动态追踪技术(中) - Dtrace、SystemTap、火焰图
动态追踪技术中篇,关于 DTrace、SystemTap 和 火焰图的那点事。
DTrace 与 SystemTap
说到动态追踪就不能不提到 DTrace(1) 。DTrace 算是现代动态追踪技术的鼻祖了,它于 21 世纪初诞生于 Solaris 操作系统,是由原来的 Sun Microsystems 公司的工程师编写的。可能很多同学都听说过 Solaris 系统和 Sun 公司的大名。
最初产生的时候,我记得有这样一个故事,当时 Solaris 操作系统的几个工程师花了几天几夜去排查一个看似非常诡异的线上问题。开始他们以为是很高级的问题,就特别卖力,结果折腾了几天,最后发现其实是一个非常愚蠢的、某个不起眼的地方的配置问题。自从那件事情之后,这些工程师就痛定思痛,创造了 DTrace 这样一个非常高级的调试工具,来帮助他们在未来的工作当中避免把过多精力花费在愚蠢问题上面。毕竟大部分所谓的“诡异问题”其实都是低级问题,属于那种“调不出来很郁闷,调出来了更郁闷”的类型。
应该说 DTrace 是一个非常通用的调试平台,它提供了一种很像 C 语言的脚本语言,叫做 D。基于 DTrace 的调试工具都是使用这种语言编写的。D 语言支持特殊的语法用以指定“探针”,这个“探针”通常有一个位置描述的信息。你可以把它定位在某个内核函数的入口或出口,抑或是某个用户态进程的 函数入口或出口,甚至是任意一条程序语句或机器指令上面。编写 D 语言的调试程序是需要对系统有一定的了解和知识的。这些调试程序是我们重拾对复杂系统的洞察力的利器。Sun 公司有一位工程师叫做 Brendan Gregg,他是最初的 DTrace 的用户,甚至早于 DTrace 被开源出来。Brendan 编写了很多可以复用的基于 DTrace 的调试工具,一齐放在一个叫做 DTrace Toolkit(2) 的开源项目中。Dtrace 是最早的动态追踪框架,也是最有名的一个。
DTrace 的优势是它采取了跟操作系统内核紧密集成的一种方式。D 语言的实现其实是一个虚拟机(VM),有点像 Java 虚拟机(JVM)。它的一个好处在于 D 语言的运行时是常驻内核的,而且非常小巧,所以每个调试工具的启动时间和退出时间都很短。但是我觉得 DTrace 也是有明显缺点的。其中一个让我很难受的缺点是 D 语言缺乏循环结构,这导致许多针对目标进程中的复杂数据结构的分析工具很难编写。虽然 DTrace 官方声称缺少循环的原因是为了避免过热的循环,但显然 DTrace 是可以在 VM 级别上面有效限制每一个循环的执行次数的。另外一个较大的缺点是,DTrace 对于用户态代码的追踪支持比较弱,没有自动的加载用户态调试符号的功能,需要自己在 D 语言里面声明用到的用户态 C 语言结构体之类的类型。
DTrace 的影响是非常大的,很多工程师把它移植到其他的操作系统。比方说苹果的 Mac OS X 操作系统上就有 DTrace 的移植。其实近些年发布的每一台苹果笔记本或者台式机上面,都有现成的 dtrace 命令行工具可以调用,大家可以去在苹果机器的命令行终端上尝试一下。这是苹果系统上面的一个 DTrace 的移植。FreeBSD 操作系统也有这样一个 DTrace 的移植。只不过它并不是默认启用的。你需要通过命令去加载 FreeBSD 的 DTrace 内核模块。Oracle 也有在它自己的 Oracle Linux 操作系统发行版当中开始针对 Linux 内核进行 DTrace 移植。不过 Oracle 的移植工作好像一直没有多少起色,毕竟 Linux 内核并不是 Oracle 控制的,而 DTrace 是需要和操作系统内核紧密集成的。出于类似的原因,民间一些勇敢的工程师尝试的 DTrace 的 Linux 移植也一直距离生产级别的要求很远。
相比 Solaris 上面原生的 DTrace,这些 DTrace 移植都或多或少的缺乏某些高级特性,所以从能力上来说,还不及最本初的 DTrace。
DTrace 对 Linux 操作系统的另一个影响反映在 SystemTap(3) 这个开源项目。这是由 Red Hat 公司的工程师创建的较为独立的动态追踪框架。SystemTap 提供了自己的一种 小语言(4) ,和 D 语言并不相同。显然,Red Hat 自己服务于非常多的企业级用户,他们的工程师每天需要处理的各种线上的“诡异问题”自然也是极多的。这种技术的产生必然是现实需求激发的。我觉得 SystemTap 是目前 Linux 世界功能最强大,同时也是最实用的动态追踪框架。我在自己的工作当中已经成功使用多年。SystemTap 的作者 Frank Ch. Eigler 和 Josh Stone 等人,都是非常热情、同时非常聪明的工程师。我在 IRC 或者邮件列表里的提问,他们一般都会非常快且非常详尽地进行解答。值得一提的是,我也曾给 SystemTap 贡献过一个较为重要的新特性,使其能在任意的探针上下文中访问用户态的全局变量的取值。我当时合并到 SystemTap 主线的这个 C++ 补丁(5) 的规模达到了约一千行,多亏了 SystemTap 作者们的热心帮助。这个新特性在我基于 SystemTap 实现的动态脚本语言(比如 Perl 和 Lua)的 火焰图(6) 工具中扮演了关键角色。
SystemTap 的优点是它有非常成熟的用户态调试符号的自动加载,同时也有循环这样的语言结构可以去编写比较复杂的探针处理程序,可以支持很多很复杂的分析处理。由于 SystemTap 早些年在实现上的不成熟,导致互联网上充斥着很多针对它的已经过时了的诟病和批评。最近几年 SystemTap 已然有了长足的进步。
当然,SystemTap 也是有缺点的。首先,它并不是 Linux 内核的一部分,就是说它并没有与内核紧密集成,所以它需要一直不停地追赶主线内核的变化。另一个缺点是,它通常是把它的“小语言”脚本(有点像 D 语言哦)动态编译成一个 Linux 内核模块的 C 源码,因此经常需要在线部署 C 编译器工具链和 Linux 内核的头文件,同时需要动态地加载这些编译出来的内核模块,以运行我们的调试逻辑。在我们的调试工具运行完毕之后,又存在动态卸载 Linux 内核模块的问题。出于这些原因,SystemTap 脚本的启动相比 DTrace 要慢得多,和 JVM 的启动时间倒有几分类似。虽然存在这些缺点,但总的来说,SystemTap 还是一个非常成熟的动态追踪框架。
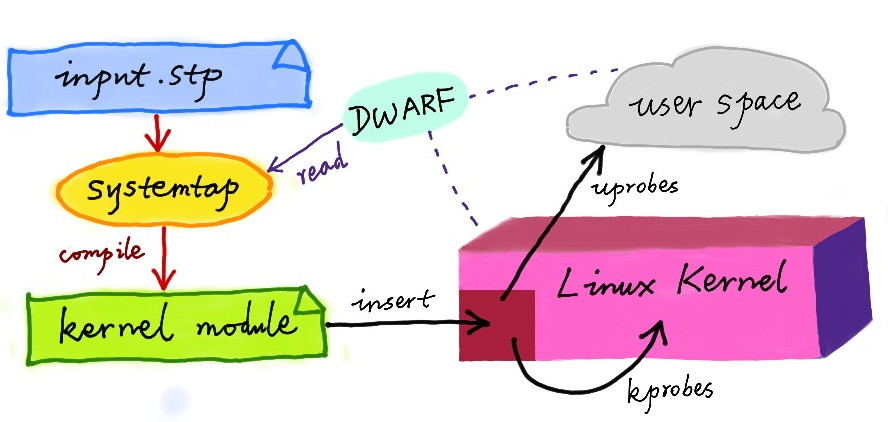
Systemtap 工作原理图
无论是 DTrace 还是 SystemTap,其实都不支持编写完整的调试工具,因为它们都缺少方便的命令行交互的原语。所以我们才看到现实世界中许多基于它们的工具,其实最外面都有一个 Perl、Python 或者 Shell 脚本编写的包裹。为了便于使用一种干净的语言编写完整的调试工具,我曾经给 SystemTap 语言进行了扩展,实现了一个更高层的“宏语言”,叫做 stap++(7) 。我自己用 Perl 实现的 stap++ 解释器可以直接解释执行 stap++ 源码,并在内部调用 SystemTap 命令行工具。有兴趣的朋友可以查看我开源在 GitHub 上面的 stapxx 这个代码仓库。这个仓库里面也包含了很多直接使用我的 stap++ 宏语言实现的完整的调试工具。
SystemTap 在生产上的应用
DTrace 有今天这么大的影响离不开著名的 DTrace 布道士 Brendan Gregg(8) 老师。前面我们也提到了他的名字。他最初是在 Sun Microsystems 公司,工作在 Solaris 的文件系统优化团队,是最早的 DTrace 用户。他写过好几本有关 DTrace 和性能优化方面的书,也写过很多动态追踪方面的博客文章。
2011 年我离开淘宝以后,曾经在福州过了一年所谓的“田园生活”。在田园生活的最后几个月当中,我通过 Brendan 的 公开博客(9) 较为系统地学习了 DTrace 和动态追踪技术。其实最早听说 DTrace 是因为一位微博好友的评论,他只提到了 DTrace 这个名字。于是我便想了解一下这究竟是什么东西。谁知,不了解不知道,一了解吓一跳。这竟然是一个全新的世界,彻底改变了我对整个计算世界的看法。于是我就花了非常多的时间,一篇一篇地仔细精读 Brendan 的个人博客。后来终于有一天,我有了一种大彻大悟的感觉,终于可以融会贯通,掌握到了动态追踪技术的精妙。
2012 年我结束了在福州的“田园生活”,来到美国加入目前这家 CDN 公司。然后我就立即开始着手把 SystemTap 以及我已领悟到的动态追踪的一整套方法,应用到这家 CDN 公司的全球网络当中去,用于解决那些非常诡异非常奇怪的线上问题。我在这家公司观察到其实很多工程师在排查线上问题的时候,经常会自己在软件系统里面埋点。这主要是在业务代码里,乃至于像 Nginx 这样的系统软件的代码基(code base)里,自己去做修改,添加一些计数器,或者去埋下一些记录日志的点。通过这种方式,大量的日志会在线上被实时地采集起来,进入专门的数据库,然后再进行离线分析。显然这种做法的成本是巨大的,不仅涉及业务系统本身的修改和维护成本的陡然提高,而且全量采集和存储大量的埋点信息的在线开销,也是非常可观的。而且经常出现的情况是,张三今天在业务代码里面埋了一个采集点,李四明天又埋下另一个相似的点,事后可能这些点又都被遗忘在了代码基里面,而没有人再去理会。最后这种点会越来越多,把代码基搞得越来越凌乱。这种侵入式的修改,会导致相应的软件,无论是系统软件还是业务代码,变得越来越难以维护。
埋点的方式主要存在两大问题,一个是“太多”的问题,一个是“太少”的问题。“太多”是指我们往往会采集一些根本不需要的信息,只是一时贪多贪全,从而造成不必要的采集和存储开销。很多时候我们通过采样就能进行分析的问题,可能会习惯性的进行全网全量的采集,这种代价累积起来显然是非常昂贵的。那“太少”的问题是指,我们往往很难在一开始就规划好所需的所有信息采集点,毕竟没有人是先知,可以预知未来需要排查的问题。所以当我们遇到新问题时,现有的采集点搜集到的信息几乎总是不够用的。这就导致频繁地修改软件系统,频繁地进行上线操作,大大增加了开发工程师和运维工程师的工作量,同时增加了线上发生更大故障的风险。
另外一种暴力调试的做法也是我们某些运维工程师经常采用的,即把机器拉下线,然后设置一系列临时的防火墙规则,以屏蔽用户流量或者自己的监控流量,然后在生产机上各种折腾。这是很繁琐影响很大的过程。首先它会让机器不能再继续服务,降低了整个在线系统的总的吞吐能力。同时有些只有真实流量才能复现的问题,此时再也无法复现了。可以想象这些粗暴的做法有多么让人头疼。
实际上运用 SystemTap 动态追踪技术可以很好地解决这样的问题,有“润物细无声”之妙。首先我们不需要去修改我们的软件栈(software stack)本身,不管是系统软件还是业务软件。我经常会编写一些有针对性的工具,然后在一些关键的系统「穴位」上面放置一些经过仔细安排的探针。这些探针会采集各自的信息,同时调试工具会把这些信息汇总起来输出到终端。用这种方式我可以在某一台机器或某几台机器上面,通过采样的方式,很快地得到我想要的关键信息,从而快速地回答一些非常基本的问题,给后续的调试工作指明方向。
正如我前面提到的,与其在生产系统里面人工去埋点去记日志,再搜集日志入库,还不如把整个生产系统本身看成是一个可以直接查询的“数据库”,我们直接从这个“数据库”里安全快捷地得到我们想要的信息,而且绝不留痕迹,绝不去采集我们不需要的信息。利用这种思想,我编写了很多调试工具,绝大部分已经开源在了 GitHub 上面,很多是针对像 Nginx、LuaJIT 和操作系统内核这样的系统软件,也有一些是针对更高层面的像 OpenResty 这样的 Web 框架。有兴趣的朋友可以查看 GitHub 上面的 nginx-systemtap-toolkit(10) 、 perl-systemtap-toolkit(11) 和 stappxx(12) 这几个代码仓库。
 我的 SystemTap 工具云
我的 SystemTap 工具云
利用这些工具,我成功地定位了数不清的线上问题,有些问题甚至是我意外发现的。下面就随便举几个例子吧。
第一个例子是,我使用基于 SystemTap 的火焰图工具分析我们线上的 Nginx 进程,结果发现有相当一部分 CPU 时间花费在了一条非常奇怪的代码路径上面。这其实是我一位同事在很久之前调试一个老问题时遗留下来的临时的调试代码,有点儿像我们前面提到的“埋点代码”。结果它就这样被遗忘在了线上,遗忘在了公司代码仓库里,虽然当时那个问题其实早已解决。由于这个代价高昂的“埋点代码”一直没有去除,所以一直都产生着较大的性能损耗,而一直都没有人注意到。所以可谓是我意外的发现。当时我就是通过采样的方式,让工具自动绘制出一张火焰图。我一看这张图就可以发现问题并能采取措施。这是非常非常有效的方式。
第二个例子是,很少量的请求存在延时较长的问题,即所谓的“长尾请求”。这些请求数目很低,但可能达到「秒级」这样的延时。当时有同事乱猜说是我的 OpenResty 有 bug,我不服气,于是立即编写了一个 SystemTap 工具去在线进行采样,对那些超过一秒总延时的请求进行分析。该工具会直接测试这些问题请求内部的时间分布,包括请求处理过程中各个典型 I/O 操作的延时以及纯 CPU 计算延时。结果很快定位到是 OpenResty 在访问 Go 编写的 DNS 服务器时,出现延时缓慢。然后我再让我的工具输出这些长尾 DNS 查询的具体内容,发现都是涉及 CNAME 展开。显然,这与OpenResty 无关了,而进一步的排查和优化也有了明确的方向。
第三个例子是,我们曾注意到某一个机房的机器存在比例明显高于其他机房的网络超时的问题,但也只有 1% 的比例。一开始我们很自然的去怀疑网络协议栈方面的细节。但后来我通过一系列专门的 SystemTap 工具直接分析那些超时请求的内部细节,便定位到了是硬盘 配置方面的问题。从网络到硬盘,这种调试是非常有趣的。第一手的数据让我们快速走上正确的轨道。
还有一个例子是,我们曾经通过火焰图在 Nginx 进程里观察到文件的打开和关闭操作占用了较多的 CPU 时间,于是我们很自然地启用了 Nginx 自身的文件句柄缓存配置,但是优化效果并不明显。于是再做出一张新的火焰图,便发现因为这回轮到 Nginx 的文件句柄缓存的元数据所使用的“自旋锁”占用很多 CPU 时间了。这是因为我们虽然启用了缓存,但把缓存的大小设置得过大,所以导致元数据的自旋锁的开销抵消掉了缓存带来的好处。这一切都能在火焰图上面一目了然地看出来。假设我们没有火焰图,而只是盲目地试验,很可能会得出 Nginx 的文件句柄缓存没用的错误结论,而不会去想到去调整缓存的参数。
最后一个例子是,我们在某一次上线操作之后,在线上最新的火焰图中观察到正则表达式的编译操作占用了很多 CPU 时间,但其实我们已经在线上启用了正则编译结果的缓存。很显然,我们业务系统中用到的正则表达式的数量,已然超出了我们最初设置的缓存大小,于是很自然地想到把线上的正则缓存调的更大一些。然后,我们在线上的火焰图中便再看不到正则编译操作了。
通过这些例子我们其实可以看到,不同的数据中心,不同的机器,乃至同一台机器的不同时段,都会产生自己特有的一些新问题。我们需要的是直接对问题本身进行分析,进行采样,而不是胡乱去猜测去试错。有了强大的工具,排错其实是一个事半功倍的事情。
火焰图
前面我们已经多次提到了 火焰图 (Flame Graph)这种东西,那么火焰图是什么呢?它其实是一个非常了不起的可视化方法,是由前面已经反复提到的 Brendan Gregg 同学发明的。
火焰图就像是给一个软件系统拍的 X 光照片,可以很自然地把时间和空间两个维度上的信息融合在一张图上,以非常直观的形式展现出来,从而反映系统在性能方面的很多定量的统计规律。
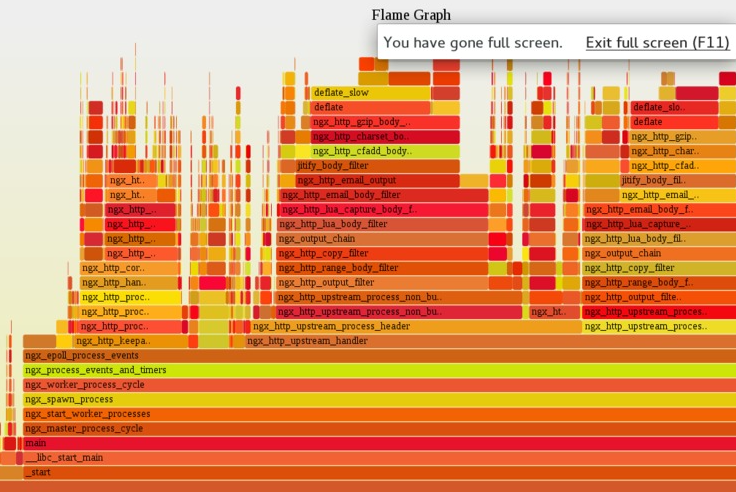 Nginx 的 C 级别 on-CPU 火焰图示例
Nginx 的 C 级别 on-CPU 火焰图示例
比方说,最经典的火焰图是统计某一个软件的所有代码路径在 CPU 上面的时间分布。通过这张分布图我们就可以直观地看出哪些代码路径花费的 CPU 时间较多,而哪些则是无关紧要的。进一步地,我们可以在不同的软件层面上生成火焰图,比如说可以在系统软件的 C/C++ 语言层面上画出一张图,然后再在更高的——比如说——动态脚本语言的层面,例如 Lua 和 Perl 代码的层面,画出火焰图。不同层面的火焰图常常会提供不同的视角,从而反映出不同层面上的代码热点。
因为我自己维护着 OpenResty 这样的开源软件的社区,我们有自己的邮件列表,我经常会鼓励报告问题的用户主动提供自己绘制的火焰图,这样我们就可以惬意地 看图说话(13) ,帮助用户快速地进行性能问题的定位,而不至于反复地试错,和用户一起去胡乱猜测,从而节约彼此大量的时间,皆大欢喜。
这里值得注意的是,即使是遇到我们并不了解的陌生程序,通过看火焰图,也可以大致推出性能问题的所在,即使从未阅读过它的一行源码。这是一件非常了不起的事情。因为大部分程序其实是编写良好的,也就是说它往往在软件构造的时候就使用了抽象层次,比如通过函数。这些函数的名称通常会包含语义上的信息,并在火焰图上面直接显示出来。通过这些函数名,我们可以大致推测出对应的函数,乃至对应的某一条代码路径,大致是做什么事情的,从而推断出这个程序所存在的性能问题。所以,又回到那句老话,程序代码中的命名非常重要,不仅有助于阅读源码,也有助于调试问题。而反过来,火焰图也为我们提供了一条学习陌生的软件系统的捷径。毕竟重要的代码路径,几乎总是花费时间较多的那些,所以值得我们重点研究;否则的话,这个软件的构造方式必然存在很大的问题。
火焰图其实可以拓展到其他维度,比如刚才我们讲的火焰图是看程序运行在 CPU 上的时间在所有代码路径上的分布,这是 on-CPU 时间这个维度。类似地,某一个进程不运行在任何 CPU 上的时间其实也是非常有趣的,我们称之为 off-CPU 时间。off-CPU 时间一般是这个进程因为某种原因处于休眠状态,比如说在等待某一个系统级别的锁,或者被一个非常繁忙的进程调度器(scheduler)强行剥夺 CPU 时间片。这些情况都会导致这个进程无法运行在 CPU 上,但是仍然花费很多的挂钟时间。通过这个维度的火焰图我们可以得到另一幅很不一样的图景。通过这个维度上的信息,我们可以分析系统锁方面的开销(比如 sem_wait 这样的系统调用),某些阻塞的 I/O 操作(例如 open 、 read 之类),还可以分析进程或线程之间争用 CPU 的问题。通过 off-CPU 火焰图,都一目了然。
应该说 off-CPU 火焰图也算是我自己的一个大胆尝试。记得最初我在加州和内华达州之间的一个叫做 Tahoe 的湖泊边,阅读 Brendan 关于 off-CPU 时间的 一篇博客文章(14) 。我当然就想到,或许可以把 off-CPU 时间代替 on-CPU 时间应用到火焰图这种展现方式上去。于是回来后我就在公司的生产系统中做了这样一个尝试,使用 SystemTap 绘制出了 Nginx 进程的 off-CPU 火焰图。我在推特上公布了这个成功尝试之后,Brendan 还专门联系到我,说他自己之前也尝试过这种方式,但效果并不理想。我估计这是因为他当时将之应用于多线程的程序,比如 MySQL,而多线程的程序因为线程同步方面的原因,off-CPU 图上会有很多噪音,容易掩盖真正有趣的那些部分。而我应用 off-CPU 火焰图的场景是像 Nginx 这样的单线程程序,所以 off-CPU 火焰图里往往会立即指示出那些阻塞 Nginx 事件循环的系统调用,抑或是 sem_wait 之类的锁操作,又或者是抢占式的进程调度器的强行介入,于是可以非常好地帮助分析一大类的性能问题。在这样的 off-CPU 火焰图中,唯一的“噪音”其实就是 Nginx 事件循环本身的 epoll_wait 这样的系统调用,很容易识别并忽略掉。
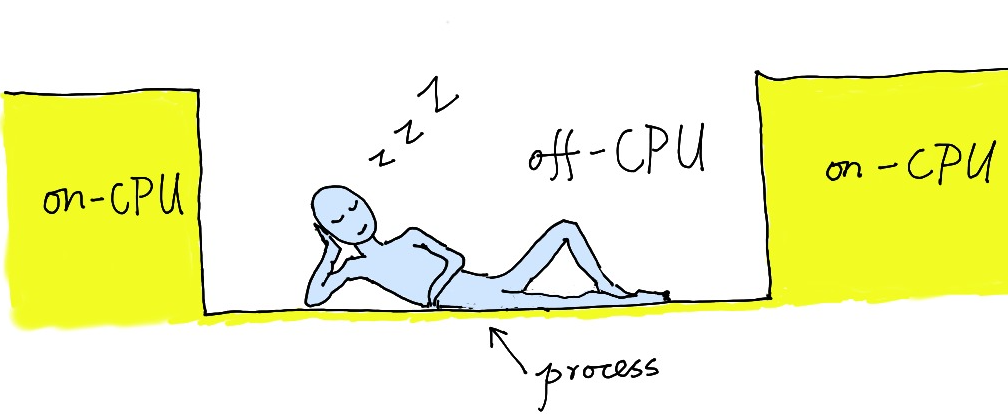 off-CPU 时间
off-CPU 时间
类似地,我们可以把火焰图拓展到其他的系统指标维度,比如内存泄漏的字节数。有一回我就使用“内存泄漏火焰图”快速定位了 Nginx 核心中的一处很微妙的泄漏问题。由于该泄漏发生在 Nginx 自己的内存池中,所以使用 Valgrind(15) 和 AddressSanitizer(16) 这样的传统工具是无法捕捉到的。还有一次也是使用“内存泄漏火焰图”轻松定位了一位欧洲开发者自己编写的 Nginx C 模块中的泄漏。那处泄漏非常细微和缓慢,困挠了他很久,而我帮他定位前都不需要阅读他的源代码。细想起来我自己都会觉得有些神奇。当然,我们也可以将火焰图拓展到文件 I/O 的延时和数据量等其他系统指标。所以这真是一种了不起的可视化方法,可以用于很多完全不同的问题类别。
待续。
参考链接:
DTrace(1): http://dtrace.org/blogs/about/
DTrace Toolkit(2): http://www.brendangregg.com/dtracetoolkit.html
SystemTap(3) https://sourceware.org/systemtap/
小语言(4): https://sourceware.org/systemtap/langref/
C++ 补丁(5): https://sourceware.org/ml/systemtap/2013-q2/msg00377.html
火焰图(6): http://www.brendangregg.com/flamegraphs.html
stap++(7): https://github.com/openresty/stapxx
Brendan Gregg(8): http://www.brendangregg.com/
公开博客(9): http://www.brendangregg.com/blog/
nginx-systemtap-toolkit(10): https://github.com/openresty/nginx-systemtap-toolkit
perl-systemtap-toolkit(11): https://github.com/agentzh/perl-systemtap-toolkit
stappxx(12): https://github.com/openresty/stapxx
看图说话(13): https://groups.google.com/d/msg/openresty/psPBSG4KcSU/Ur9VjTvKBAAJ
一篇博客文章(14): http://www.brendangregg.com/offcpuanalysis.html
Valgrind(15): http://valgrind.org/
AddressSanitizer(16):
https://github.com/google/sanitizers/wiki/AddressSanitizer
参与攻城狮群活动,请关注 MacTalk 后 , 点击自定义菜单「攻城狮群」。

正文到此结束
- 本文标签: 苹果 http 云 测试 噪音 sql 多线程 HTML 性能问题 统计 mysql 协议 安全 开源项目 App 锁 src 正则表达式 编译 CDN 互联网 数据 空间 开发 企业 调度器 linux 服务器 DNS 进程 调试 时间 操作系统 OpenResty 文章 Nginx https 线程 开源软件 需求 同步 python 探针 git 美国 开发者 代码 参数 微博 ACE web shell 数据库 UI GitHub REST 开源 博客 java 源码 Oracle 配置 Google 软件
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

