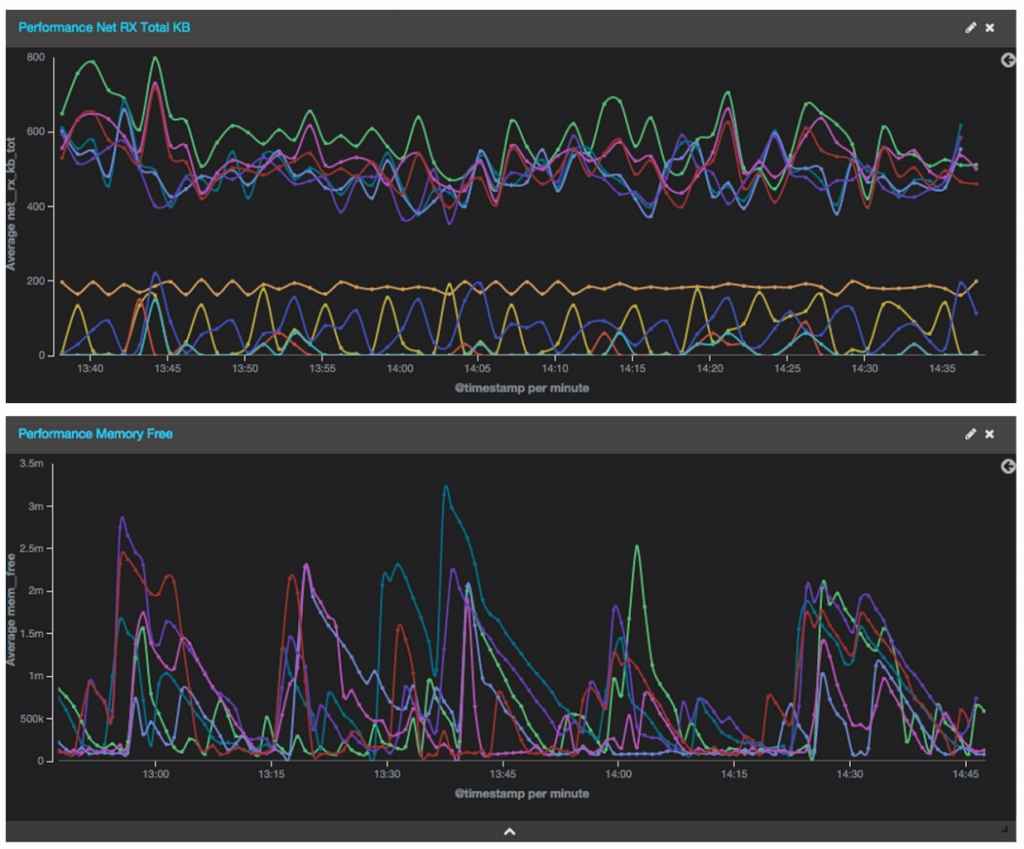
如果你运行了一个快速的ELK软件栈,那你会几乎同时得到这些数据的展示。显然这依赖于你安装的ELK的性能,不过你可以预期会在半分钟之内得到结果 - 一个最新的数据流的信息。
在Logz.io,我们有一些预定义的报警和仪表板来展示性能指标,它们都是使用Collectl。如果你也使用Logz.io服务,请在聊天室里找到我们,我们将会分享这些有用的信息。
如果你想了解更多,请随意在下面留言!
翻译自 这里
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

