频频卡顿崩溃?移动应用如何跟踪定位性能问题
百年前,人们获取信息的方式是通过书籍、报纸;十年前,人们获取信息的方式是通过PC、互联网;如今,在移动互联网高速发展的环境下,人们获取信息的方式已经全面转向了小小的手机。短短几年里,移动互联网已经与我们的生活形影不离,一部手机走天下不再是梦想。
移动应用的商业价值在互联网时代发生了变化,越来越多企业通过移动应用为用户提供服务,应用改变了商业世界。2016年Q1,用户从iOS和Android应用市场下载的应用数量高达172亿个,94%的应用以火箭般的速度进行更新。更新迭代越快,应用存在的性能问题就越突出,性能问题造成业务下降影响已经占到25%甚至更多,应用本身的变革迫在眉睫。
透视宝 mobile APM 从五个维度解析移动应用性能
移动应用发布上线之后,由于缺少有效的性能监控手段,对于开发和运维来说其架构、应用、程序代码的执行情况都是一个黑盒,无法感知到用户使用APP的真实感受,无法预知应用发生了什么样的问题,看不到业务具体数据到底是怎么执行,更没办法准确定位到问题,而APM通过以下五个重要维度能够帮你把黑盒子打开。
1、 用户从哪来,网络接入性能怎么样?

地域分析可以了解我们的用户都是从哪些地域使用APP,各地的响应时间是否存在很大差异,耗时较高的地区根据网络节点调整CDN,优化网站层面的性能问题。
2、 用户使用的什么设备,不同运营商对网络响应是否达标?
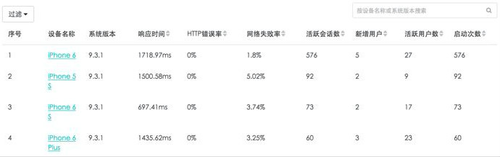
设备、运营商、APP版本分析可以帮忙了解用户使用什么品牌的手机访问APP应用,不同的终端存在不同的差异,据统计iPhone6 使用较为稳定,而华为设备发生崩溃几率最低,通过这些设备、运营商、APP版本的分析结果可以在新版本迭代中安排重点测试和适配。
3、用户做了什么操作,在APP中的用户体验如何?
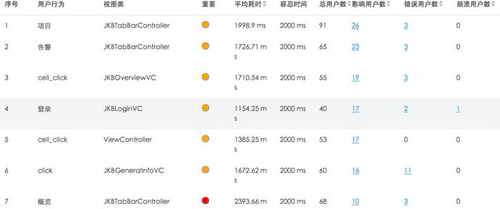
用户行为监控能够将所有用户在APP中的点击操作与性能数据关联,通过HTTP请求响应耗时,请求错误,崩溃等维度分析APP中最影响用户体验的用户行为。并且可分析受到影响的每一位用户的在APP中行为操作路径及流程,协助研发人员还原用户使用场景从而精准定位问题发生的原因。
4、APP中是否发生了崩溃、ANR等问题?
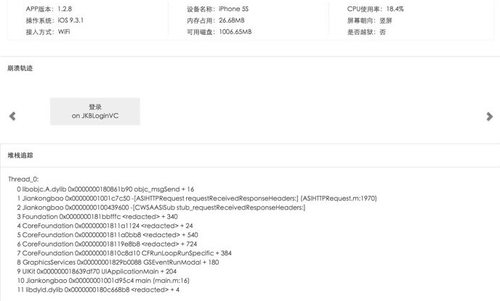
崩溃是APP应用中最影响用户体验的问题之一,而且是移动开发者最大的痛点,所以收集崩溃日志、快速定位问题根源是最好的解决办法。崩溃分析可按APP版本,崩溃趋势,设备型号,运营商,接入方式,地域崩溃等多个维度分析和统计。
崩溃分析可以解析崩溃堆栈定位发生崩溃的代码片段和行数,并且通过收集分析用户发生崩溃的设备,接入方式,内存,CPU使用率以及用户操作的行为轨迹助研发人员能快速定位问题,还原案发现场。
5、APP 前端页面 交互性能和Service端代码执行效率
APP中的性能问题大体可以分为两部分:1、前端页面交互性能 2、后端Service端代码效率。
前端页面交互性能主要体现在页面加载缓慢,请求错误异常,卡顿等方面,而目前webview在APP开发中已经非常普遍,对性能的监控需求也越来越强烈。我们提出白屏时间、页面请求耗时分解、页面加载资源耗时分解等性能指标,可以对页面请求耗时诊断慢在哪个环节。
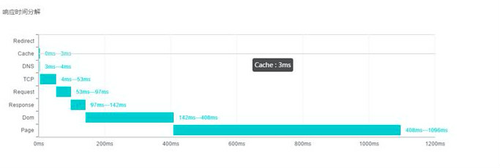
页面响应时间分解,将整个H5页面加载的耗时分解到网络请求的每一个细节上去。如上图主要包括:重定向起止时间、缓存起止时间、域名解析起止时间、TCP传输起止时间、请求起止时间、响应起止时间、Dom加载起止时间、页面渲染起止时间等。
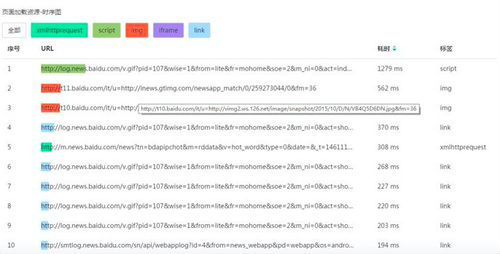
图:H5页面加载的资源时序图,明确告知每一个资源类型的加载时间。
APP端除了前端的性能问题需要关注,Service端的性能问题同样不容忽视,由于篇幅问题本文不做重点介绍,但是需要介绍mobile端与service的端到端的特性。
端到端事务分析
针对移动端的事务我们可以诊断定位到耗时情况,除了前端页面的资源加载占用大量资源外,Service代码造成缓慢的因素同样需要准确定位,所以透视宝提供了端到端事务分析。
移动端嵌入SDK,Service端部署Smart Agent,通过UUID关联了APP中所有的请求事务,定位后端的代码执行最慢的方法,SQL语言,参数等指标。
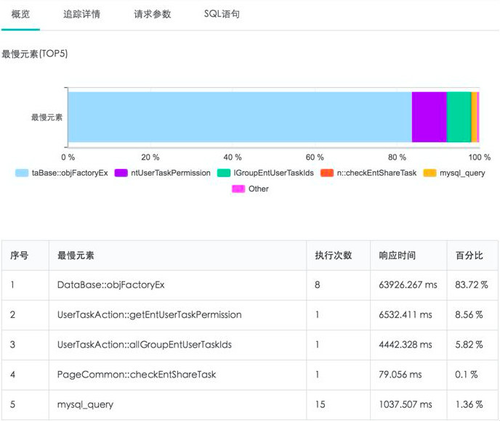
针对HTTP的网络数据收集主要分为以下指标:请求时间、网络吞吐量和网络错误,劫持分析等。
请求时间是指一个http请求从发起请求到接收到服务端的响应,这期间所经历的时间。这个指标可以跟踪后台接口的响应是否正常,网络环境是否正常。
网络错误主要是跟踪url请求过程中的错误,分为http本身的错误和因网络状况出现的错误。
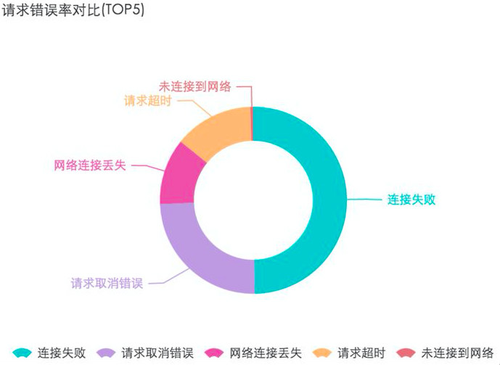
某个客户的一个杭州用户在6分钟内发起了5800多次请求,请求错误率高达98%以上。当时他们不相信那是真实的,后来与客户交流发现该网络请求接口存在循环调用,请求接口在请求成功之前会一直循环调用,直到请求成功或是断网,而这正是造成导致循环请求的真正原因。
还是这个客户,我们通过Smart SDK发现他的很多API报错是找不到主机,经确认APP开发在版本迭代过程中把很多接口废弃了,但客户端还在调用,通过HTTP错误和网络错误请求分析就可以帮助客户清理废弃的API,保证我们的业务正常服务。
而做到这一切,只需要嵌入透视宝Smart SDK的两行代码, 5分钟轻松实现对APP应用的性能监控,业务运营监控的需求。以往通过用户投诉和反馈,开发总是最后一个发现问题,而被动的解决问题更是费时费力。使用透视宝后可以提前发现应用性能问题,快速迭代修复问题,避免用户流失提升用户体验。
移动端性能管理 技术实现
透视宝Smart SDK自动收集性能数据是不需要埋点的。iOS和Android由于平台的差异性实现方式是不同的。Objective-C语言具有动态运行时的特性,因此iOS平台使用Hook机制来拦截方法的执行,从而收集性能数据;而Java语言不具备这样的特性,但能够对字节码进行改写,因此Android平台使用ASM框架动态注入代码到相关的方法中收集性能数据。
iOS Smart SDK 技术原理
iOS的Hook技术使用Objective-C提供的Method Swizzling机制。Method Swizzling是Objective-C的运行时技术,指的是改变一个已存在的选择器对应的实现的过程,它依赖于Objectvie-C中方法的调用能够在运行时进行改变——通过改变类的调度表(dispatch table)中选择器到最终函数间的映射关系。
原理图如下:
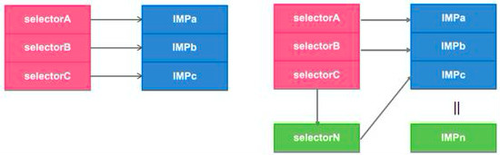
每一个Selector(选择器)对应一个IMP(实现体),通过Method Swizzling可以动态改变这种对应关系。Swizzling通常被程序开发认为是一种巫术,容易导致不可预料的行为和结果。但是如果采取下面这些措施,Method Swizzling还是很安全的:
1、Swizzling应该在+load方法中实现。Objective-C中每个类都有+load和+initialize两个方法。这两个方法会被Objective-C运行时系统自动调用,+load是在一个类最开始加载时调用,+initialize是在应用中第一次调用该类或它的实例的方式之前调用。这两个方法都是可选的,都是只有实现了才会被执行。
因为method swizzling会影响全局,所以减少冒险情况就很重要。+load能够保证在类初始化的时候就会被加载,这为改变系统行为提供了一些统一性。但+initialize并不能保证在什么时候被调用——事实上也有可能永远也不会被调用,例如应用程序从未直接的给该类发送消息。
2、Swizzling应该在dispatch_once中实现。还是因为swizzling会改变全局,我们需要在运行时采取所有可用的防范措施。保障原子性就是一个措施,它确保代码即使在多线程环境下也只会被执行一次。GCD中的diapatch_once就可以提供这些保障。
3、始终调用方法的原始实现。系统提供的 API为输入和输出提供规约,但它里面具体的实现其实是个黑匣子,在Method Swizzling过程中不调用它原始的实现可能会破坏一些私有状态,导致程序运行不稳定。
Android Smart SDK 技术原理
首先来看看Android app的打包流程
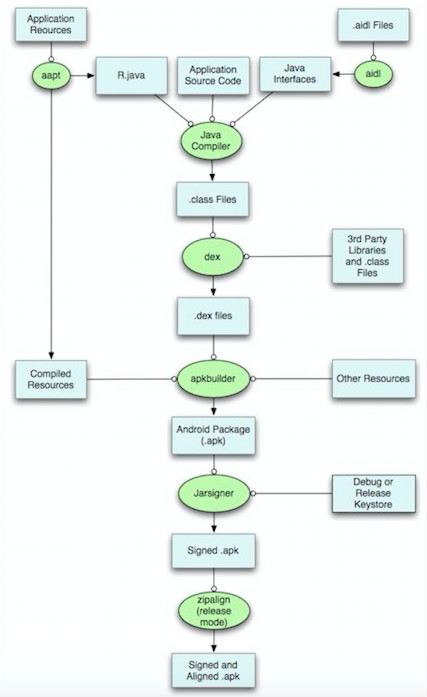
该图翻译成技术语言,如下图
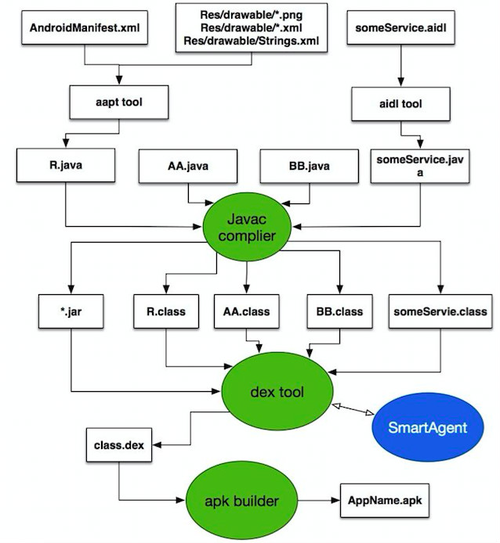
图中标明了sdk中代码的工作位置:就是在 .class文件转化成.dex文件的过程中,通过ASM框架改写代码的。通过对字节码的读写,找到感兴趣的方法,加入收集信息的代码。原生的网络请求、用户行为、页面加载等方面的性能数据,就是以这样的方式收集到的。
透视宝端到端技术方案重点不在移动端,而在于后端。移动端只是针对从APP中发出的每一条网络请求打上标记,后端节点上的Agent接收到该条请求,解析标记,记录下来,并且打上该节点的标记。最终通过这些标记画出该条请求所经过的所有节点的拓扑图,将节点上的应用的性能指标关联起来。
崩溃信息收集和分析
iOS的崩溃信息收集和分析原理
崩溃信息收集,通过系统提供的异常信息捕获接口,设置回调函数,捕获异常信息。通过解析解码文件,将解码文件与崩溃信息里的内存地址结合起来,分析出发生崩溃的位置和代码段
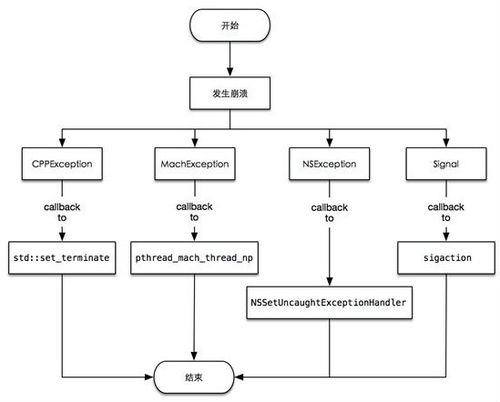
通过设置系统异常信息收集的回调函数到系统相应的接口上,捕获系统的异常信息。
崩溃信息解析过程:1、 从崩溃日志中获取代码行的地址偏移量。(已从前面的崩溃信息中获取到)
1、 解析符号表文件dSYM, 使用dwarfdump命令从dSYM文件中抽取相关信息。比较常用的两个命令:
dwarfdump -e --debug-info YourPath/YourApp.dSYM/Contents/Resources/DWARF > info.txt
dwarfdump -e --debug-line YourPath/YourApp.dSYM/Contents/Resources/DWARF > line.txt
其中,info.txt文件中包含类文件的具体信息,比如类名,方法名,方法的内存起止地址等。如下图所示:

由图中可知,只要偏移量在0x000681c0和0x00068454之间的代码,就对应JKBOverviewVC.m文件的 -[JKBOverviewVC tableView:cellForRowAtIndexPath:]函数。
具体崩溃在该函数的哪一行,通过line.txt文件中的内容得出
line.txt文件中,包含函数中每一行代码的内存地址对应的相关信息,如下图所示
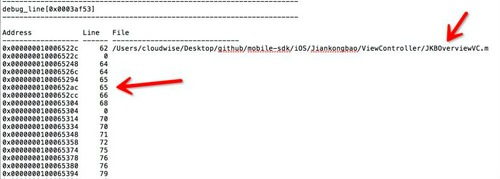
崩溃日志中,偏移量在0x000681c0和0x00068454之间的代码,在这个line.txt文件中就能找到具体的代码行。至此,iOS的崩溃日志就分析完成了。
Android的崩溃收集原理
1. Java层的崩溃信息收集原理,如下图所示:
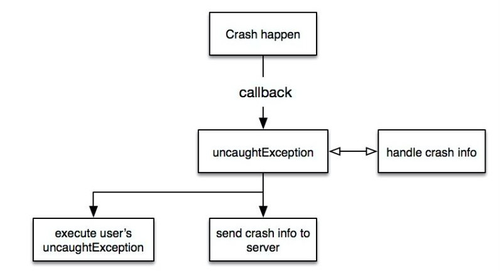
Java 层的堆栈信息收集是通过定义一个Handler类去实现Thread.UncaughtExceptionHandler接口的void uncaughtException(Thread t, Throwable e)方法,然后,通过在Thread.setDefaultUncaughtExceptionHandler方法将我们定义的Handler和APP的线程关联起来。在uncaughtException方法中去收集APP 没有捕获的异常,然后将其堆栈信息收集起来。
2. Native层的崩溃信息收集原理,如下图所示:
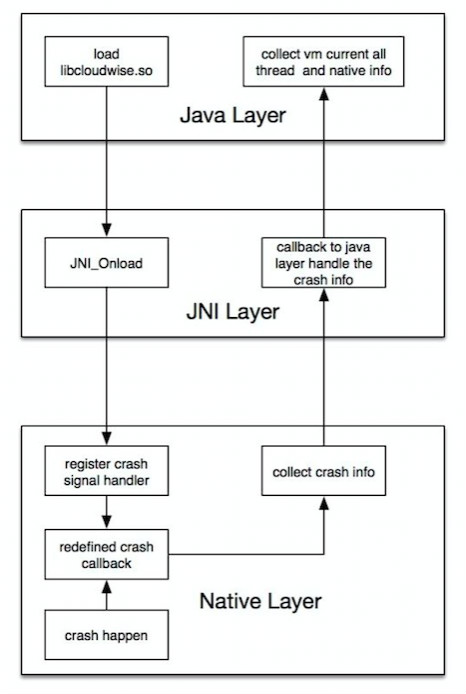
由于Android 底层使用的是linux内核,所以Native层先通过sigaction()函数去注册我们需要监视的Crash相关的信号量,同时,修改相关信号量发生的回调函数,在回调函数中我们通过Android的libcorkscrew.so(5.0版本以下) 和 libunwind.so(5.0及以上版本)提供的打印堆栈函数去收集Native层的堆栈信息,然后通过JNI层回调到Java层,从而收集到native的信息和Java层当前的所有线程信息。
H5页面的性能数据收集方案
H5页面的性能数据采集通过注入js代码来实现的。移动端的H5页面展示过程,主要分为数据请求、数据加载、页面渲染等。而其中数据加载是将H5页面的数据从服务端一段一段的load到移动端,JS代码的注入就是在这个阶段完成的。
在数据load阶段注入js代码,待数据load完成之后渲染,这样做既不会影响客户代码的执行,也能保证JS代码能够监控H5页面的整个生命周期中的用户操作和页面加载情况。
由于移动端操作系统对webkit进行了高度封装,开放出来的API还少,以致不能获取H5页面的详细加载情况,只能借助于JS代码,获取页面的performance参数,从而获取到页面加载的各个性能指标。
Q1:对于react native 是否也能支持?对于原生应用和这种类型的应用支持的程度是否一致?
A:我们目前没有对React Native的应用做过测试。网络请求的支持应该是与原生应用的支持一致的;系统级别的崩溃,支持程度也是一致的;加载H5和用户行为事件的追踪,支持程度应该有限。
以上结论,需要测试确定。假如不支持,我们也将经过迭代,解决该兼容问题。
Q2、H5中注入脚本会影响性能么?
A:JS代码是存在SDK本地的,没有新的网络请求产生,JS代码在H5页面上工作的时候,并不是现场计算,而是直接取得performance的接口;同时修改系统的click事件冒泡取得标签值和url,而不是进行click方法的动态bound,所以工作过程中的性能损耗微乎其微。
Q3、除了UI上带来的用户体检,耗电、网络流量也是用户所关注的。不是埋点式的行为数据收集,产生的数据量是怎么控的?
A:1、耗电量可以通过系统接口获取到 2、网络流量目前有统计,我们的每一条请求都会统计发送字节和接收字节。3、目前行为数据不支持可配置,只要是有事件发生的行为,都会记录。下一步会支持用户行为可配置。接下来我们会支持APP中用户重点关心的用户行为配置,而且这个建模过程会更加清晰简单,只需要操作APP就可以完成这个过程了。
*透视宝移动性能管理体验地址: http://cloudwise.mikecrm.com/J0e2CR
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

