PitGen:帮你利用010Editor的模板生成对应的Peach PIT
FreeBuf百科:文件Fuzz背景知识
不管是IE还是Office,它们都有一个共同点,那就是用文件作为程序的主要输入。不少程序员会存在惯性思维,即假设他们所使用的文件是严格遵守软件规定的数据格式。但是攻击者往往会挑战程序员的假定假设,尝试对软件所约定的数据格式进行稍微修改,观察软件是否在解析这种“畸形文件”时是否会发生崩溃或者溢出。
文件格式Fuzz(File Fuzz)就是这种利用“畸形文件”测试软件鲁棒性的方法。
—— 《漫谈漏洞挖掘之文件解析型漏洞》 / dragonltx
PIT 前段时间出了一个可以解析 010Editor 模板的 Python 工具—— PFP 。该工具可以对照 010Editor 的模板解析目标文件,将一个文件的输入流解析到对应的数据结构上。
其解析的流程是:
调用 CPP 将 010Editor 的模板文件正则化,然后再基于语法来对其进行解析。
解析逻辑比较复杂,我也没看进去。不过基本的数据结构还是应该了解的。文件格式是由一个个字段组成的,这些字段的类型称为 Field ,继承于 Python 里的 object 对象。 Field 作为基类又派生出若干种类型,如 :
Struct ,结构体类型
Enum ,枚举类型
Union ,联合类型
Array ,数组类型
NumberBase ,数值的基类
IntBase ,整数的基本
UInt , 32 位整数
USort , 16 位整数
Char ,字符
……
这些类型覆盖了 C 语言中的大多类型,也足以解析 010Editor 模板。了解了这些类型后,就可以根据这些类型来进行分析样本的格式了。
在博客里,作者也提到了,可以利用这个工具来进行智能 Fuzzing ,由于文件格式已经解析到脚本中了,可以指定对某个字段进行修改变异,的确能达到 Fuzzing 的效果。但是测试一个或者几个小点的字段还可以,如果要做到通用性和规模化,则还需要进一步开发。
什么是Peach
Peach 是一款自动化的智能 Fuzzing 工具,它根据用户提供的 PIT 文件来对样本进行解析,然后再对各个字段进行变异测试。用户制定的 PIT 文件直接关系到整个 Fuzzing 过程的效率,然而写一个 PIT 文件确是比较费力的,除了需要分析格式外,还需要做很多烦琐的工作。
以前在根据 010Editor 写 PIT 的时候,总想着如果有个工具可以将 010Editor 的模板直接转换成 PIT 的话,可以节省很大的工作量。类似的工作有 NetZob ,可以将 PCAP 转化成简单的 PIT 文件。
现在既然别人提供了解析 010Editor 模板的功能,那么,将 010Editor 模板转换成 PIT 也就不再那么困难了。
完成如下这个工具需要如下几步工作:
1 )将样本文件使用 010Editor 的模板进行解析,这步工作已经被 PFP 完成了。
2) 将解析的结果进行遍历,根据不同的类型,生成对应的 PIT 语法格式。这步需要我们自己来完成。
花了一天时间,熟悉了下 PFP 的代码,并且初步实现了这个小工具,可以把指定的样本格式根据 010Editor 模板转化成 PeachPIT 文件。以下是我的实现流程。
( 1 )调用 PFP 的接口,将样本文件与 010Editor 模板文件作为输入,对样本进行格式解析,将返回到一个 DOM 对象中。
dom = pfp.parse(data_file=src,template_file=template)
( 2 )对 dom 对象进行遍历,其实它就是一个树状结构,如下图所示。根结点下面包括若干结点,这些节点可能是叶子结点,也可能是包含节点,这些包含结点又包括若干节点,造成嵌套的类型可能是 struct,union,array,string 等类型。
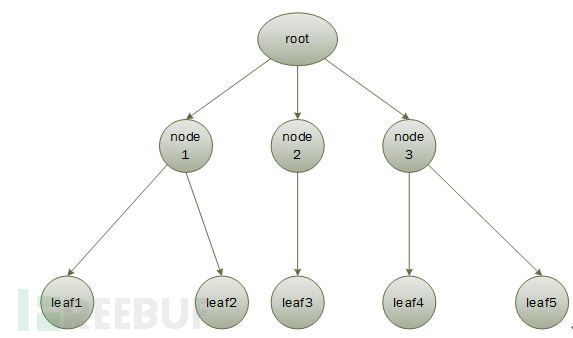
对树的遍历也很简单,使用递归算法即可完成,代码如下:
defParseDom(Depth, Elem):
try:
name =""
if isinstance(Elem, pfp.fields.Char):
return;
if Elem._pfp__name is not None:
name = Elem._pfp__name
else:
name = "CHUNK"
print "++"*Depth + name
if hasChildren(Elem):
[ParseDom(Depth+1, child) for childin Elem._pfp__children]
if isArray(Elem):
[ParseDom(Depth+1, e) for e inElem]
except Exception, e:
print "*********"
print Elem
print "*********"
pass
( 3 )在遍历过程中,根据节点对应的不同类型,按照 PeachPit 语法生成对应的 Pit 语句。
目前,支持 Union,Struct,Array, 各种大小的整型 ,String,Enum 等类型的转换。转换函数也很简单,以 String 类型为例,
def PrintStringPit(name, length =0, value=None):
if value is None or len(value) >PRINT_STRING_LIMIT :
return '<String name="%s"length="%d"/>' % (name, length)
if not isAsciiStr(value):
return '<String name="%s"length="%d"/>' % (name, length)
return'<String name="%s" length="%d"value="%s"/>' % (name, length, value)
( 4 )对整个文件格式语法树进行遍历转换后,即可很成对应的 PIT 数据模型了,再加上 Peach 头部即可。
<?xmlversion="1.0" encoding="utf-8"?>
<Peachversion="1.0" author="MJX" >
<DataModel name="PNG">
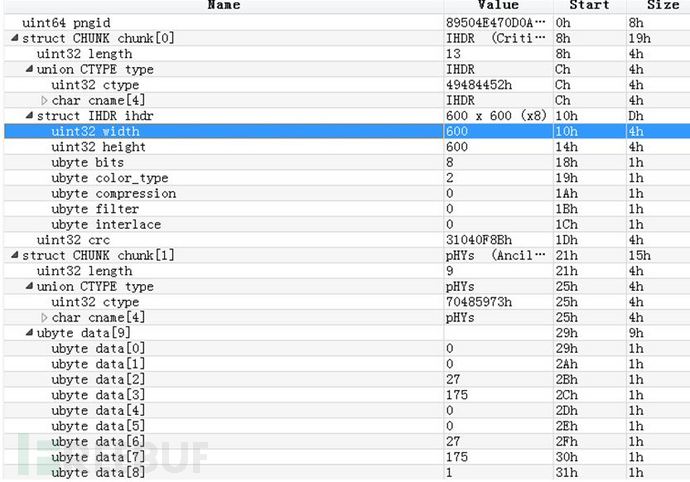
以 PNG 为例,使用该工具进行转换, PNG 被 010Editor 解析如下:
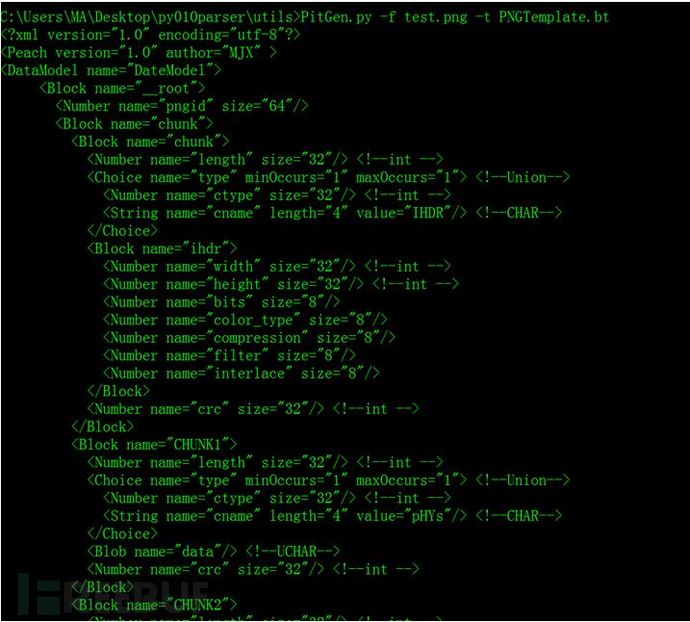
使用该工具转换后的结果如下:
讨论
经过转化后,一个比较粗糙的 PIT 文件就生成了,这个 PIT 文件可以使用 PeachValidator 直接打开,证明 PIT 文件的语法没有问题。
使用这个工具,最大的便利就是不用再重复地人工将类型转换成 PIT 语法写进去,可以提高 PIT 的编写效率,对于一些简单的格式,转换后直接就可以测试了。
但是该工具目前还需要有很多改进的地方:
1 )格式转换的程度还不完善,如缺少对约束条件的添加,如 sizeof , CRC 等条件,目前还需要人工根据条件进行添加。
改进方法:对 010Editor 模板的语法分析,提取出其中的约束,然后自动转换到 Pit 中去,但实现难度较大,必要的人工介入是必须的。
2 )目前的思路是根据一个具体样本的解析方式转换成 Pit ,如果样本选取的不好的话,可能会造成某些格式的缺失。
改进方法:还是对对 010Editor 模板的语法分析,至少可以覆盖 010Editor 可支持的所有格式,这个实现难度中等。
3 )现在完全依赖 PFP 的解析结果,但是据测试, PFP 在解析有些模板时也会报错,所有还有待改进。有兴趣的朋友可以参与到这个 project 里来,一起改 Bug 也是蛮有意思的。
相对 PIT 文件的编写来说,类 C 语法的 010Editor 模板写起来则容易一些,该工具可将 010 模板转换成 PIT 文件,可缩减 PIT 文件的编写时间,避免重复造轮,具有一定的实际意义。
工具还未完全完成,源码位于 https://github.com/majinxin2003/PitGen ,若有感兴趣的朋友,欢迎一起来 hacking 。
20 分钟写的文字,请体谅表达不当的地方。“ 我们不生产代码,我们只做代码的搬运工 ” ….
References
010Editor: http://www.sweetscape.com/010editor/
pycParser: https://github.com/eliben/pycparser
py010parser: https://github.com/d0c-s4vage/py010parser
pfp: https://github.com/d0c-s4vage/pfp/
peach: http://peachfuzzer.com/
*本文作者:CNNVD,转载须注明来自FreeBuf黑客与极客(FreeBuf.COM)
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

